Este artigo é o sucessor espiritual da minha última série (partes 1 e 2) sobre como usar o ClickHouse com dados replicados do BigQuery para reduzir custos de consulta. O principal mecanismo abordado neste artigo ainda não tinha sido anunciado na época daquela série; por isso, ele se tornou um método melhor para replicar os dados desde que entrou em GA no início deste ano.
O foco principal deste artigo é um recurso chamado Continuous Queries. Em essência, é uma forma de manter uma consulta sem fim que devolve resultados conforme eles são carregados ou atualizados nas tabelas do BigQuery. Para quem vem do mundo dos bancos de dados relacionais, é basicamente uma versão enxuta do change-data-capture (CDC) que a maioria dos bancos relacionais tradicionais oferece.
Sem mais rodeios, vamos ao que interessa. Antes de tudo, aqui vai um resumo rápido de como esse setup vai ficar:
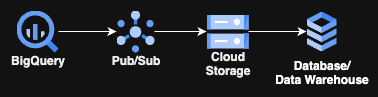
Pois é, não vai envolver nada mirabolante como Cloud Run, GKE ou qualquer coisa de computação; são apenas 3 serviços gerenciados do GCP e o armazenamento de sua escolha para a etapa final. E o melhor: o único código que você vai precisar escrever para isso são algumas linhas de SQL!
Agora, mãos à obra!
Antes de começar
O único pré-requisito de fato é garantir que você tenha as permissões IAM corretas para criar reservations e executar consultas no seu projeto. Se você tem Owner ou Editor, ótimo, mas BigQuery Admin já te dá tudo o que é preciso. Qualquer um dos outros papéis "BigQuery * Admin", além do principal, não concede permissões suficientes para isso.
O fluxo de trabalho
O fluxo de como tudo isso vai funcionar não é muito mais complicado do que o diagrama acima. Ele inclui uma consulta rodando continuamente (convenientemente chamada de Continuous Query) no BigQuery, que envia dados para um tópico do Pub/Sub, que por sua vez encaminha esses dados, via uma ou mais subscriptions do Pub/Sub, para um bucket do GCS. Em seguida, um processo de ETL/ELT pega esses dados e os coloca no destino final, seja para repouso ou para transformação.
Preços
Eu sempre prefiro alinhar expectativas antes de entrar nos detalhes da implementação quando o assunto é preço, já que todo mundo adora um brinquedinho novo até ver a etiqueta.
Há vários componentes aqui que vão gerar custos:
- Custos do BigQuery
- Custos do Pub/Sub
- Custos do GCS
- Custos de egress (potencialmente)
Vou detalhar o que esperar de cada um deles e incluir os preços vigentes no momento em que escrevo, para que ninguém que tente fazer isso seja pego de surpresa por uma fatura inesperada.
- Custos do BigQuery
O BigQuery tem vários componentes que entram na conta dos custos, mas, para esse processo, há apenas um com o qual precisamos nos preocupar: os custos de computação associados à continuous query, via uma reservation do BigQuery Editions.
O continuous querying exige que o cliente use uma reservation Enterprise ou Enterprise Plus, que faz parte do modelo de cobrança baseado em capacidade. Atenção: você NÃO PODE usar o modelo de cobrança on-demand (também conhecido como o modelo de "US$ 5 ou US$ 6,25 por TiB escaneado") para continuous queries. Por causa dessa limitação, talvez você precise criar um projeto separado e atribuí-lo a uma reservation para rodar a continuous query, caso hoje use apenas o modelo on-demand. Recomendo FORTEMENTE que você leia meu artigo original sobre BigQuery Editions aqui antes de ativá-lo para a sua organização inteira. Ligar Editions sem critério pode sair muito caro.
Continuous queries sempre consomem pelo menos um slot, segundo o Google, o que se traduz em um mínimo, ou "baseline", de 50 slots alocados sempre que a consulta estiver em execução. Por isso, o ideal é criar uma reservation, definir o baseline em 50 e depois ajustar o máximo de slots conforme a necessidade da sua consulta. Para testes básicos, um baseline e um máximo de 50 slots são mais do que suficientes. Só não esqueça de excluir a atribuição ou zerar o baseline quando não estiver rodando a consulta, para economizar.
As taxas por slot/hora variam conforme a região e a Edition, então o melhor é consultar a tabela oficial de preços aqui.
