
AWS hat ein klasse Tool veröffentlicht, um Einsteigern Reinforcement Learning näherzubringen – allerdings mit stark eingeschränkter Steuerung. Wir haben es gehackt und in einen wütenden Deep-Q-Learning-Stier verwandelt, kompatibel mit OpenAI Gym und auf Basis von TensorFlow.
Gemeinsam mit: Nir Malbin und Aviv Laufer
Als AWS den DeepRacer auf den Markt brachte, sollte er die Grundlagen des Reinforcement Learning anhand eines interaktiven, physischen autonomen Fahrzeugs vermitteln. Steuern ließ sich das Auto nur über bestimmte Modelltypen, die in der AWS-Konsole trainiert und über die Schnittstelle des Autos hochgeladen werden mussten. Was bei AWS damals niemand ahnte: Wir würden den DeepRacer in einen wütenden Stier verwandeln, der gelernt hat, auf Objekte loszustürmen!
Die Verwandlung lief in drei Schritten ab: Zuerst mussten wir die API aufspüren, über die das Auto läuft. Anschließend galt es, eine Deep-Reinforcement-Learning-Umgebung samt Agent zu entwickeln und mit der Steuerung des Autos zu verbinden. Zuletzt blieb uns nur noch, das Auto lernen zu lassen, wie es lenkt und in Objekte hineinfährt.
OpenAI-Gym-Schnittstelle, kompatibel mit AWS DeepRacer
https://github.com/gidutz/DeepBullFighting
0 Forks.
6 Stars.
3 offene Issues.
Aktuelle Commits:
- buxfix, gad
- improved game, gad
- Merge remote-tracking branch 'remotes/origin/deep-q-learning', gad
- Bugfix, gad
- Merge pull request #9 from gidutz/deep-q-learningDeep q learning, GitHub
Die API des Autos aufspüren
Wir wollten herausfinden, welche API das Auto nutzt. Indem wir die HTTP-Anfragen vom Browser an das Auto mitloggten, kamen wir darauf, dass die API-Aufrufe unter car_ip/api/ liegen. Mit diesem Wissen verbanden wir uns per SSH mit dem Auto und sahen über den Befehl "ps", dass dort ein Python-Webserver läuft. Wir wechselten in das entsprechende Verzeichnis und durchsuchten alle PY-Dateien per grep nach dem String "/API/". Damit hatten wir die vollständige Liste der APIs, die das Auto unterstützt.
Deep Object Detection
Bei Object Detection geht es darum, eine Maschine Objekte innerhalb eines Bildes erkennen zu lassen. Wir haben eine TensorFlow/Keras-Implementierung des YOLOv3-Modells eingesetzt, um Mittelpunkt und Proportionen von Flaschen im Verhältnis zum Gesamtbild zu extrahieren. Ziel des Deep-Q-Agents ist es, Aktionen so zu wählen, dass sich der Mittelpunkt des erkannten Objekts in Richtung Bildmitte bewegt.
 Bilder aus der Kamera des Autos. Mit YOLOv3 ermitteln wir die Bounding Box einer Flasche und berechnen den Abstand des Box-Mittelpunkts zur Bildmitte. Auch die Größe der Box wird berechnet.
Bilder aus der Kamera des Autos. Mit YOLOv3 ermitteln wir die Bounding Box einer Flasche und berechnen den Abstand des Box-Mittelpunkts zur Bildmitte. Auch die Größe der Box wird berechnet.
Der Deep-Q-Agent
Zu wissen, wo die Flasche relativ zum Auto steht, ist die eine Sache – aber woher weiß das Auto, wie es sich darauf zubewegen soll? Wer mit Deep Reinforcement Learning nicht vertraut ist, würde vermutlich versuchen, Code zu schreiben, der über geometrische Berechnungen den ungefähren Winkel ermittelt, in den das Auto fahren muss, um näher heranzukommen und vor der Flasche zum Stehen zu kommen. Reinforcement Learning geht den umgekehrten Weg: Die Maschine lernt selbst per Versuch und Irrtum, wie sie sich steuern muss, um dieses Ziel zu erreichen. In unserer Implementierung haben wir eine Methode namens Deep Q-Learning eingesetzt – dieselbe, mit der Googles DeepMind Computern beigebracht hat, am klassischen Atari 2600 Spiele zu gewinnen.
