Este artículo es el sucesor espiritual de mi serie anterior (partes 1 y 2) sobre cómo aprovechar ClickHouse con datos replicados desde BigQuery para reducir los costos de las consultas. El mecanismo principal del que hablo aquí todavía no se había anunciado cuando publiqué esa serie; por eso, desde que pasó a GA a principios de este año, se ha vuelto un mejor método para replicar los datos.
El foco de este artículo está en una funcionalidad llamada Continuous Queries. En esencia, es una forma de tener una consulta que nunca termina y que devuelve resultados a medida que se cargan o actualizan los datos en las tablas de BigQuery. Para quienes vienen del mundo de las bases de datos relacionales, se trata básicamente de una versión recortada del change-data-capture (CDC) que ofrecen la mayoría de las bases relacionales tradicionales.
Sin más preámbulos, vamos al grano. Antes que nada, así se ve el flujo de esta configuración:
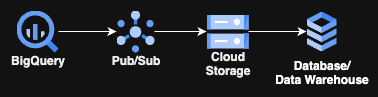
Sí, no incluye Cloud Run, GKE ni nada relacionado con cómputo; solo usa 3 servicios administrados de GCP y luego el almacenamiento que elijas para la última etapa. Y lo mejor de todo: ¡el único código que vas a escribir son unas pocas líneas de SQL!
¡Ahora sí, manos a la obra!
Antes de empezar
El único requisito real es contar con los permisos de IAM correctos para crear reservas y ejecutar consultas en tu proyecto. Si tienes Owner o Editor, perfecto, pero con BigQuery Admin tienes todo lo necesario. Cualquiera de los otros roles "BigQuery * Admin" distintos al principal no otorga permisos suficientes para hacer esto.
El flujo de trabajo
El flujo no es mucho más complicado que el diagrama de arriba. Consiste en una consulta que se ejecuta de forma continua (de ahí el nombre Continuous Query) en BigQuery, que envía datos a un topic de Pub/Sub, el cual a su vez los reenvía mediante las suscripciones de Pub/Sub asociadas hacia un bucket de GCS. Después, un proceso de ETL/ELT toma esos datos y los lleva a su destino final, ya sea de almacenamiento o de transformación.
Precios
Siempre prefiero ajustar las expectativas antes de entrar en los detalles de implementación cuando se trata de precios, porque a todos nos encantan los juguetes nuevos… hasta que vemos la etiqueta.
Aquí intervienen varios componentes que generan costos:
- Costos de BigQuery
- Costos de Pub/Sub
- Costos de GCS
- Costos de egress (potencialmente)
Voy a desglosar qué esperar de cada uno e incluiré los precios vigentes al momento de escribir esto, para que quien intente esto no se lleve una sorpresa con la factura.
- Costos de BigQuery
BigQuery tiene muchos componentes que aportan a los costos, pero para este proceso solo nos importa uno: los costos de cómputo asociados a la consulta continua mediante una reserva de BigQuery Editions.
Las consultas continuas requieren que el cliente use una reserva Enterprise o Enterprise Plus, que forma parte del modelo de facturación basado en capacidad. Ten en cuenta que NO PUEDES usar el modelo de facturación on-demand (es decir, el de "$5 o $6.25 por TiB escaneado") para las consultas continuas. Por esta limitación, puede que necesites crear un proyecto aparte y asignarlo a una reserva para correr la consulta continua, en caso de que actualmente solo uses el modelo on-demand. Te RECOMIENDO MUCHO leer mi artículo original sobre BigQuery Editions aquí antes de activar esto en toda tu organización. Activar Editions a ciegas puede salir muy caro.
Las consultas continuas siempre consumirán al menos un slot, según Google, lo que se traduce en un mínimo o "baseline" de 50 slots asignados mientras la consulta esté corriendo. Por eso, lo mejor es crear una reserva, fijar el baseline en 50 y luego ajustar el máximo de slots a lo que necesite tu consulta. Para pruebas básicas, un baseline y un máximo de 50 slots es más que suficiente. Eso sí, asegúrate de eliminar la asignación o de poner el baseline en cero cuando no estés corriendo la consulta, para ahorrar costos.
Las tarifas por slot/hora varían según la región y la Edition, así que lo mejor es consultar la tabla oficial de precios aquí.
