Dieser Artikel ist der inhaltliche Nachfolger meiner letzten Serie (Teile 1 und 2) zum Einsatz von ClickHouse mit aus BigQuery replizierten Daten, um Abfragekosten zu senken. Der zentrale Mechanismus, um den es hier geht, war zum Zeitpunkt der damaligen Serie noch nicht angekündigt; seit der GA-Veröffentlichung Anfang dieses Jahres ist er jedoch zur besseren Methode für die Datenreplikation geworden.
Im Mittelpunkt steht ein Feature namens Continuous Queries. Im Kern handelt es sich um eine endlos laufende Abfrage, die Ergebnisse zurückgibt, sobald Daten in BigQuery-Tabellen geladen oder dort aktualisiert werden. Wer aus der Welt der relationalen Datenbanken kommt, kennt das Prinzip: Es ist im Grunde eine abgespeckte Variante des Change Data Capture (CDC), das die meisten klassischen relationalen Datenbanken bieten.
Ohne lange Vorrede steigen wir ins Thema ein. Zunächst ein kurzer Überblick über das Setup:
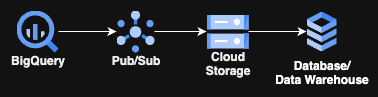
Ja – weder Cloud Run noch GKE oder andere Compute-Komponenten kommen zum Einsatz. Nur drei GCP-Managed Services und eine Speicheroption Ihrer Wahl für die letzte Stufe. Das Beste daran: Der einzige Code, den Sie schreiben müssen, sind ein paar Zeilen SQL!
Legen wir los!
Bevor Sie beginnen
Die einzige echte Voraussetzung: Sie brauchen die passenden IAM-Berechtigungen, um Reservierungen anzulegen und Abfragen in Ihrem Projekt auszuführen. Owner oder Editor reichen problemlos, auch BigQuery Admin deckt alles Nötige ab. Die übrigen "BigQuery * Admin"-Rollen außer der Hauptrolle gewähren dafür nicht genügend Rechte.
Der Workflow
Der Ablauf ist kaum komplizierter als das oben gezeigte Diagramm. Eine kontinuierlich laufende Abfrage (passenderweise Continuous Query genannt) in BigQuery speist Daten in ein Pub/Sub-Topic, das diese wiederum über zugeordnete Pub/Sub-Subscription(s) in einen GCS-Bucket schiebt. Anschließend nimmt ein ETL-/ELT-Prozess die Daten auf und befördert sie an ihren endgültigen oder transformierenden Bestimmungsort.
Preise
Ich dämpfe die Erwartungen lieber im Vorfeld, bevor es um Implementierungsdetails geht – schließlich liebt jeder neues Spielzeug, bis er das Preisschild sieht.
Mehrere Komponenten verursachen hier Kosten:
- BigQuery-Kosten
- Pub/Sub-Kosten
- GCS-Kosten
- Egress-Kosten (ggf.)
Ich erläutere, was Sie bei jedem Punkt erwartet, und nenne die zum Zeitpunkt des Schreibens gültigen Preise – damit niemand von einer unerwarteten Rechnung überrascht wird.
- BigQuery-Kosten
Bei BigQuery tragen viele Komponenten zu den Kosten bei, doch für diesen Prozess müssen wir uns nur um eine kümmern: die Compute-Kosten der Continuous Query über eine BigQuery Editions-Reservierung.
Continuous Queries setzen eine Enterprise- oder Enterprise-Plus-Reservierung voraus, die Teil des kapazitätsbasierten Abrechnungsmodells ist. Beachten Sie: Sie können das On-Demand-Modell (also "5 oder 6,25 USD pro gescannter TiB") für Continuous Queries NICHT verwenden. Wenn Sie aktuell nur das On-Demand-Modell nutzen, müssen Sie deshalb eventuell ein separates Projekt anlegen und es einer Reservierung zuweisen, um die Continuous Query von dort auszuführen. Ich empfehle DRINGEND, vorher meinen ursprünglichen Artikel zu BigQuery Editions hier zu lesen, bevor Sie das organisationsweit einschalten. Editions blind zu aktivieren kann sehr teuer werden.
