
AWS ha lanciato uno strumento eccezionale per avvicinare i principianti al Reinforcement Learning, ma con un'interfaccia di controllo molto limitata. Noi l'abbiamo modificato e trasformato in un Raging Bull basato su Deep Q-Learning, compatibile con OpenAI Gym e alimentato da TensorFlow.
In collaborazione con: Nir Malbin e Aviv Laufer
Quando AWS ha lanciato il suo DeepRacer, l'idea era insegnare le basi del reinforcement learning attraverso un'auto autonoma fisica e interattiva. L'auto poteva essere pilotata solo da specifiche tipologie di modelli, addestrati nella console AWS e caricati tramite la sua interfaccia. Quello che ad AWS sfuggiva è che eravamo sul punto di trasformarla in un toro infuriato, pronto a caricare a testa bassa contro qualunque oggetto!
La trasformazione si è articolata in tre fasi: prima abbiamo dovuto scoprire l'API che governa l'auto. Poi abbiamo sviluppato un ambiente di deep reinforcement learning e un agente in grado di interfacciarsi con i comandi del veicolo. Infine, abbiamo lasciato che l'auto imparasse da sola a sterzare e a puntare gli oggetti.
Interfaccia OpenAI Gym compatibile con AWS DeepRacer
https://github.com/gidutz/DeepBullFighting
0 fork.
6 stelle.
3 issue aperte.
Commit recenti:
- buxfix, gad
- improved game, gad
- Merge remote-tracking branch 'remotes/origin/deep-q-learning', gad
- Bugfix, gad
- Merge pull request #9 from gidutz/deep-q-learningDeep q learning, GitHub
Alla scoperta dell'API dell'auto
Volevamo capire quale API utilizzasse l'auto. Tracciando le richieste HTTP dal browser verso il veicolo, abbiamo visto che le chiamate API passano da car_ip/api/. A quel punto ci siamo collegati all'auto via SSH e, con il comando 'ps', abbiamo individuato un web server Python in esecuzione. Siamo entrati nella directory e con grep abbiamo cercato la stringa "/API/" in tutti i file PY. Risultato: l'elenco completo delle API supportate dall'auto.
Deep Object Detection
L'object detection è il compito con cui chiediamo a una macchina di riconoscere gli oggetti all'interno di un'immagine. Abbiamo usato un'implementazione TensorFlow/Keras del modello YOLOv3, in grado di rilevare oggetti, per estrarre il centro e le proporzioni delle bottiglie rispetto al frame. L'obiettivo del Deep-Q-Agent è compiere azioni che spostino il centro dell'oggetto rilevato verso il centro del frame.
 Frame ripresi dalla telecamera dell'auto. Con YOLOv3 individuiamo il bounding box di una bottiglia e calcoliamo lo scarto tra il centro del box e il centro del frame. Viene calcolata anche la dimensione del frame.
Frame ripresi dalla telecamera dell'auto. Con YOLOv3 individuiamo il bounding box di una bottiglia e calcoliamo lo scarto tra il centro del box e il centro del frame. Viene calcolata anche la dimensione del frame.
Il Deep-Q-Agent
Sapere dove si trova la bottiglia rispetto all'auto è una cosa; ben altra è far sì che l'auto sappia come muoversi per raggiungerla. Chi non ha familiarità con il Deep Reinforcement Learning probabilmente proverebbe a scrivere del codice basato su calcoli geometrici, per stimare l'angolo necessario all'auto per avvicinarsi e posizionarsi di fronte alla bottiglia. Il reinforcement learning, invece, permette alla macchina di imparare da sola come muoversi per raggiungere l'obiettivo, attraverso un processo per tentativi ed errori. In questa implementazione abbiamo adottato un metodo chiamato Deep Q-Learning, lo stesso con cui DeepMind di Google ha insegnato ai computer a vincere ai videogiochi, testato sul classico Atari 2600.
Deep Q-Learning
Il Deep Q-Learning è un approccio al reinforcement learning che non richiede di modellare l'ambiente: niente fisica del movimento dell'auto, niente modellazione dell'interazione tra auto e bottiglia. Si lascia che la macchina sperimenti e scopra da sola quali azioni le procurano la ricompensa migliore in un dato stato.
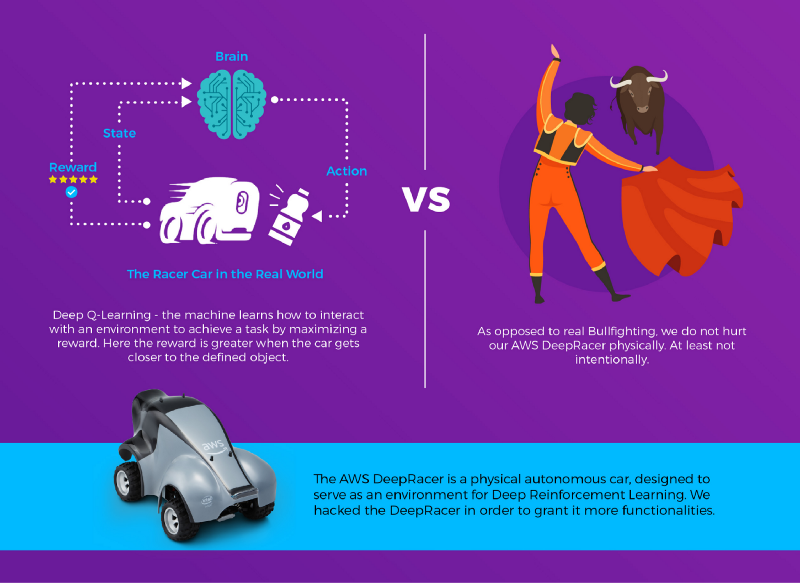
Ricompensa?
Nel Reinforcement Learning, la ricompensa è il punteggio attribuito all'azione compiuta dall'attore, partendo dal presupposto che sia possibile valutare quanto un'azione sia stata "buona". L'attore cercherà di ottimizzare le proprie azioni in modo da massimizzare le ricompense ricevute. Nel nostro caso, abbiamo ipotizzato che portare il centro dell'oggetto rilevato al centro del frame significasse avere l'auto di fronte all'oggetto, mentre l'aumento dell'area coperta dall'oggetto rilevato indicasse che l'auto gli si stava avvicinando. Abbiamo quindi messo a punto la formula due-a-uno che restituisce 1 quando l'auto è di fronte all'oggetto e questo riempie l'intero schermo, e valori inferiori man mano che si allontana:
step_reward = (1-distance_to_center)*(object_coverage)Applicare il Deep-Q-Learning a DeepRacer
Il movimento di DeepRacer è governato da due parametri: angolo di sterzata e accelerazione. Entrambi sono numeri in virgola mobile compresi tra -1,0 e +1,0. Un'"azione" consiste nell'impostare i valori di sterzata e accelerazione e lasciare che l'auto proceda per 0,3 secondi. Per semplificare il problema abbiamo discretizzato lo spazio d'azione continuo in 12 tuple distinte (sterzata, accelerazione), riducendo il compito dell'agente alla scelta di una tra 12 combinazioni possibili a partire dall'osservazione.
https://www.youtube.com/watch?v=L2MsII6-kd8
https://gist.github.com/gidutz/d4e0d8aa90293bf5e90b428878f5da35
\\\___________________________________________________________
L'articolo ti è piaciuto? Segui Gad su Twitter per restare aggiornato sui contenuti più recenti.