- Costos de Pub/Sub
En este ejemplo, Pub/Sub tiene un solo costo: el throughput de la suscripción a Cloud Storage, documentado aquí.
Al momento de escribir esto, son $50 USD por TiB (ojo, TiB, no TB) que pasan por Pub/Sub hacia GCS. Ten en cuenta que cuando usas una suscripción "no básica", la capa gratuita de 10 GiB no aplica.
Para calcular este costo, mira cuánto crece el almacenamiento de tu tabla en el transcurso de 30 días (lo encuentras en la vista TABLE_STORAGE_USAGE_TIMELINE usando las consultas de ejemplo que provee Google) y multiplica esa cantidad por $50/TiB para obtener tu costo mensual de Pub/Sub.
Asumo que esto se hace con la configuración por defecto, sin períodos de retención ni filtros, y que los mensajes no quedan sin reconocer por más de 24 horas. Todo eso tiene cargos adicionales, pero no los usaremos en este ejemplo.
- Costos de GCS
Los costos asociados a GCS son donde la cosa se complica un poco y se vuelve difícil de calcular con precisión, por la cantidad de factores que intervienen. Así que aquí haremos algunas cuentas aproximadas.
El primer costo es el de almacenamiento: básicamente, cuántos datos guardas y por cuánto tiempo. En la mayoría de los casos que he visto, los clientes vuelcan los datos en GCS y los cargan de inmediato en una nueva base de datos o data warehouse, con un período de retención de unos 7 días antes de que se eliminen automáticamente.
En este caso, el cálculo es directo: GB (en este caso, GB, no GiB) almacenados * tarifa de almacenamiento ( aquí está la tabla) * (7 días de retención/30 días en un mes)
El siguiente costo es el de las operaciones de GCS, que se dividen en dos categorías: operaciones Clase A y Clase B. Aquí está la documentación oficial. En este contexto, las operaciones Clase A son escrituras de un solo archivo (storage.objects.insert) y las Clase B son lecturas de un solo archivo (storage.objects.get).
Aquí es donde se complica: qué tan "en tiempo real" necesites tus datos definirá cuántas de estas operaciones se realizan. Pub/Sub hará una sola lectura de un archivo, y luego la carga de esos datos al destino final implicará otra lectura del mismo archivo. Así que tendrás una escritura y al menos una lectura (más si cargas a varios destinos) por cada archivo que Pub/Sub escriba en GCS.
Al configurar tu suscripción de Pub/Sub, puedes definir umbrales de tamaño máximo de archivo y de duración para la entrega; cuando se cumpla cualquiera de los dos, el archivo se escribe en GCS. Como subir o bajar estos valores, junto con cantidades distintas de datos, cambia drásticamente cuántas operaciones se ejecutan, esto agrega múltiples variables a la ecuación de costos. Y cualquier ingeniero o científico que haya pasado por una clase universitaria de ecuaciones diferenciales multivariables te dirá que no hay forma fácil de modelar una ecuación multivariable.
Por eso, suelo decir que te enfoques en el aspecto temporal, porque, como dicen muchos estadounidenses, "el tiempo es dinero". Para que las cuentas sean manejables, supongamos un máximo de 5 minutos con un flujo de datos imposible y constante, y un único destino que también lee los datos cada 5 minutos.
Eso significa que cada 5 minutos habrá una operación Clase A y una Clase B, sumando 8.640 de cada una al mes (43.200 minutos por 30 días/5 minutos).
Eso quiere decir que el costo mensual será ( aquí está la tabla de precios):
Clase A: (8640/1000) * $0.0050 = $0.0432
Clase B: (8640/1000) * $0.0004 = $0.003456
Total: $0.047/mes
Puede parecer bajo, pero ten en cuenta que esto es para una carga consistentemente baja con datos fluyendo de manera constante. En la realidad esto nunca pasaría y daría datos con 5 minutos de retraso, pero sirve para mostrar una buena forma de calcular un precio "lo suficientemente aproximado" para la mayoría de los usuarios.
- Costos de egress
Esto es un gran "tal vez" para la mayoría de los clientes, pero ten presente que si tu destino no está en la misma región o cruzas fronteras de nube desde el bucket de GCS, lo más probable es que haya cargos de egress al cargar los datos.
Los precios están listados aquí como referencia.