Continuous Queries verbrauchen laut Google immer mindestens einen Slot, was während der Laufzeit auf eine Mindest- oder "Baseline"-Zuweisung von 50 Slots hinausläuft. Daher empfiehlt es sich, eine Reservierung anzulegen, die Baseline auf 50 zu setzen und die maximalen Slots an Ihre Abfrage anzupassen. Für einfache Tests reichen 50 Slots als Baseline und Maximum völlig aus. Vergessen Sie nur nicht, das Assignment zu löschen oder die Baseline auf null zu setzen, wenn die Abfrage nicht läuft – das spart Kosten.
Die Sätze pro Slot/Stunde unterscheiden sich nach Region und Edition; werfen Sie am besten einen Blick in die offizielle Preistabelle hier.
- Pub/Sub-Kosten
Pub/Sub verursacht in diesem Beispiel nur einen einzigen Kostenpunkt: den Cloud Storage Subscription Throughput-Preis, dokumentiert hier.
Zum Zeitpunkt des Schreibens beträgt er 50 USD pro TiB (beachten Sie: TiB, nicht TB), die durch Pub/Sub nach GCS fließt. Bei einer "nicht-basic"-Subscription gilt das kostenlose 10-GiB-Kontingent nicht.
Zur Berechnung schauen Sie sich an, um wie viel der Speicher Ihrer Tabelle innerhalb von 30 Tagen wächst (das finden Sie im View TABLE_STORAGE_USAGE_TIMELINE mithilfe der Beispielabfragen, die Google bereitstellt) und multiplizieren diesen Wert mit 50 USD/TiB für Ihre monatlichen Pub/Sub-Kosten.
Ich gehe von den Standardeinstellungen aus, ohne Aufbewahrungsdauer oder Filter, und davon, dass Nachrichten nicht länger als 24 Stunden unbestätigt bleiben. All das verursacht zusätzliche Gebühren, die wir in diesem Beispiel jedoch nicht in Anspruch nehmen.
- GCS-Kosten
Bei den GCS-Kosten wird es etwas komplizierter und schwerer überschlagbar, weil viele Faktoren mitspielen. Wir betreiben hier also Pi-mal-Daumen-Mathematik.
Der erste Kostenpunkt ist die Speicherung – sprich: wie viele Daten Sie wie lange ablegen. In den meisten Anwendungsfällen, die ich gesehen habe, kippen Kunden die Daten nach GCS und laden sie sofort in eine neue Datenbank oder ein neues Data Warehouse, mit einer Aufbewahrungsdauer von etwa 7 Tagen, bis sie automatisch gelöscht werden.
In diesem Fall ist die Berechnung simpel: gespeicherte GB (hier wirklich GB, nicht GiB) * Speicherrate (Tabelle hier) * (7 Tage Aufbewahrung / 30 Tage pro Monat).
Der nächste Kostenpunkt sind GCS-Operationen, unterteilt in zwei Klassen: Class A und Class B. Die offizielle Doku finden Sie hier. In unserem Kontext sind Class-A-Operationen Schreibvorgänge auf einzelne Dateien (storage.objects.insert) und Class-B-Operationen Lesevorgänge auf einzelne Dateien (storage.objects.get).
Hier wird es knifflig: Wie "echtzeitnah" Ihre Daten sein müssen, bestimmt, wie viele dieser Operationen anfallen. Pub/Sub liest jede Datei einmal, und das Laden dieser Daten in den finalen Output ist ein weiterer Lesevorgang derselben Datei. Pro Datei, die Pub/Sub nach GCS schreibt, fallen also ein Schreibvorgang und mindestens ein Lesevorgang an (mehr, wenn Sie in mehrere Ziele laden).
Beim Einrichten Ihrer Pub/Sub-Subscription können Sie Schwellwerte für maximale Dateigröße und Zeitdauer festlegen; sobald eine dieser Bedingungen erfüllt ist, wird die Datei nach GCS geschrieben. Erhöht oder senkt man diese Werte, ändert sich – zusammen mit unterschiedlichen Datenmengen – die Anzahl der Operationen drastisch. Damit kommen mehrere Variablen in die Kostengleichung, und jeder Engineer oder Wissenschaftler, der an der Uni eine Vorlesung über multivariate Differentialgleichungen gehört hat, wird bestätigen: Es gibt keinen einfachen Weg, eine multivariate Gleichung zu modellieren.
