本記事は 第1回(IoT CoreとPub/Subを利用して、本番規模のIoTデバイス群からテレメトリデータをGoogle Cloud環境へ安全に取り込む方法を解説)、および 第2回(そのデータをDataflowでPub/SubからBigQueryへシームレスに移し、Data Studioで可視化する方法を解説)の続編です。
これまでの記事を追ってこられた方は、家中に温度センサーを設置し、ライブストリーミングされたデータがGCPに流れ込んで、最終的にGoogleのデータウェアハウスサービスであるBigQueryに収まる様子を楽しんでいただけたことと思います。さて、ここから先はどうしましょうか。このデータを実際にどう活かしていけばよいのでしょうか。
こうした疑問にお答えするべく、BigQueryの中でも特にユニークかつ強力な機能の一つであるBigQuery MLを使った実例をご紹介します。
これまでの記事をお読みでなくてもご安心ください。データセットはKaggleで公開していますので、こちらを使いながら進めていただけます。
BigQuery MLの概要
他のデータウェアハウスサービスとは異なり、BigQueryには機械学習の学習機能とデプロイ機能が標準で組み込まれています。学習もデプロイも、シンプルに記述できるSQLライクなコマンドで実行可能です。
わずか数行のSQL風コードで、ロジスティック回帰や線形回帰、k-meansクラスタリング、ディープニューラルネットワークなど、作成するモデルの種類を指定できます。あるいは本記事のように、AutoML Tablesモデルを作成してGoogleにすべてお任せすることも可能です。ほとんどのモデルでは、ラベル列と特徴量列の指定以外に細かな設定は必要ありません。
BigQuery内でMLの学習を始める具体的な手順に入る前に、まずは生の温度データをどのように予測モデルへ活用できるのか、そしてモデル構築の前にどのようなデータ変換が必要なのかを整理しておく必要があります。なんといっても、機械学習は9割がデータ準備ですから。
機械学習のゴールと進め方
本記事を執筆している現在(2021年2月)、ここオレゴン州はひんやりと華氏48度(約9℃)。ヒーターがフル稼働して快適に温めてくれていますが、たまには窓を開けて家の空気を入れ替えたくもなります — 特に、まだトイレトレーニングが完璧ではない生後9週間のコーギーがいるとなおさらです!
