
AWSが強化学習の入門用に公開した優れたツールは、制御用インターフェースが限定的でした。そこで私たちはこれをハックし、OpenAI Gym対応・TensorFlow駆動のDeep Q-Learning「猛牛」へと仕立て直しました。
AWSがDeepRacerを発表したねらいは、実際に動く自律走行カーを通じて強化学習の基礎をインタラクティブに学べるようにすることでした。この車は決められた形式のモデルでしか制御できず、モデルはAWSコンソールで学習させたうえで車のインターフェース経由でアップロードする仕組みです。まさかこの車が、物体めがけて突進する「猛牛」に変貌するとは、AWSも思ってもみなかったでしょう!
変身に必要だったのは3つのステップ。第一に、車を動かしているAPIを突き止めること。第二に、深層強化学習の環境とエージェントを開発し、車の制御に組み込むこと。そして最後に、物体に向かって操舵し走り込む方法を車に学習させることです。
AWS DeepRacer対応のOpenAI Gymインターフェース
https://github.com/gidutz/DeepBullFighting
0 forks
6 stars
3 open issues
最近のコミット:
- buxfix, gad
- improved game, gad
- Merge remote-tracking branch 'remotes/origin/deep-q-learning', gad
- Bugfix, gad
- Merge pull request #9 from gidutz/deep-q-learningDeep q learning, GitHub
車のAPIを突き止める
まず取り組んだのは、車が利用しているAPIの特定です。ブラウザから車へのHTTPリクエストをログに取って観察したところ、API呼び出しが car_ip/api/ 配下にあると分かりました。そこでSSHで車に接続し、psコマンドで確認するとPythonのWebサーバーが稼働中。該当ディレクトリへ移動し、すべての.pyファイルに対して「/API/」をgrepすれば、車がサポートするAPIの一覧が手に入ります。
ディープラーニングによる物体検出
物体検出とは、画像内の物体を機械に識別させるタスクです。今回はYOLOv3モデルのTensorFlow/Keras実装を用い、フレーム全体に対するボトルの中心位置と大きさの比率を抽出しました。Deep-Q-Agentの目的は、検出された物体の中心がフレーム中央に重なるように行動することです。
 車載カメラからのフレーム。YOLOv3でボトルのバウンディングボックスを検出し、フレーム中心からボックス中心までの位置を算出。あわせてフレームのサイズも計算します。
車載カメラからのフレーム。YOLOv3でボトルのバウンディングボックスを検出し、フレーム中心からボックス中心までの位置を算出。あわせてフレームのサイズも計算します。
Deep-Q-Agent
車から見てボトルがどこにあるかを把握するのと、そこへ向かう動き方を知るのは、まったく別の話です。深層強化学習に馴染みがなければ、ボトルの正面に近づくのに必要な角度を幾何学的に計算するコードを書こうとするでしょう。しかし強化学習を使えば、試行錯誤を通じて機械自身に制御方法を学ばせ、目標を達成させることができます。今回の実装では、GoogleのDeepMindがAtari 2600の名作ゲームでコンピューターに勝ち方を覚えさせた手法、Deep Q-Learningを採用しました。
Deep Q-Learning
Deep Q-Learningは、環境をモデル化せずに強化学習を解くアプローチです。つまり、車を動かす物理法則や、車とボトルの相互作用をモデル化しようとはしません。代わりに、機械に試行を重ねさせ、ある状態でどの行動が最も大きな報酬をもたらすかを学習させます。
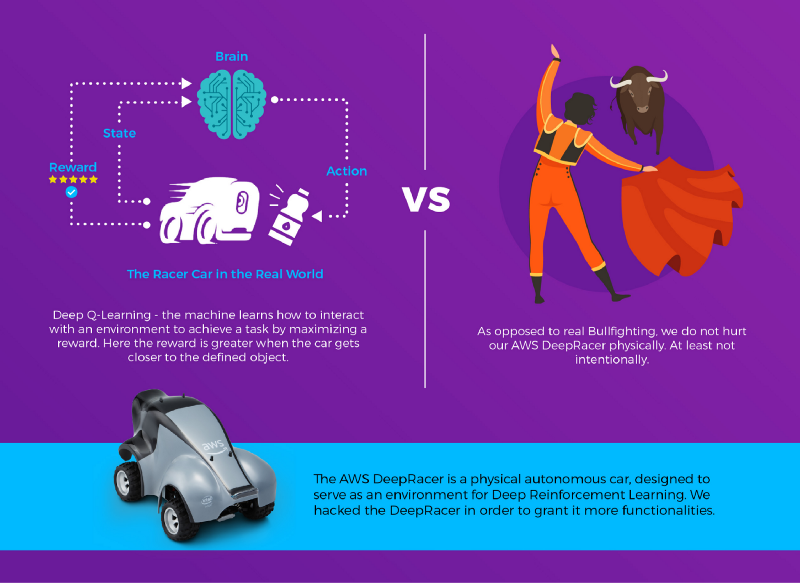
「報酬」とは?
強化学習における報酬とは、行動の「良し悪し」を評価できることを前提に、エージェントが行動を取った結果として与えられるスコアです。エージェントは、受け取る報酬が最大になるよう自らの行動を最適化していきます。今回のケースでは、検出された物体の中心がフレーム中央に近づくほど車は物体の正面に位置し、物体の占有率が大きくなるほど距離が縮まっている、と考えました。そこで、車が物体の正面にあり画面全体を覆っているときに 1 を返し、遠ざかるほど値が小さくなるよう、この2つの要素を一つにまとめた式を考案しました:
step_reward = (1-distance_to_center)*(object_coverage)DeepRacerへのDeep-Q-Learning適用
DeepRacerの動きは、ステアリング角(angle)とスロットル(throttle)の2つのパラメータで制御されます。いずれも-1.0~+1.0の範囲の浮動小数点数です。「行動」とは、angleとthrottleの値を設定し、車を0.3秒間走らせること。タスクを単純化するため、連続的な行動空間を12通りの(angle, throttle)タプルに離散化しました。これにより、エージェントの役目は観測結果から12通りの組み合わせのうち1つを選ぶだけにまで絞り込まれます。
https://www.youtube.com/watch?v=L2MsII6-kd8
https://gist.github.com/gidutz/d4e0d8aa90293bf5e90b428878f5da35
\\\___________________________________________________________
記事を楽しんでいただけましたか?最新情報や新しいコンテンツはGadのTwitterでお届けしています。