
AWS a lancé un super outil pour initier les débutants au Reinforcement Learning, mais avec une interface de contrôle limitée. Nous l'avons détourné pour en faire un taureau furieux en Deep Q-Learning, compatible avec OpenAI Gym et propulsé par TensorFlow.
En collaboration avec : Nir Malbin et Aviv Laufer
Quand AWS a sorti son AWS DeepRacer, l'idée était d'enseigner les bases du reinforcement learning à travers une voiture autonome physique et interactive. La voiture ne pouvait être pilotée que par certains types de modèles, entraînés sur la console AWS puis chargés via son interface. Les concepteurs étaient loin de se douter qu'on allait la transformer en taureau furieux capable de foncer sur des objets !
La transformation s'est faite en trois étapes : d'abord, identifier l'API qui pilote la voiture. Ensuite, développer un environnement et un agent de deep reinforcement learning pour l'interfacer avec ses commandes. Enfin, laisser la voiture apprendre à se diriger et à foncer sur des objets.
Interface OpenAI Gym compatible avec AWS DeepRacer
https://github.com/gidutz/DeepBullFighting
0 forks.
6 stars.
3 issues ouvertes.
Commits récents :
- buxfix, gad
- improved game, gad
- Merge remote-tracking branch 'remotes/origin/deep-q-learning', gad
- Bugfix, gad
- Merge pull request #9 from gidutz/deep-q-learningDeep q learning, GitHub
À la découverte de l'API de la voiture
Nous voulions identifier l'API utilisée par la voiture. En traçant les requêtes HTTP envoyées par le navigateur vers le véhicule, nous avons constaté que les appels d'API passent par car_ip/api/. Forts de cette information, nous nous sommes connectés à la voiture en SSH et, avec la commande ps, nous avons repéré un serveur web Python en cours d'exécution. Direction le répertoire concerné, puis un grep sur la chaîne /API/ dans tous les fichiers PY. Et voilà la liste complète des API prises en charge par la voiture.
Détection d'objets en deep learning
La détection d'objets consiste à laisser une machine repérer des objets dans une image. Nous avons utilisé une implémentation TensorFlow/Keras du modèle YOLOv3, capable de détecter des objets, pour extraire le centre et les proportions de bouteilles par rapport à l'image globale. L'objectif du Deep-Q-Agent est d'effectuer des actions pour rapprocher le centre de l'objet détecté du centre de l'image.
 Images issues de la caméra de la voiture. Avec YOLOv3, on identifie la bounding box d'une bouteille et on calcule l'écart entre le centre de la box et celui de l'image. La taille de l'image est également calculée.
Images issues de la caméra de la voiture. Avec YOLOv3, on identifie la bounding box d'une bouteille et on calcule l'écart entre le centre de la box et celui de l'image. La taille de l'image est également calculée.
Le Deep-Q-Agent
Savoir où se trouve la bouteille par rapport à la voiture est une chose, mais comment la voiture saura-t-elle s'en approcher ? Si le Deep Reinforcement Learning ne vous est pas familier, vous chercheriez sans doute à écrire un bout de code réalisant divers calculs géométriques pour estimer l'angle dans lequel la voiture doit se déplacer afin de se rapprocher de la bouteille et de se positionner devant elle. Le reinforcement learning, lui, permet à la machine d'apprendre à se piloter elle-même pour atteindre cet objectif, par essais et erreurs. Pour cette implémentation, nous avons utilisé une méthode appelée Deep Q-Learning, celle-là même qui a permis à DeepMind (Google) d'apprendre à des ordinateurs à gagner à des jeux, comme cela a été démontré sur la mythique Atari 2600.
Deep Q-Learning
Le Deep Q-Learning est une approche du reinforcement learning sans modélisation de l'environnement : pas question, par exemple, de modéliser la physique du mouvement de la voiture ni l'interaction entre la voiture et la bouteille. À la place, on laisse la machine expérimenter et apprendre quelles actions rapportent la meilleure récompense pour un état donné.
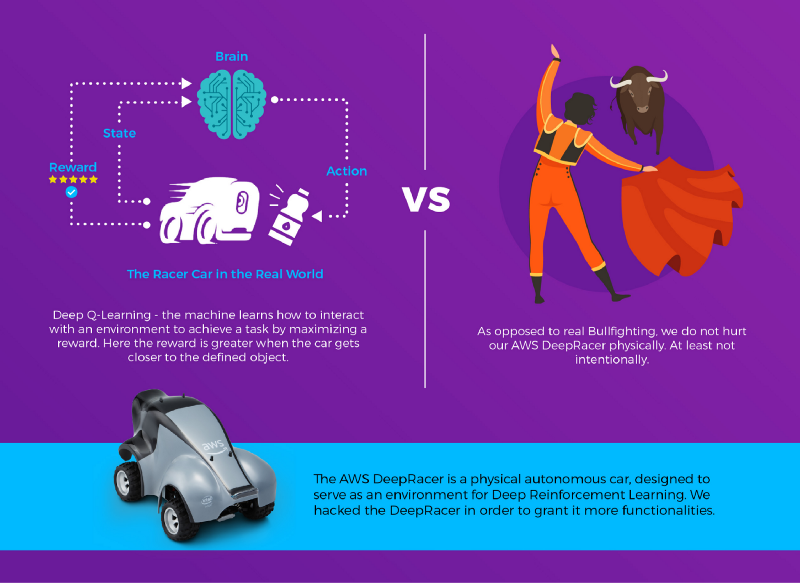
La récompense ?
En Reinforcement Learning, la récompense est un score attribué à l'acteur en conséquence d'une action, en supposant qu'il soit possible d'évaluer à quel point une action a été bonne. L'acteur cherche à optimiser ses actions pour maximiser les récompenses obtenues. Dans notre cas, nous avons estimé que ramener le centre de l'objet détecté au centre de l'image revenait à placer la voiture face à l'objet, tandis qu'agrandir la zone qu'il occupe traduit le rapprochement du véhicule. Nous avons donc combiné les deux dans une formule deux-en-un qui produit 1 lorsque la voiture est face à l'objet et que celui-ci occupe tout l'écran, et une valeur plus faible à mesure qu'elle s'en éloigne :
step_reward = (1-distance_to_center)*(object_coverage)Appliquer le Deep-Q-Learning au DeepRacer
Le mouvement du DeepRacer est piloté par deux paramètres : l'angle et l'accélération (throttle). Les deux sont des nombres à virgule flottante compris entre -1,0 et +1,0. Une action consiste à fixer des valeurs d'angle et d'accélération, puis à laisser la voiture rouler pendant 0,3 seconde. Pour simplifier la tâche, nous avons discrétisé l'espace d'action continu en 12 tuples (angle, throttle) distincts ; la mission de l'agent se réduit ainsi à choisir l'une des 12 combinaisons possibles à partir de l'observation.
https://www.youtube.com/watch?v=L2MsII6-kd8
https://gist.github.com/gidutz/d4e0d8aa90293bf5e90b428878f5da35
\\\___________________________________________________________
Cet article vous a plu ? Suivez Gad sur Twitter pour ne rien manquer de ses dernières publications.