Daher mein Rat: Konzentrieren Sie sich auf den Zeitfaktor – frei nach dem amerikanischen Sprichwort "time is money". Damit die Rechnung handhabbar bleibt, nehmen wir an: maximal 5 Minuten Dauer, ein (unrealistisch) konstanter Datenstrom und ein einzelnes Ziel, das die Daten ebenfalls alle 5 Minuten liest.
Das ergibt alle 5 Minuten je eine Class-A- und eine Class-B-Operation, also insgesamt 8.640 Operationen jeder Klasse pro Monat (43.200 Minuten in 30 Tagen / 5 Minuten).
Damit liegen die monatlichen Kosten bei (Preistabelle hier):
Class A: (8640/1000) * 0,0050 USD = 0,0432 USD
Class B: (8640/1000) * 0,0004 USD = 0,003456 USD
Gesamt: 0,047 USD/Monat
Das mag niedrig wirken, aber bedenken Sie: Es geht um eine durchgängig kleine Last mit konstantem Datenfluss. So etwas käme in der Realität nie vor und würde 5 Minuten alte Daten liefern – aber es zeigt, wie sich für die meisten Anwender ein "hinreichend genauer" Preis abschätzen lässt.
- Egress-Kosten
Für die meisten Kunden ist das ein großes Vielleicht – beachten Sie aber: Liegt Ihr Ziel nicht in derselben Region oder überqueren die Daten aus dem GCS-Bucket Cloud-Grenzen, fallen beim Laden wahrscheinlich Egress-Gebühren an.
Die Preise dafür finden Sie zur Referenz hier.
GCS-Setup
Der erste – und wohl einfachste – Schritt ist die Einrichtung eines GCS-Buckets. Am bequemsten folgen Sie der offiziellen Doku hier und achten dabei auf die Regionseinstellungen. Ich empfehle dringend, den Bucket in derselben Region wie das Ziel anzulegen (idealerweise auch wie das BigQuery-Quelldataset), um Egress-Gebühren zu vermeiden.
Pub/Sub-Setup
Als Nächstes erstellen Sie ein Pub/Sub-Topic. Das wurde unzählige Male behandelt, deshalb verlinke ich einfach die offizielle Doku hier. Stellen Sie nur sicher, dass Sie das Topic erstellen können und über die korrekten Berechtigungen/Rollen verfügen.
Bevor es weitergeht, müssen Sie eine Subscription für dieses Topic anlegen, mit den Optionen "Write to Cloud Storage" und Avro-Format, etwa so:
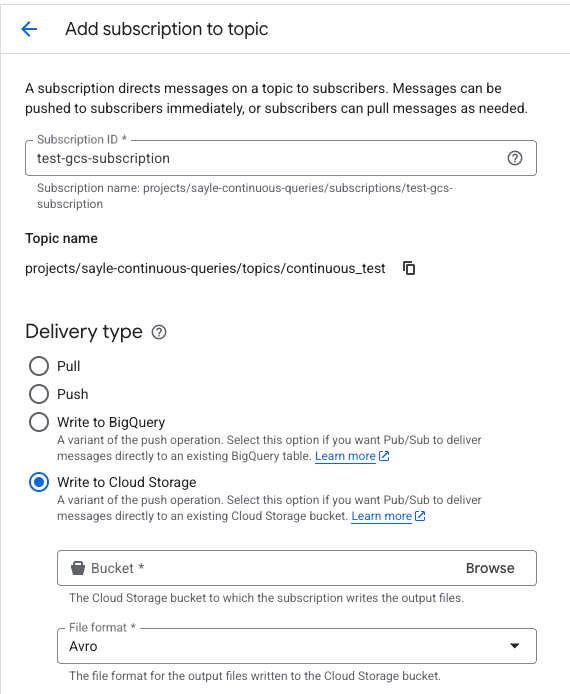
Hinweis: Falls Sie zuvor noch keine GCS-Subscription im Projekt eingerichtet haben, erscheint möglicherweise die unten gezeigte Meldung. Klicken Sie in diesem Fall einfach auf "Set permission" und anschließend auf die Links zum Zuweisen der Rolle in der Seitenleiste.