Configuración de GCS
El primer paso (y posiblemente el más fácil) es configurar un bucket de GCS para esto. La forma más sencilla es seguir la documentación oficial aquí y prestar atención a la configuración de ubicación. Te recomiendo encarecidamente ponerlo en la misma región que el destino (y de ser posible que el dataset de BigQuery de entrada) para evitar cargos de egress.
Configuración de Pub/Sub
El siguiente paso es crear un topic de Pub/Sub. Esto se ha cubierto muchísimas veces, así que solo enlazaré la documentación oficial aquí. Solo asegúrate de poder crear el topic y de tener los permisos/roles correctos.
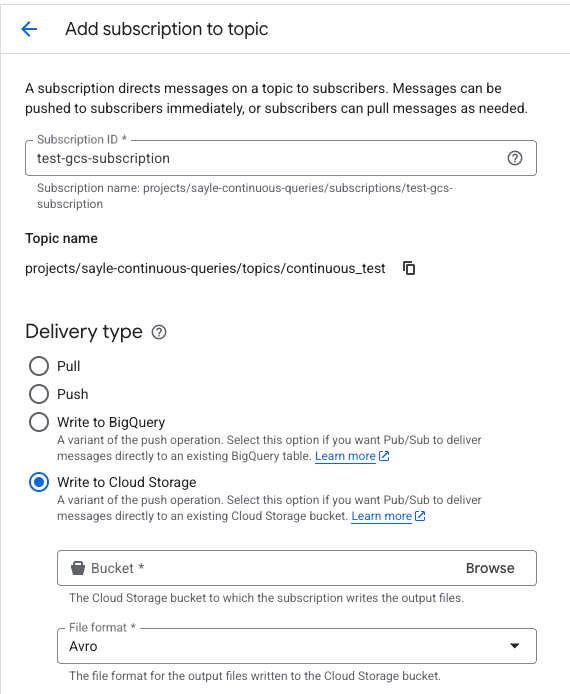
Antes de continuar, debes crear una suscripción para este topic con las opciones "Write to Cloud Storage" y formato Avro, así:
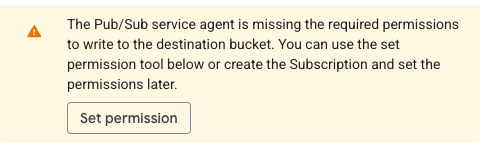
Nota: si nunca has configurado una suscripción de GCS en el proyecto, puede que veas el mensaje de abajo. Si es así, solo haz clic en el botón "Set permission" y luego en los enlaces de "grant role" que aparecen en la barra lateral.
Configuración de la cuenta de servicio (IAM)
Al momento de escribir esto, las consultas continuas tienen una limitación cuando se ejecutan con una cuenta de usuario: hay que reiniciar la consulta cada dos días, según aquí. La mejor opción es usar una cuenta de servicio, que extiende ese límite a 150 días.
Dicho esto, para este paso, crea una cuenta de servicio con los siguientes permisos:
pubsub.topics.publish
pubsub.topics.get
Además, necesitará el rol BigQuery Data Viewer ( roles/bigquery.dataViewer). No logré que funcionara con menos permisos que los del rol completo, así que parece que BigQuery hace algo internamente que requiere todos esos permisos.
Recomiendo crear un rol personalizado con todos los permisos necesarios para seguir el Principio del Menor Privilegio.
Ten en cuenta que tras la primera ejecución de una consulta continua, se le agregará automáticamente a esta cuenta de servicio un rol llamado BigQuery Continuous Query Service Agent.
Configuración de BigQuery
El segundo paso de este pequeño rompecabezas es BigQuery y la configuración de la consulta continua.
Antes de meternos a fondo, puede ser buena idea leer sobre las consultas continuas aquí, en la página de introducción de Google. Te dará un buen panorama y te familiarizará con las capacidades y limitaciones de las consultas continuas. Recomiendo revisar las limitaciones de SQL y de regiones para asegurarte de que no sean un bloqueo. Un bloqueo importante que noté al escribir este artículo es que no soporta tablas en las que escribe Datastream, llamadas en la documentación "CDC upsert data"; así que si usas Datastream, lo mejor es esperar a que esto se solucione o mover los datos a una nueva tabla para que la consulta continua pueda consultarla.