- Custos do Pub/Sub
O Pub/Sub neste exemplo tem um único custo: o preço de throughput da subscription Cloud Storage, conforme documentado aqui.
No momento em que escrevo, o valor é de US$ 50 por TiB (atenção: TiB, e não TB) que passa pelo Pub/Sub para o GCS. Vale notar que, ao usar uma subscription "não básica", o tier gratuito de 10 GiB não se aplica.
Para calcular esse custo, veja quanto o armazenamento da sua tabela cresce ao longo de 30 dias (você encontra isso na view TABLE_STORAGE_USAGE_TIMELINE, usando as consultas de exemplo que o Google fornece) e depois multiplique esse valor por US$ 50/TiB para obter os custos mensais do Pub/Sub.
Estou partindo do princípio de que estamos usando as configurações padrão, sem períodos de retenção ou filtros, e que as mensagens não ficam sem confirmação por mais de 24 horas. Tudo isso tem cobranças adicionais, mas não vamos usar nada disso neste exemplo.
- Custos do GCS
Os custos associados ao GCS são onde a coisa fica um pouco mais complicada e difícil de calcular, pelo número de fatores envolvidos. Então vamos fazer uma matemática aproximada por aqui.
O primeiro custo é o de armazenamento, ou seja, quantos dados você está armazenando e por quanto tempo. Na maioria das aplicações desse tipo que já vi, os clientes jogam os dados no GCS e em seguida os carregam imediatamente em um novo banco de dados ou data warehouse, com um período de retenção de cerca de 7 dias antes que sejam excluídos automaticamente.
Nesse caso, é um cálculo direto: GB (aqui é GB mesmo, não GiB) armazenados * taxa de armazenamento (aqui está a tabela) * (7 dias de retenção / 30 dias no mês)
O próximo custo é o de operações do GCS, divididas em dois grupos: operações Classe A e Classe B. Aqui está a documentação oficial sobre isso. Neste contexto, as operações de Classe A são gravações de arquivo único (storage.objects.insert) e as de Classe B são leituras de arquivo único (storage.objects.get).
É aqui que a coisa complica, porque o quão "em tempo real" você precisa dos seus dados vai ditar quantas dessas operações ocorrerão. O Pub/Sub faz uma única leitura de um arquivo, e em seguida o carregamento desses dados para a saída final representa outra leitura do mesmo arquivo. Então, para cada arquivo que o Pub/Sub gravar no GCS, você terá uma única gravação e pelo menos uma leitura (mais leituras, se você estiver carregando para mais destinos).
Ao configurar sua subscription do Pub/Sub, é possível especificar limites de tamanho máximo de arquivo e de duração para a entrega; assim que qualquer uma dessas condições é atendida, o arquivo é gravado no GCS. Como diminuir ou aumentar esses valores, junto com volumes diferentes de dados, muda drasticamente quantas operações são realizadas. Isso adiciona várias variáveis à equação de custo, e qualquer engenheiro ou cientista que tenha cursado equações diferenciais multivariáveis na faculdade vai te dizer que não há jeito fácil de modelar uma equação multivariável.
Por isso, costumo recomendar que você foque no aspecto temporal, pois, como muitos americanos dizem, "time is money". Para deixar a matemática gerenciável, vamos supor que temos uma duração máxima de 5 minutos, com um fluxo de dados constante (o que é impossível na prática) e um único destino lendo a cada 5 minutos também.
Isso significa que, a cada 5 minutos, haverá uma única operação Classe A e uma única Classe B, totalizando 8.640 de cada operação por mês (43.200 minutos em 30 dias / 5 minutos).
Ou seja, o custo por mês ficará assim (aqui está a tabela de preços):
Classe A: (8640/1000) * US$ 0,0050 = US$ 0,0432
Classe B: (8640/1000) * US$ 0,0004 = US$ 0,003456
Total: US$ 0,047/mês
Pode parecer baixo, mas considere que isso é para um workload consistentemente baixo, com fluxo de dados constante. Isso nunca aconteceria na realidade e ainda traria dados defasados em 5 minutos, mas é uma boa forma de chegar a um preço "bom o suficiente" para a maioria dos usuários.
- Custo de Egress
Vale lembrar que isso é um grande "talvez" para a maioria dos clientes, mas fique atento: se o seu destino não estiver na mesma região, ou se você estiver cruzando fronteiras de nuvem a partir do bucket do GCS, é provável que existam cobranças de egress no carregamento dos dados.
