
AWS lanzó una herramienta increíble para enseñar Reinforcement Learning a principiantes, pero con una interfaz de control muy limitada. Le hicimos un hack y la convertimos en un Raging Bull de Deep Q-Learning, compatible con OpenAI Gym y potenciado por TensorFlow.
Junto a: Nir Malbin y Aviv Laufer
Cuando AWS lanzó su DeepRacer, la idea era enseñar los fundamentos del reinforcement learning con un auto autónomo, físico e interactivo. El auto solo aceptaba ciertos tipos de modelos, entrenados desde la consola de AWS y cargados a través de su interfaz. Lo que no se imaginaban es que estábamos a punto de convertirlo en un toro furioso, listo para embestir objetos a toda velocidad.
La transformación tomó tres pasos: primero, descubrir la API que controla el auto. Segundo, desarrollar un entorno y un agente de deep reinforcement learning para integrarlos con los controles del auto. Y por último, dejar que el auto aprendiera solo a girar y embestir objetos.
Interfaz de OpenAI Gym compatible con AWS DeepRacer
https://github.com/gidutz/DeepBullFighting
0 forks.
6 stars.
3 issues abiertos.
Commits recientes:
- buxfix, gad
- improved game, gad
- Merge remote-tracking branch 'remotes/origin/deep-q-learning', gad
- Bugfix, gad
- Merge pull request #9 from gidutz/deep-q-learningDeep q learning, GitHub
Descubriendo la API del auto
Lo primero era dar con la API que usa el auto. Al registrar las solicitudes HTTP entre el navegador y el auto, descubrimos que las llamadas a la API estaban en car_ip/api/. Con ese dato, nos conectamos al auto vía SSH y, con el comando 'ps', vimos que había un servidor web de Python corriendo. Entramos al directorio con cd y aplicamos grep al string "/API/" en todos los archivos PY. Así obtuvimos la lista completa de las APIs que el auto soporta.
Deep Object Detection
La detección de objetos es una tarea en la que dejamos que una máquina identifique objetos dentro de una imagen. Usamos una implementación en TensorFlow/Keras del modelo YOLOv3, que detecta objetos, para extraer el centro y las proporciones de las botellas respecto al frame completo. El objetivo del Deep-Q-Agent es ejecutar acciones para que el centro del objeto detectado se desplace hacia el centro del frame.
 Frames de la cámara del auto. Con YOLOv3 encontramos el bounding box de una botella y calculamos su centro respecto al centro del frame. También se calcula el tamaño del frame.
Frames de la cámara del auto. Con YOLOv3 encontramos el bounding box de una botella y calculamos su centro respecto al centro del frame. También se calcula el tamaño del frame.
El Deep-Q-Agent
Saber dónde está la botella respecto al auto es una cosa, pero ¿cómo va a saber el auto moverse hacia ella? Si no estás familiarizado con el Deep Reinforcement Learning, probablemente intentarías escribir un código que hiciera cálculos geométricos para estimar el ángulo en el que el auto debe moverse para acercarse y quedar frente a la botella. Sin embargo, el reinforcement learning permite que la máquina aprenda a controlarse a sí misma para lograr ese objetivo, mediante prueba y error. En esta implementación usamos un método llamado Deep Q-Learning, el mismo que ayudó a DeepMind de Google a enseñar a las computadoras a ganar partidas, probado con el clásico Atari 2600.
Deep Q-Learning
Deep Q-Learning es un enfoque para resolver el reinforcement learning sin modelar el entorno; es decir, sin intentar modelar la física del movimiento del auto ni la interacción entre el auto y la botella. En cambio, se deja que la máquina experimente y aprenda qué acciones le darán la mejor recompensa para un estado dado.
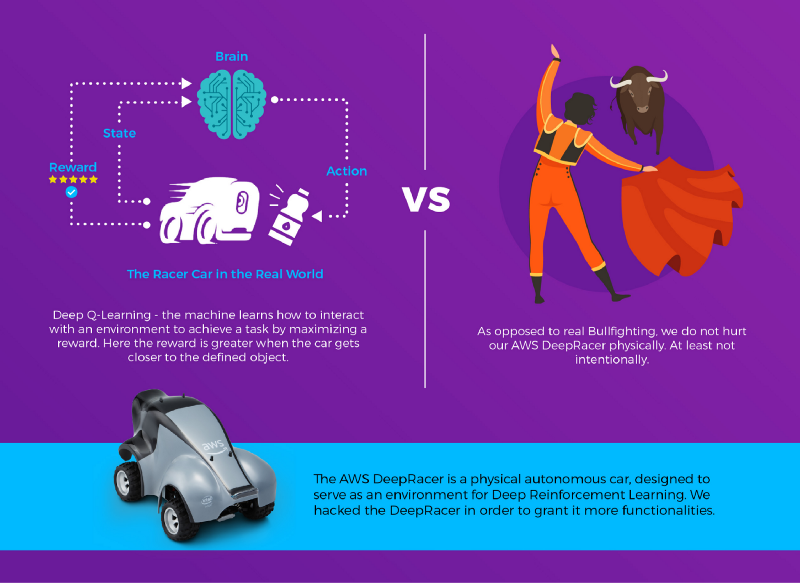
¿Recompensa?
En Reinforcement Learning, la recompensa es un puntaje que se otorga al actor por ejecutar una acción, asumiendo que es posible evaluar qué tan "buena" fue esa acción. El actor buscará optimizar sus acciones para maximizar las recompensas que recibe. En nuestro caso, pensamos que llevar el centro del objeto detectado al centro del frame implicaría que el auto quedara justo frente al objeto, y que aumentar la cobertura del objeto detectado implicaría que el auto está más cerca. Por eso combinamos ambos factores en una fórmula que devuelve 1 cuando el auto está frente al objeto y este cubre toda la pantalla, y un valor menor a medida que se aleja:
step_reward = (1-distance_to_center)*(object_coverage)Aplicando Deep-Q-Learning a DeepRacer
El movimiento del DeepRacer se controla con dos parámetros: ángulo (angle) y aceleración (throttle). Ambos son números de punto flotante en el rango de -1.0 a +1.0. Una "acción" consiste en fijar valores de ángulo y aceleración y dejar que el auto avance durante 0.3 segundos. Para simplificar la tarea, discretizamos el espacio continuo de acciones en 12 tuplas distintas (angle, throttle), de modo que el agente solo tuviera que elegir una de las 12 combinaciones posibles según la observación.
https://www.youtube.com/watch?v=L2MsII6-kd8
https://gist.github.com/gidutz/d4e0d8aa90293bf5e90b428878f5da35
\\\___________________________________________________________
¿Te gustó la historia? Sigue a Gad en Twitter para no perderte las novedades y el contenido más reciente.