やりたいのは、窓を開けたあと、長時間開けっぱなしになっていたらGCPが「窓が開いていますよ」と知らせてくれるようにすること。電気を無駄にしたくありませんからね!できれば、家のメインリビングに配置した温度センサーが、どの窓を閉めるべきかまで教えてくれると最高です。

うちのMapleです!世界一かわいい子犬。ご安心ください、写真はまだまだあります。
私のGCPプロジェクトには3つのセンサーが温度テレメトリデータをストリーミングしており、それぞれが家のメインリビングの別々の窓のそばに配置されています。
2つのセンサーは窓のすぐそば、3つ目のセンサーは最も近い窓から約8フィート(約2.4m)離れています。センサーと窓との距離関係はデータにも如実に表れていて、あるセンサー(device_id)は他の2つよりも数度高い値を報告しています:
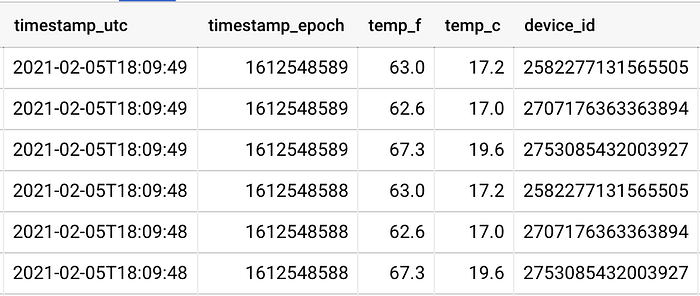
センサー258*と270*はそれぞれの窓のすぐそばに、センサー275*は3つ目の窓から約8フィート離れた位置に配置
特定の窓が開いているタイミングを識別する機械学習モデルを構築するには、学習用の最終テーブルを得るためにいくつかのデータ変換ステップを踏む必要があります。モデル学習に必要なものは次のとおりです:
- 窓が開いている時間帯の記録。「窓#1/2/3が開いている」開始・終了時刻をExcelに手入力しました。記録のない時間帯は窓が閉まっているものとみなします。このテーブルは最終的にCSV化し、BigQueryテーブルとして読み込みます。
- 各行に特定の秒のセンサー別温度値が入っている生のストリーミング温度データテーブルを、各秒1行のピボット形式に変換します。秒ごとの行には、その瞬間の各デバイスの温度を保持する列に加え、現在値とx秒前の値との差分を示す列も持たせます。狙いは、各センサーの現在値だけでなく、過去の特定の時間間隔(10分前、5分前、3分前、1分前、…5秒前まで)からどれだけ変化したかを追跡することです。これらの列は優れた予測特徴量として機能します。
- 窓の開閉時間帯を定義したBQテーブルと、ピボット済みの温度テーブルをマージし、予測用の温度特徴量列と窓開放/全窓閉鎖のラベル列を含む最終テーブルを作成します。
それでは、これらのステップを順番に見ていきましょう。
窓の開放時間帯の記録とBigQueryへの読み込み