Cuando estés listo para empezar, te recomiendo darle una leída rápida a esta página de la documentación para implementar los permisos correctos para crear jobs y exportar datos. Esto va además del rol que te permite leer y escribir en Pub/Sub, que normalmente son los roles Pub/Sub Viewer y Publisher.
Luego, identifica la tabla (singular, al momento de escribir esto, ya que aún no se permiten joins) de la cual quieres exportar nuevos registros. Para el ejemplo de abajo, llamamos a esta tabla tickets, con el nombre completo myproject.test_dataset.tickets, y 3 columnas: ticket_id, assigned_to y assignment_time.
Aquí está el DDL de esta tabla:
CREATE TABLE myproject.test_dataset.tickets
(
`ticket_id` INT,
`assigned_to` STRING,
`assignment_time` timestamp
)
Para cargar datos en esta tabla, uso un script sencillo de Python que está aquí en un gist y que genera datos de muestra aleatorios. Lo único que hago es ejecutar el script y dejar los archivos en un bucket de GCS para los siguientes pasos.
Ejecutar el flujo de trabajo
Antes de escribir la consulta, abre una pestaña adicional con tu topic de Pub/Sub para que puedas copiar y pegar fácilmente la ruta en el siguiente paso.
Después, abre el editor de BigQuery Studio y pega esta consulta (ajustando el nombre del proyecto y el topic de pub/sub):
EXPORT DATA
OPTIONS (
format = 'CLOUD_PUBSUB',
uri = 'https://pubsub.googleapis.com/projects/<project_name>/topics/<topic_name>')
AS (
SELECT
TO_JSON_STRING(
STRUCT(
ticket_id,
assigned_to,
assignment_time)) AS message
FROM APPENDS(`myproject.test_dataset.tickets`, CURRENT_TIMESTAMP() - INTERVAL 1 MINUTE)
WHERE assigned_to IS NOT NULL
);
Para desglosar lo que hace esta consulta:
Primero define que va a exportar los resultados a un topic de Pub/Sub (en el siguiente párrafo verás una forma rápida de obtenerlo), luego crea un struct con las 3 columnas de la tabla y, por último, encapsula todo en un string JSON como una columna llamada message, que es lo que requiere el servicio de exportación a Pub/Sub. Filtro por assigned_to no nulo solo a modo de ejemplo; si usas el código de generación, esto nunca va a ocurrir.
Para la opción URI de arriba, recomiendo simplemente copiar el nombre del topic desde la página del topic de Pub/Sub (en la parte superior aparece algo como "projects/<project_name>/topics/<topic_name>" con un botón de copiar al lado) y usarlo para insertarlo en la URI después del string "https://pubsub.googleapis.com" y así evitar errores de tipeo.
La llamada APPENDS es algo que Google añadió tarde en la fase de preview, y simplemente toma todos los nuevos registros en el intervalo de tiempo especificado. Como esto es una prueba, lo dejé en 1 minuto. Si necesitas retroceder en el tiempo para tomar datos más antiguos, aumentar este intervalo te permitirá hacerlo.
Antes de presionar "Run", quedan dos pasos pequeños.
Primero, lo más probable es que veas un error en rojo indicando que la exportación a Pub/Sub solo es compatible con consultas continuas; esto significa que debemos configurarla como tal. Haz clic en la rueda de "More" arriba de la consulta y selecciona "Continuous query", como se ve aquí:
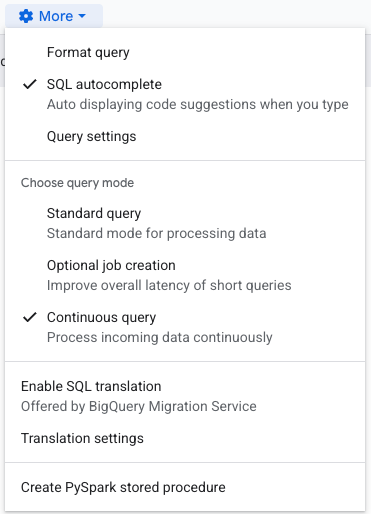
Tienes que elegir la cuenta de servicio con la que se va a ejecutar, así que de nuevo selecciona la rueda "More" y luego "Query settings". Debajo de "Continuous query IAM permissions" elige la cuenta de servicio creada antes.
Ahora solo presiona el botón "Run" y arranca el proceso.