Service Account (IAM) einrichten
Zum Zeitpunkt des Schreibens unterliegen Continuous Queries bei einem User Account der Einschränkung, dass die Abfrage alle zwei Tage neu gestartet werden muss (siehe hier). Am besten verwenden Sie einen Service Account – das verlängert das Limit auf 150 Tage.
Legen Sie dafür einen Service Account mit folgenden Berechtigungen an:
pubsub.topics.publish
pubsub.topics.get
Zusätzlich benötigt er die Rolle BigQuery Data Viewer (roles/bigquery.dataViewer). Mit weniger als sämtlichen Berechtigungen dieser Rolle bekam ich es nicht zum Laufen – BigQuery scheint im Hintergrund Dinge zu tun, die alle davon erfordern.
Ich empfehle, eine Custom Role mit allen benötigten Berechtigungen anzulegen, um dem Principle of Least Privilege zu folgen.
Hinweis: Nach dem ersten Lauf einer Continuous Query wird automatisch die Rolle BigQuery Continuous Query Service Agent zu diesem Service Account hinzugefügt.
BigQuery-Setup
Der zweite Schritt dieses kleinen Puzzles ist BigQuery und das Einrichten der Continuous Query.
Bevor Sie zu tief eintauchen, ist es empfehlenswert, sich die Einführungsseite zu Continuous Queries bei Google durchzulesen. Sie liefert einen guten Einstieg und macht Sie mit den Möglichkeiten und Grenzen vertraut. Werfen Sie unbedingt einen Blick auf die Einschränkungen rund um SQL und Regionen, damit diese Sie nicht ausbremsen. Ein erheblicher Stolperstein, der mir beim Schreiben dieses Artikels aufgefallen ist: Tabellen, in die Datastream schreibt (in der Doku CDC-Upsert-Daten genannt), werden nicht unterstützt. Wenn Sie Datastream einsetzen, ist es daher am besten, abzuwarten, bis dies behoben ist, oder die Daten in eine neue Tabelle zu verschieben, damit die Continuous Query darauf zugreifen kann.
Wenn Sie startbereit sind, empfehle ich, kurz diese Doku-Seite zu überfliegen, um die richtigen Berechtigungen zum Erstellen von Jobs und Exportieren von Daten einzurichten. Hinzu kommt eine Rolle, die Lesen und Schreiben in Pub/Sub erlaubt – meist die Rollen Pub/Sub Viewer und Publisher.
Suchen Sie als Nächstes die Tabelle (Singular, denn Joins sind zum Zeitpunkt des Schreibens noch nicht erlaubt), aus der Sie neue Datensätze exportieren möchten. Im folgenden Beispiel nennen wir diese Tabelle tickets, vollständig myproject.test_dataset.tickets, mit drei Spalten: ticket_id, assigned_to und assignment_time.
Hier ist das DDL für die Tabelle:
CREATE TABLE myproject.test_dataset.tickets
(
`ticket_id` INT,
`assigned_to` STRING,
`assignment_time` timestamp
)
Zum Befüllen verwende ich ein einfaches Python-Skript, das Sie als Gist hier finden – es erzeugt zufällige Beispieldaten. Ich führe das Skript einfach aus und lege die Dateien in einem GCS-Bucket ab, damit sie für die nächsten Schritte bereitstehen.
Den Workflow ausführen
Bevor Sie die Abfrage schreiben, öffnen Sie zusätzlich einen Tab mit Ihrem Pub/Sub-Topic, damit Sie den Pfad bequem in den nächsten Schritt kopieren können.