家の3つの窓のいずれかを開けるたびに、その正確な瞬間をExcelに手入力で記録しました:
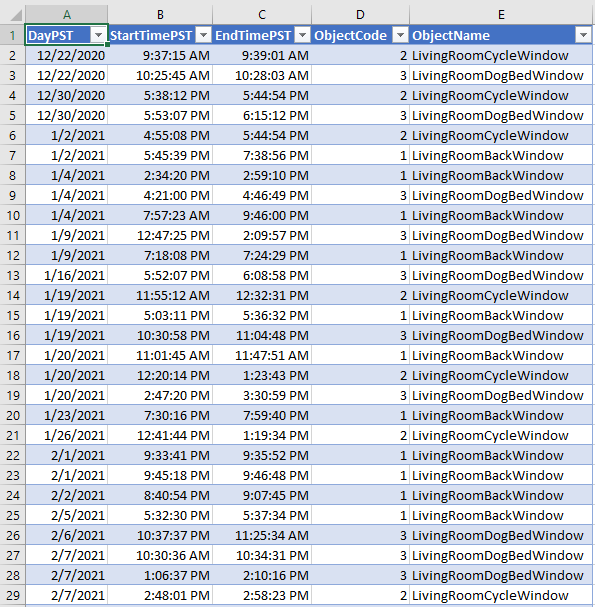
特定の窓を開けたときのPST時刻
ObjectCodeの値1〜3はそれぞれ特定の窓を表し、未指定の値0は後ですべての窓が閉まっている状態を表すために使用します。
1か月半かけて十分と思える量のデータポイントを集めたあと、これをCSVにエクスポートし、Cloud Storage(GCS)バケットへアップロードしてから、次のコマンドを実行してスキーマを自動検出させながら新しいBigQueryテーブルを作成しました:
UTCで窓の開閉時間帯のdatetimeテーブルを作成
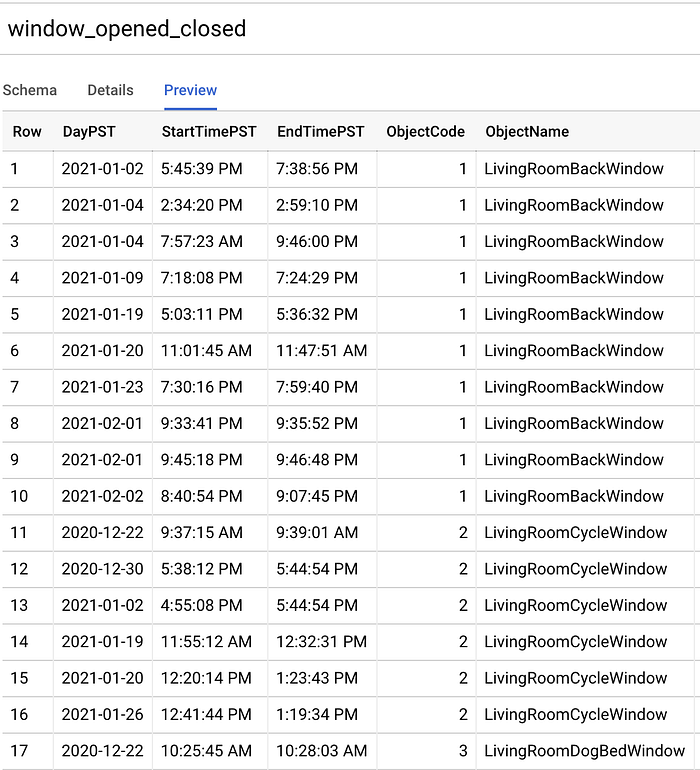
「bq load」コマンドで作成されたBigQueryテーブル「window_opened_closed」
ストリーミングデータは次のような形式で保存されているため:
- 手入力で記録したPSTではなくUTCで保存されている
- 手入力で記録した日付とタイムスタンプを別々に持つのではなく、datetime値として保存されている
次のSQLコマンドを実行し、窓の開放開始・終了時点をUTCのdatetimeに変換しました:
UTCで窓の開閉時間帯のdatetimeテーブルを作成
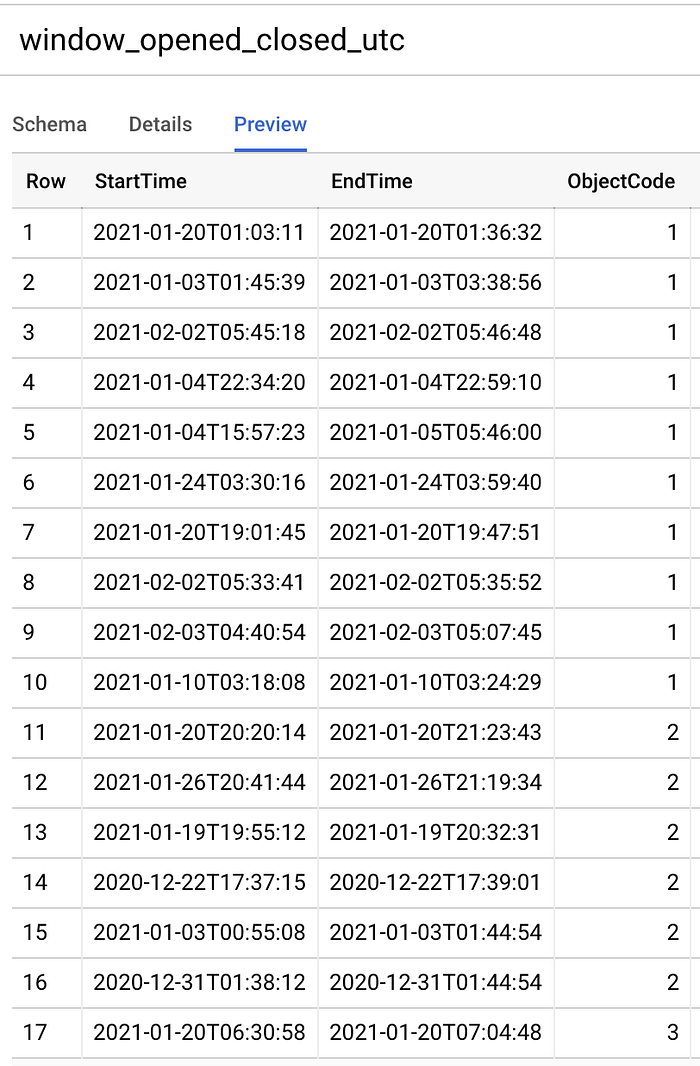
少しコンピューターに優しいタイムスタンプ
窓の開閉状態を温度の時間ポイントに結合する前に、まず生データテーブルをピボットして、特定の秒におけるすべてのセンサー値が1行に揃うようにする必要があります。
補足:ご自身のストリーミングデータではなく、私のKaggleデータセットの生温度データを使う場合は、先に進む前に以下のコマンドでCSVをプロジェクトにインポートしてください:
datetimeでピボットした温度テーブルの作成
秒単位・センサー単位の生温度データテーブルを、すべてのセンサー値が揃った秒単位の行にピボットするには、次のSQLを使います。なお、このクエリでは1つ以上のセンサーが値を記録できなかった行を除外しています。停電は何度もありましたし — クリスマス当日には家全体が1時間停電しましたし、Roombaがセンサーの電源コードに突っ込んだり、Mapleがセンサーを倒したり…想定外のことは起きるものです!