Deep Q-Learning
Deep Q-Learning ist ein Ansatz, mit dem sich Reinforcement Learning lösen lässt, ohne die Umgebung zu modellieren – also ohne die Physik der Autobewegung oder die Interaktion zwischen Auto und Flasche nachzubilden. Stattdessen experimentiert die Maschine und lernt, welche Aktionen in einem gegebenen Zustand die höchste Belohnung bringen.
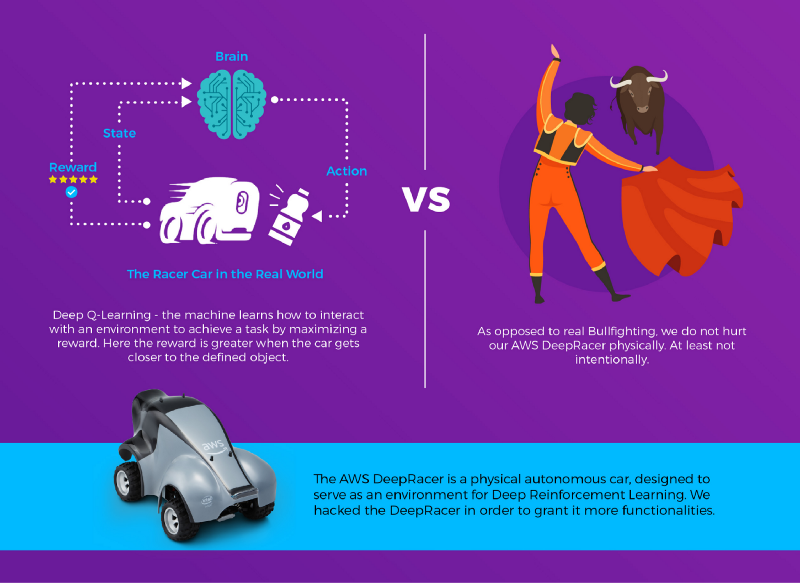
Belohnung?
Beim Reinforcement Learning ist die Belohnung ein Score, der als Folge einer Aktion des Akteurs vergeben wird – vorausgesetzt, man kann beurteilen, wie "gut" eine Aktion war. Der Akteur versucht, seine Aktionen so zu wählen, dass die Summe der Belohnungen maximal wird. In unserem Fall sind wir davon ausgegangen: Liegt der Mittelpunkt des erkannten Objekts in der Bildmitte, steht das Auto frontal davor – und je größer der Bildanteil des erkannten Objekts ist, desto näher ist das Auto dran. Wir haben beide Größen in einer Formel kombiniert, die 1 liefert, wenn das Auto vor dem Objekt steht und es das gesamte Bild ausfüllt, und entsprechend weniger, je weiter es entfernt ist:
step_reward = (1-distance_to_center)*(object_coverage)Deep-Q-Learning auf den DeepRacer anwenden
Die Bewegung des DeepRacer wird über zwei Parameter gesteuert: Lenkwinkel (angle) und Gas (throttle). Beide sind Fließkommazahlen im Bereich von -1.0 bis +1.0. Eine "Aktion" bedeutet, Werte für angle und throttle zu setzen und das Auto 0,3 Sekunden lang fahren zu lassen. Um die Aufgabe zu vereinfachen, haben wir den kontinuierlichen Aktionsraum in 12 verschiedene Tupel (angle, throttle) diskretisiert. Damit reduziert sich die Aufgabe des Agents darauf, anhand der Beobachtung eine von 12 möglichen Kombinationen auszuwählen.
https://www.youtube.com/watch?v=L2MsII6-kd8
https://gist.github.com/gidutz/d4e0d8aa90293bf5e90b428878f5da35
\\\___________________________________________________________
Hat Ihnen der Beitrag gefallen? Folgen Sie Gad auf Twitter und verpassen Sie keine neuen Inhalte und Updates.