Öffnen Sie dann den BigQuery Studio Editor und fügen Sie diese Abfrage ein (passen Sie Projektname und Pub/Sub-Topic an):
EXPORT DATA
OPTIONS (
format = 'CLOUD_PUBSUB',
uri = 'https://pubsub.googleapis.com/projects/<project_name>/topics/<topic_name>')
AS (
SELECT
TO_JSON_STRING(
STRUCT(
ticket_id,
assigned_to,
assignment_time)) AS message
FROM APPENDS(`myproject.test_dataset.tickets`, CURRENT_TIMESTAMP() - INTERVAL 1 MINUTE)
WHERE assigned_to IS NOT NULL
);
Was diese Abfrage tut:
Sie definiert zunächst, dass die Ergebnisse in ein Pub/Sub-Topic exportiert werden (im nächsten Absatz steht, wie Sie den Pfad schnell ermitteln), erstellt einen Struct mit den drei Spalten der Tabelle und kapselt diesen schließlich als JSON-String in einer Spalte namens message – wie es der Pub/Sub-Export verlangt. Der Filter auf assigned_to IS NOT NULL dient nur als Beispiel; mit dem oben genannten Generator-Skript greift er ohnehin nie.
Für die URI-Option oben empfehle ich, den Topic-Namen einfach von der Pub/Sub-Topic-Seite zu kopieren (oben auf der Seite steht etwas wie "projects/<project_name>/topics/<topic_name>" mit einem Copy-Button daneben) und ihn nach dem String "https://pubsub.googleapis.com" einzufügen, um Tippfehler zu vermeiden.
Der APPENDS-Aufruf ist etwas, das Google spät in der Preview-Phase ergänzt hat – er greift einfach alle neuen Datensätze im angegebenen Zeitintervall ab. Da es sich um einen Test handelt, setze ich es auf 1 Minute. Wer weiter zurückgehen will, um ältere Daten zu erfassen, erhöht das Intervall einfach entsprechend.
Bevor Sie auf "Run" klicken, sind noch zwei kleine Schritte nötig.
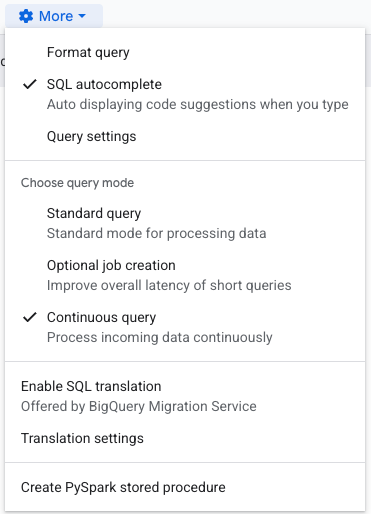
Zunächst sehen Sie wahrscheinlich eine rote Fehlermeldung, dass der Pub/Sub-Export nur Continuous Queries unterstützt – das heißt, wir müssen die Abfrage als Continuous Query markieren. Klicken Sie über der Abfrage auf das "More"-Zahnrad und wählen Sie "Continuous query", wie hier gezeigt:
Sie müssen den Service Account auswählen, unter dem das laufen soll. Klicken Sie also erneut auf das "More"-Zahnrad und wählen Sie "Query settings". Wählen Sie unter "Continuous query IAM permissions" den oben angelegten Service Account.
Jetzt nur noch auf Run klicken, und der Prozess läuft.
Hinweis: Falls Sie noch keine Reservierung eingerichtet und kein Assignment für das aktuelle Projekt für den Continuous-Job-Type erstellt haben, erscheint eine rote Fehlermeldung in etwa dieser Art: "Continuous queries require the project to have a CONTINUOUS assignment to a reservation. No such reservation was found in region US." Um das zu beheben, richten Sie eine Reservierung ein und weisen das Projekt dem Continuous-Job-Type zu, wie weiter oben beschrieben.
Danach läuft die Abfrage – im UI sieht es einfach wie eine länger laufende Abfrage aus.
Hinweis: Wenn Sie das Assignment entfernen oder die Reservierung löschen, stoppt der Job.