これらのnull値に妥当なデフォルト値(たとえば、そのセンサーの過去60秒間の平均値)を補完するという手もあるかもしれません。ただ、私のデータセットには約1050万行の生データがあり、モデル学習には十分すぎるほどの量です。妥当な値を推測で補うよりも、null値を含む行は学習からまるごと除外してしまうほうが賢明でしょう。
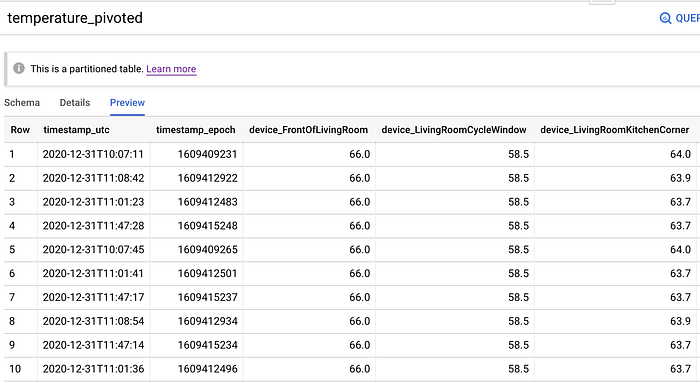
datetimeでピボットしたセンサー温度のテーブル
モデル学習を始める準備はあとわずかです!もう1つテーブルを作成する必要があり、そこには次の内容を含めます:
- 時間ポイントと既知の窓の開放状態のマージ。窓の開放状態が記録されていない時間ポイントには、デフォルトで閉鎖状態の値を割り当てます。
- 遡及的な温度値列の作成。特定の秒におけるデバイス温度を知ること自体も役立ちますが、現在値を過去のさまざまな時点と比較できるとさらに有用です。
この目的を達成するため、機械学習の学習プロセスへの入力となる最終的なBigQueryテーブルを作成する最後のSQL文を実行します。なお、これらの遡及値を取得するもっと高速な(ただしかなり高コストな)手段もあるのですが、それについては後ほど触れます。
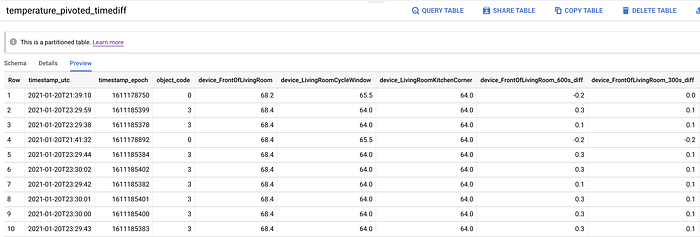
窓の開閉状態と遡及時点の列を追加した、ピボット済みの温度データ
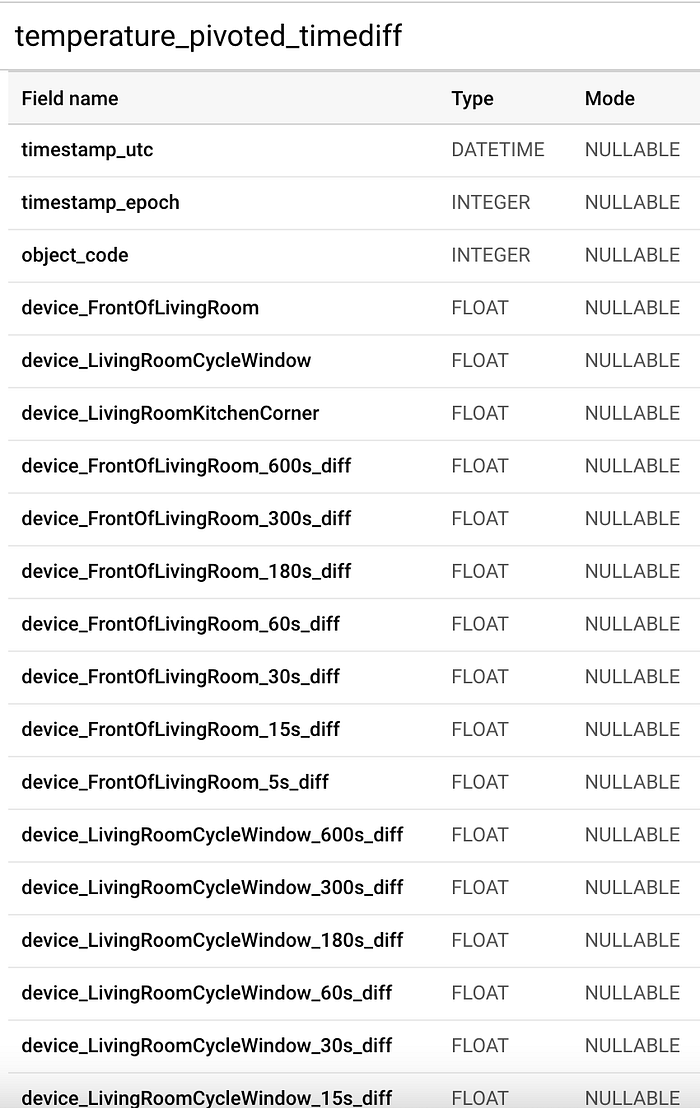
機械学習の学習プロセスへの入力となる最終テーブルの部分的なスキーマ
この最終テーブルにより、ようやくBigQuery MLモデルの学習を開始するために必要なものがすべて揃いました。
BigQuery MLによる学習
次の4行のSQL風コードは、BigQueryに以下の処理を指示します:
- GoogleのAutoML Tablesアルゴリズムを使ってMLモデルを学習する。学習が24時間を超えた場合は途中で打ち切り、その時点までに生成された最良のモデルを採用する。
- 「object_code」(窓の開閉状態)を予測対象の列とする。
- datetime以外のすべての列を特徴量として使用する。
あとはこれを実行して、完了を待つだけ。本当にこれだけです!