Os preços para isso estão listados aqui para referência.
Configuração do GCS
O primeiro passo (e provavelmente o mais fácil) é configurar um bucket do GCS para isso. A forma mais simples é seguir a documentação oficial aqui e prestar atenção nas configurações de localização. Recomendo fortemente colocá-lo na mesma região do destino (e, de preferência, do dataset de entrada do BigQuery) para evitar cobranças de egress.
Configuração do Pub/Sub
O próximo passo é criar um tópico do Pub/Sub. Isso já foi abordado várias e várias vezes, então vou apenas linkar a documentação oficial aqui. Apenas confirme que você consegue criar esse tópico e que tem as permissões/papéis corretos.
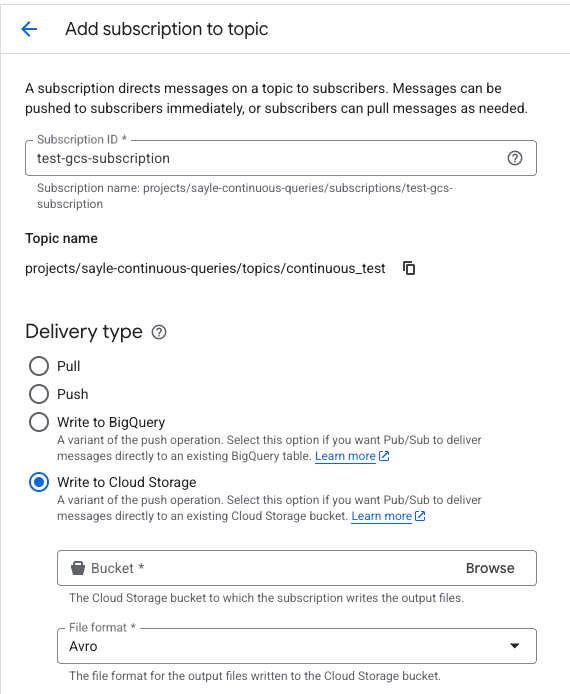
Antes de seguir, você precisará criar uma subscription para esse tópico com as opções "Write to Cloud Storage" e formato Avro definidas, assim:
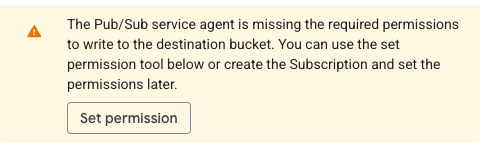
Observação: se você nunca tiver configurado uma subscription do GCS no projeto, talvez veja a mensagem abaixo. Se for o caso, basta clicar no botão "Set permission" e depois nos links de concessão de papel que aparecerem na barra lateral.
Configuração da Service Account (IAM)
No momento em que escrevo, as continuous queries têm uma limitação para contas de usuário: é necessário reiniciar a consulta a cada dois dias, conforme aqui. A melhor saída é usar uma service account, o que estende esse limite para 150 dias.
Dito isso, para esta etapa, crie uma service account com as seguintes permissões:
pubsub.topics.publish
pubsub.topics.get
Além disso, ela vai precisar do papel BigQuery Data Viewer (roles/bigquery.dataViewer). Não consegui fazer funcionar com nada menos do que todas as permissões desse papel, então parece que o BigQuery faz algo nos bastidores que exige todas elas.
Recomendo criar um papel customizado com todas essas permissões necessárias para seguir o Princípio do Menor Privilégio.
Vale notar que, após a primeira execução de uma continuous query, um papel chamado BigQuery Continuous Query Service Agent será adicionado automaticamente a essa service account.
Configuração do BigQuery
A segunda peça desse pequeno quebra-cabeça é o BigQuery e a configuração da continuous query.
Antes de mergulhar fundo, pode ser uma boa ideia ler sobre continuous queries aqui, na página de introdução do Google. Isso dá uma boa noção inicial e ajuda a se familiarizar com os recursos e as limitações das continuous queries. Recomendo dar uma olhada nas limitações de SQL e de regiões para garantir que nada disso vai virar um impeditivo. Um grande impeditivo que percebi durante a redação deste artigo é que ele não suporta tabelas que recebem gravações do Datastream — chamadas de dados de upsert CDC na documentação. Então, se você usa Datastream, talvez seja melhor esperar uma correção ou mover os dados para uma nova tabela para que a continuous query consiga consultá-los.
