
A AWS lançou uma ferramenta sensacional para ensinar Reinforcement Learning a iniciantes, mas liberou uma interface bem limitada para controlá-la. Demos um jeito nisso e a transformamos em um Deep Q-Learning Raging Bull, compatível com o OpenAI Gym e movido a TensorFlow.
Em parceria com: Nir Malbin e Aviv Laufer
Quando a AWS lançou o DeepRacer, a ideia era ensinar os fundamentos de reinforcement learning com um carro autônomo físico e interativo. O carro só podia ser controlado por tipos específicos de modelos, treinados no console da AWS e enviados pela interface do próprio carro. Mal sabiam eles que estávamos prestes a transformá-lo em um touro raivoso, pronto para investir contra qualquer objeto pela frente!
A transformação exigiu três etapas: primeiro, descobrir a API que controla o carro. Segundo, desenvolver um ambiente e um agente de deep reinforcement learning para integrá-los aos controles do carro. Por fim, deixar o carro aprender sozinho a esterçar e a avançar contra os objetos.
Interface do OpenAI Gym compatível com o AWS DeepRacer
https://github.com/gidutz/DeepBullFighting
0 forks.
6 stars.
3 issues abertas.
Commits recentes:
- buxfix, gad
- improved game, gad
- Merge remote-tracking branch 'remotes/origin/deep-q-learning', gad
- Bugfix, gad
- Merge pull request #9 from gidutz/deep-q-learningDeep q learning, GitHub
Descobrindo a API do carro
Queríamos descobrir a API usada pelo carro. Ao registrar as requisições HTTP do navegador para o carro, vimos que as chamadas ficam em car_ip/api/. Com isso em mãos, conectamos ao carro via SSH e, com o comando "ps", encontramos um servidor web em Python rodando. Entramos no diretório com cd e usamos o grep para procurar a string "/API/" em todos os arquivos .py. Pronto: agora tínhamos a lista de APIs suportadas pelo carro.
Deep Object Detection
Detecção de objetos é a tarefa em que uma máquina aprende a identificar objetos dentro de uma imagem. Usamos uma implementação em TensorFlow/Keras do modelo YOLOv3, capaz de detectar objetos, para extrair o centro e as proporções das garrafas em relação ao quadro inteiro. O objetivo do Deep-Q-Agent é executar ações que aproximem o centro do objeto detectado do centro do quadro.
 Quadros capturados pela câmera do carro. Com o YOLOv3, encontramos a bounding box de uma garrafa e calculamos o deslocamento do centro da caixa em relação ao centro do quadro. O tamanho do quadro também é calculado.
Quadros capturados pela câmera do carro. Com o YOLOv3, encontramos a bounding box de uma garrafa e calculamos o deslocamento do centro da caixa em relação ao centro do quadro. O tamanho do quadro também é calculado.
O Deep-Q-Agent
Saber onde a garrafa está em relação ao carro é uma coisa; outra bem diferente é fazer o carro se mover até ela. Se você não conhece o conceito de Deep Reinforcement Learning, provavelmente tentaria escrever um código que fizesse algum cálculo geométrico para estimar o ângulo em que o carro precisa se deslocar para chegar mais perto da garrafa e ficar de frente para ela. Acontece que reinforcement learning permite que a própria máquina aprenda a se controlar e atingir esse objetivo por tentativa e erro. Nesta implementação, usamos um método chamado Deep Q-Learning, o mesmo que ajudou o DeepMind, do Google, a ensinar computadores a vencer jogos, testado nos clássicos do Atari 2600.
Deep Q-Learning
Deep Q-Learning é uma abordagem para resolver reinforcement learning sem modelar o ambiente; ou seja, sem tentar modelar a física do movimento do carro nem a interação entre o carro e a garrafa. Em vez disso, deixamos a máquina experimentar e aprender quais ações geram a melhor recompensa para um determinado estado.
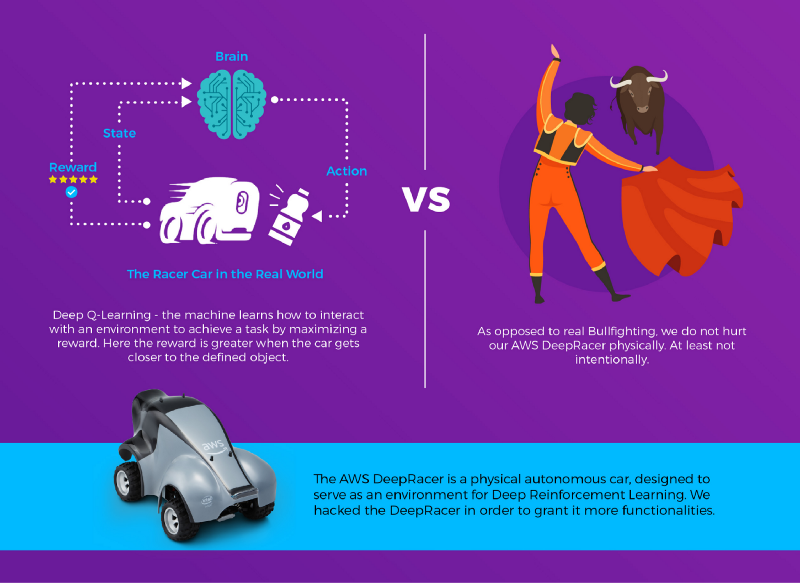
Recompensa?
Em Reinforcement Learning, a recompensa é uma pontuação atribuída ao ator quando ele executa uma ação, partindo do pressuposto de que dá para avaliar o quão "boa" foi essa ação. O ator tenta otimizar suas ações para maximizar as recompensas que recebe. No nosso caso, partimos da ideia de que trazer o centro do objeto detectado para o centro do quadro significaria que o carro está de frente para o objeto e que aumentar a área ocupada pelo objeto na imagem significaria que o carro está mais perto dele. Por isso, combinamos os dois fatores em uma fórmula única que retorna 1 quando o carro está de frente para o objeto e ele cobre a tela inteira, e valores menores conforme o carro se afasta:
step_reward = (1-distance_to_center)*(object_coverage)Aplicando Deep-Q-Learning ao DeepRacer
O movimento do DeepRacer é controlado por dois parâmetros: ângulo e aceleração (throttle). Ambos são números de ponto flutuante entre -1,0 e +1,0. Uma "ação" consiste em definir os valores de ângulo e throttle e deixar o carro andar por 0,3 segundo. Para simplificar a tarefa, discretizamos o espaço contínuo de ações em 12 tuplas diferentes (ângulo, throttle), de modo que o agente só precisasse escolher uma das 12 combinações possíveis a cada observação.
https://www.youtube.com/watch?v=L2MsII6-kd8
https://gist.github.com/gidutz/d4e0d8aa90293bf5e90b428878f5da35
\\\___________________________________________________________
Curtiu a história? Siga o Gad no Twitter para acompanhar as novidades e novos conteúdos.