Um den Pub/Sub-Export zu testen, führen Sie das oben verlinkte Python-Skript (hier) aus und laden die Ausgabe in einen GCS-Bucket. Dann führen Sie ein kurzes Load wie dieses aus:
LOAD DATA INTO myproject.test_dataset.tickets
FROM FILES (
format = 'CSV',
uris = ['gs://<bucket_name>/sample_data.csv']);
Nach ein paar Minuten Wartezeit prüfen Sie die Pub/Sub-Subscription – Sie sollten in etwa Folgendes sehen:
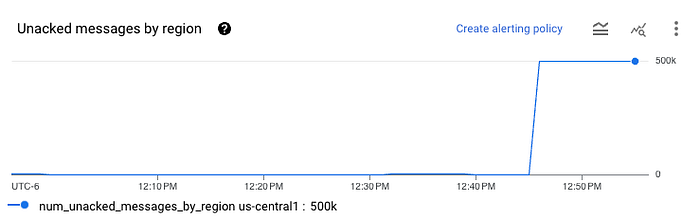
Das bedeutet, die Daten wurden erfolgreich in die Subscription geladen. Werfen Sie nun einen Blick in Ihren Bucket – dort sollten Avro-Dateien auftauchen. Sie können sie aus GCS herunterladen und in einem beliebigen Online-Avro-Viewer prüfen. Sie sehen eine einzelne Spalte namens data mit den JSON-codierten Daten aus Pub/Sub, die wiederum base64-codiert sind.
Ich wünschte, es gäbe einen saubereren Weg, direkt im Avro-Format nach GCS zu schreiben, ohne Pub/Sub einzubeziehen. Continuous Queries unterstützen jedoch nur Pub/Sub als Ziel und nicht direkt GCS. Damit ließe sich auch Spalte für Spalte passend zu Ihrem BigQuery-SQL schreiben – aber das hat Google schlicht noch nicht umgesetzt.
Die Daten sind da – und jetzt?
An diesem Punkt liegen Ihre Daten im Avro-Format in einem GCS-Bucket und lassen sich mit ein wenig Feinarbeit in praktisch jedes Data Warehouse oder jede Datenbank laden.
Da dieser Artikel der inhaltliche Nachfolger meiner letzten Serie ist, bleiben wir beim Thema und laden die Daten in ClickHouse. Selbstverständlich können Sie sie genauso in Databricks, Snowflake, DuckDB usw. laden – mit derselben Methode wie im SQL-Code unten.
Ohne lange Vorrede: Hier ist das ClickHouse-SQL für das Laden. Tragen Sie nur Ihren Bucket-Namen und Ihre GCP-Informationen ein. Eine Anleitung zum Erstellen eines HMAC-Schlüssels finden Sie unter diesem Link.
SELECT
-- Extract the 'ticket_id' field from the JSON data as an integer.
JSONExtractInt(data, 'ticket_id') AS ticket_id,
-- Extract the 'assigned_to' field from the JSON data as a string.
JSONExtractString(data, 'assigned_to') AS assigned_to,
-- Extract the 'assignment_time' field from the JSON data as a string,
-- then cast it to a DateTime64 type for proper timestamp handling.
toDateTime64(JSONExtractString(data, 'assignment_time'), 3) AS assignment_time
FROM
-- The `s3` table function is used for querying files from S3 or S3-compatible services.
-- The function signature is `s3(url, [access_key_id], [secret_access_key], format, structure)`.
-- The URL should point to the GCS bucket endpoint using the HTTPS protocol.
s3(
'https://storage.googleapis.com/<bucket_name>/*.avro',
'<YOUR_GCS_HMAC_ACCESS_KEY>',
'<YOUR_GCS_HMAC_SECRET>',
'Avro',
'data String'
)
Ein Dank geht an Gemini für die Kommentare im Code und das Generieren des DateTime-Codes – diesen Teil habe ich allein einfach nicht zum Laufen gebracht.
Mit BigQuery besser "DoiT"?
Wenn Ihnen das weitergeholfen hat und Sie auf Abruf einen Subject Matter Expert für solche speziellen Fragestellungen suchen oder Ihre Cloud-Ausgaben überprüfen lassen möchten, werfen Sie einen Blick auf das Leistungsangebot von DoiT.
Mehr zu diesen und weiteren Services erfahren Sie hier.