Quando estiver pronto para começar, recomendo dar uma lida rápida nesta página da documentação para implementar as permissões corretas para criar jobs e exportar dados. Isso é além de um papel que permita ler e gravar no Pub/Sub, que normalmente são os papéis Pub/Sub Viewer e Publisher.
Em seguida, encontre a tabela — singular, no momento em que escrevo, já que joins ainda não são permitidos — da qual você quer exportar novos registros. Para o exemplo abaixo, vamos chamar essa tabela de tickets, com o nome totalmente qualificado myproject.test_dataset.tickets, e 3 colunas: ticket_id, assigned_to e assignment_time.
Aqui está o DDL dessa tabela:
CREATE TABLE myproject.test_dataset.tickets
(
`ticket_id` INT,
`assigned_to` STRING,
`assignment_time` timestamp
)
Para carregar dados nela, estou usando um script Python simples disponível aqui em um gist, que cria alguns dados de amostra aleatórios. Estou apenas executando esse script e jogando esses arquivos em um bucket do GCS para os próximos passos.
Executando o fluxo de trabalho
Antes de escrever a consulta, abra uma aba adicional para o seu tópico do Pub/Sub, assim fica fácil copiar e colar o caminho na próxima etapa.
Em seguida, abra o editor BigQuery Studio e cole esta consulta (ajustando o nome do projeto e o tópico do pub/sub):
EXPORT DATA
OPTIONS (
format = 'CLOUD_PUBSUB',
uri = 'https://pubsub.googleapis.com/projects/<project_name>/topics/<topic_name>')
AS (
SELECT
TO_JSON_STRING(
STRUCT(
ticket_id,
assigned_to,
assignment_time)) AS message
FROM APPENDS(`myproject.test_dataset.tickets`, CURRENT_TIMESTAMP() - INTERVAL 1 MINUTE)
WHERE assigned_to IS NOT NULL
);
Detalhando o que essa consulta faz:
Primeiro, ela define que vai exportar os resultados para um tópico do Pub/Sub (veja no próximo parágrafo uma forma rápida de obter isso); depois, cria uma struct com as 3 colunas da tabela; e, por fim, encapsula essas colunas em uma string JSON dentro de uma coluna chamada message, que é exigida pelo serviço de exportação para o Pub/Sub. Estou filtrando onde assigned_to não é nulo apenas como exemplo; se você usar o código gerador, isso nunca vai acontecer.
Para a opção URI acima, recomendo apenas copiar o nome do tópico na página do tópico Pub/Sub (no topo da página há algo como "projects/<project_name>/topics/<topic_name>" com um botão de copiar ao lado) e usá-lo para inserir na URI logo após a string "https://pubsub.googleapis.com", evitando erros de digitação.
A chamada APPENDS é algo que o Google adicionou no fim da fase de preview e simplesmente captura todos os novos registros no intervalo de tempo especificado. Como isso é um teste, estou colocando 1 minuto. Se você precisar voltar no tempo para pegar dados mais antigos, basta aumentar esse intervalo.
Antes de clicar em executar, há dois pequenos passos a fazer.
Primeiro, você provavelmente verá em vermelho um erro dizendo que a exportação para Pub/Sub só é suportada em continuous query; isso significa que precisamos defini-la como continuous query. Clique no "More sprocket" acima da consulta e selecione "Continuous query", como mostrado aqui:
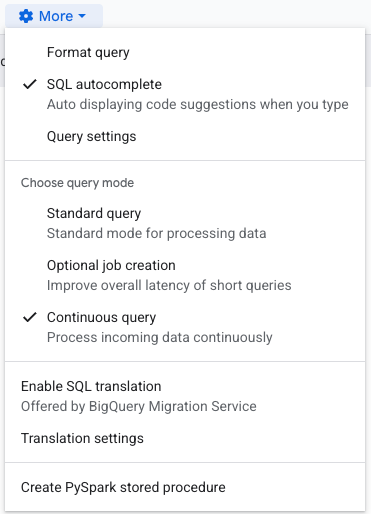
Você precisa escolher a service account com a qual a consulta vai rodar, então, novamente, selecione "More sprocket" e depois "Query settings". Em "Continuous query IAM permissions", escolha a service account criada acima.
Agora basta clicar no botão run e iniciar o processo.