Nota: si no has configurado tu reserva ni creado una asignación para el proyecto actual con el tipo de job continuo, aparecerá un mensaje de error en rojo más o menos así: "Continuous queries require the project to have a CONTINUOUS assignment to a reservation. No such reservation was found in region US.". Para solucionarlo, deberás configurar una reserva y asignar este proyecto a ella para el tipo de job continuo, como se indicó antes en este artículo.
En este punto, la consulta estará corriendo y simplemente se ve como una consulta de larga duración en la UI.
Nota: si eliminas la asignación o borras la reserva, el job se detiene.
Para probar la exportación a Pub/Sub, ejecuta el script de Python que enlacé antes ( aquí) y sube el resultado a un bucket de GCS. Luego corre una carga rápida así:
LOAD DATA INTO myproject.test_dataset.tickets
FROM FILES (
format = 'CSV',
uris = ['gs://<bucket_name>/sample_data.csv']);
Después de esperar unos minutos, revisa la suscripción de Pub/Sub y deberías ver algo así:
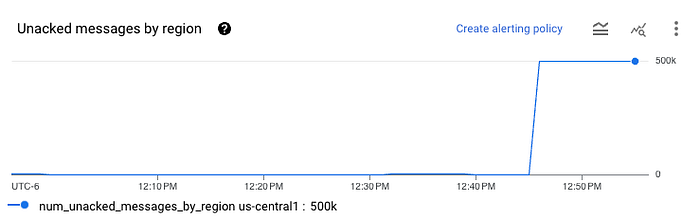
Eso significa que los datos se cargaron correctamente en la suscripción. A continuación, revisa tu bucket y deberías ver aparecer algunos archivos Avro. Puedes descargarlos desde GCS y subirlos a cualquier visor de Avro en línea para inspeccionarlos. Verás una sola columna llamada data con los datos JSON de Pub/Sub codificados en formato base64.
Ojalá hubiera una forma más limpia de hacer esto a Avro en GCS sin pasar por Pub/Sub, pero las consultas continuas solo soportan ir hacia Pub/Sub y no directamente a GCS. Eso también permitiría escribir columna por columna para que coincida con tu SQL de BigQuery, pero, lamentablemente, Google aún no lo ha implementado.
Los datos están ahí, ¿y ahora qué?
Llegado este punto, tienes tus datos guardados en formato Avro en un bucket de GCS, los cuales deberían poder cargarse en prácticamente cualquier data warehouse o base de datos con un poco de maña.
Como este es el sucesor espiritual de mi serie anterior, sigamos con el tema y carguémoslos en ClickHouse. Eso sí, con este mismo método y el código SQL de abajo puedes cargarlos con la misma facilidad en DataBricks, Snowflake, DuckDB, etc.
Sin más rodeos, aquí está el SQL de ClickHouse para realizar la carga. Solo asegúrate de actualizarlo con el nombre de tu bucket y la información de GCP. En este enlace están las instrucciones para crear una clave HMAC.
SELECT
-- Extract the 'ticket_id' field from the JSON data as an integer.
JSONExtractInt(data, 'ticket_id') AS ticket_id,
-- Extract the 'assigned_to' field from the JSON data as a string.
JSONExtractString(data, 'assigned_to') AS assigned_to,
-- Extract the 'assignment_time' field from the JSON data as a string,
-- then cast it to a DateTime64 type for proper timestamp handling.
toDateTime64(JSONExtractString(data, 'assignment_time'), 3) AS assignment_time
FROM
-- The `s3` table function is used for querying files from S3 or S3-compatible services.
-- The function signature is `s3(url, [access_key_id], [secret_access_key], format, structure)`.
-- The URL should point to the GCS bucket endpoint using the HTTPS protocol.
s3(
'https://storage.googleapis.com/<bucket_name>/*.avro',
'<YOUR_GCS_HMAC_ACCESS_KEY>',
'<YOUR_GCS_HMAC_SECRET>',
'Avro',
'data String'
)
Tengo que agradecerle a Gemini por agregarle comentarios al código y por generar la parte de DateTime, ya que no lograba que funcionara por mi cuenta.
¿Quieres "DoiT" mejor con BigQuery?
Si esto te resultó útil y quieres tener un experto en la materia a demanda para resolver problemas puntuales como este, o si quieres una revisión de tus gastos en la nube, échale un vistazo a los servicios que ofrece DoiT.
Puedes conocer más sobre estos y otros servicios aquí.