Observação: se você não tiver configurado sua reservation e criado uma atribuição para o projeto atual para os tipos de job continuous, vai aparecer uma mensagem de erro em vermelho dizendo algo como: "Continuous queries require the project to have a CONTINUOUS assignment to a reservation. No such reservation was found in region US." Para corrigir, você precisará configurar uma reservation e atribuir esse projeto a ela para o tipo de job continuous, conforme detalhado anteriormente neste post.
Neste ponto, a consulta estará rodando e, na UI, vai parecer apenas uma consulta de longa duração.
Observação: se você remover a atribuição ou excluir a reservation, o job será interrompido.
Para testar a funcionalidade de exportação para o Pub/Sub, execute o script Python que linkei antes (aqui) e faça upload para um bucket do GCS. Depois, execute uma carga rápida assim:
LOAD DATA INTO myproject.test_dataset.tickets
FROM FILES (
format = 'CSV',
uris = ['gs://<bucket_name>/sample_data.csv']);
Após esperar alguns minutos, verifique a subscription do Pub/Sub e você deverá ver algo assim:
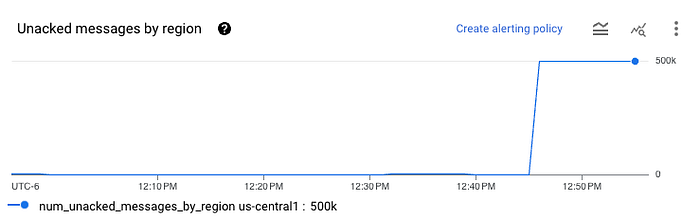
Isso significa que os dados foram carregados com sucesso na subscription. Em seguida, verifique o seu bucket e você deverá ver alguns arquivos Avro aparecerem. Você pode baixá-los do GCS e fazer upload em qualquer visualizador online de arquivos Avro para conferir. Você verá uma única coluna chamada data, com os dados JSON do Pub/Sub codificados em base64.
Eu queria que houvesse uma maneira mais limpa de fazer isso para Avro no GCS sem envolver o Pub/Sub, mas continuous queries só suportam ir para o Pub/Sub e não diretamente para o GCS. Isso também permitiria escrever coluna a coluna, espelhando o seu SQL do BigQuery, mas, infelizmente, o Google ainda não implementou isso.
Os dados estão lá, e agora?
Neste ponto, você tem seus dados armazenados em formato Avro em um bucket do GCS, o que deve permitir carregá-los em praticamente qualquer data warehouse ou banco de dados com um pouco de esforço.
Como este é o sucessor espiritual da minha última série, vamos seguir nesse tema e carregar os dados no ClickHouse. Vale notar que você pode, com a mesma facilidade, carregar isso no Databricks, Snowflake, DuckDB etc., usando esse mesmo método com o meu código SQL abaixo.
Sem mais delongas, aqui está o SQL do ClickHouse para fazer a carga abaixo. Apenas certifique-se de atualizá-lo com o nome do seu bucket e as informações do GCP. Veja este link para instruções sobre como criar uma chave HMAC.
SELECT
-- Extract the 'ticket_id' field from the JSON data as an integer.
JSONExtractInt(data, 'ticket_id') AS ticket_id,
-- Extract the 'assigned_to' field from the JSON data as a string.
JSONExtractString(data, 'assigned_to') AS assigned_to,
-- Extract the 'assignment_time' field from the JSON data as a string,
-- then cast it to a DateTime64 type for proper timestamp handling.
toDateTime64(JSONExtractString(data, 'assignment_time'), 3) AS assignment_time
FROM
-- The `s3` table function is used for querying files from S3 or S3-compatible services.
-- The function signature is `s3(url, [access_key_id], [secret_access_key], format, structure)`.
-- The URL should point to the GCS bucket endpoint using the HTTPS protocol.
s3(
'https://storage.googleapis.com/<bucket_name>/*.avro',
'<YOUR_GCS_HMAC_ACCESS_KEY>',
'<YOUR_GCS_HMAC_SECRET>',
'Avro',
'data String'
)
Tenho que agradecer ao Gemini por adicionar comentários ao meu código e gerar o trecho de DateTime, porque essa parte simplesmente não estava saindo.
Quer "DoiT" melhor com o BigQuery?
Se isso foi útil para você e você quer um especialista no assunto sob demanda para ajudar com questões pontuais como essa, ou quer uma revisão dos seus gastos com nuvem, dê uma olhada nos serviços que a DoiT oferece.
Você pode saber mais sobre esses serviços, e também sobre os nossos outros serviços, aqui.