ピボット後のデータセットは25列・約320万行(およそ8000万セル)とかなり大規模で、AutoMLは計算コストの高いディープニューラルネットワークを多数繰り返し学習・評価していくため、完了までにはそれなりに時間がかかります。
BigQuery MLによる学習:コストへの注意
本記事執筆時点で、BigQueryのAutoML機能の料金は「1TBあたり5.00ドル + AI Platformの学習コスト」となっています。学習に使うピボットテーブルのサイズは659MBですので、安く済みそうな学習に思えるかもしれません:

BQ MLモデル生成に使用するピボットテーブルのサイズ
ところが、AutoMLはDNN学習プロセスの一環として、多数の一時データセットを作成・スキャンします。24時間で打ち切ったモデルの生成が完了したとき、処理(と請求!)されたデータ量は89TBを超えていました:

AutoMLによる24時間の学習は、想像以上に高額になります
これだけでコストは445.85ドルに達し、しかもこの金額にはBigQueryが学習でAI Platformを利用する裏側で発生する不透明な処理料金は含まれておらず、それを加えると総額は約500ドルになりました。
BQ MLをあまりお金をかけずに試したい場合は、学習時間の予算に注意してください。BUDGET_HOURSを24.0から1.0時間に変更すると、1時間41分で完了するモデルが生成され、処理量はわずか3.87TB、約19.35ドル(裏で発生する学習コンピュートコストを除く)で済みます:

AutoMLによる1時間の学習は、はるかに低コスト
BigQuery MLによる学習結果
24時間待った末に、モデルの生成が完了しました。結果はかなり印象的です!正解率(accuracy)、適合率(precision)、再現率(recall)、F1スコア、ROC AUCといった一般的な評価指標が、いずれも0.99以上の値を示しています:
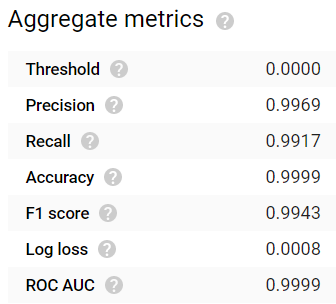
24時間学習させたモデルでは、Accuracy、Precision、Recallのいずれも高い値。なかなかの出来です!
ラベルクラスの分布は極端に偏っていて — 電気代をあまり跳ね上げたくないので、窓は開いている状態よりも閉じている状態のほうが圧倒的に多い — それでも各窓の開放状態の真陽性率(true positive rate)は非常に高くなっています。最も近いセンサーが数インチではなく約8フィート離れている3つ目の窓でさえ、真陽性検出率は97%を超えています:
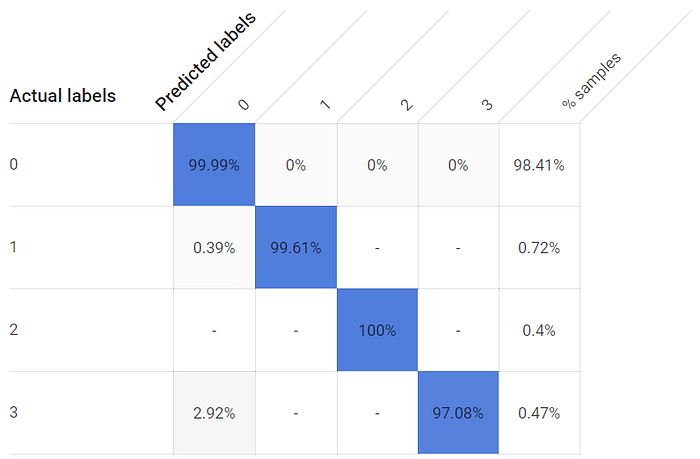
24時間学習モデルでは、窓の開閉状態の真陽性率はいずれも高水準
1時間で打ち切ったモデルでも実用に耐えるモデルは得られますが、各クラスの真陽性率は低くなり、特に温度センサーが遠くにある3つ目の窓では大きく低下します:
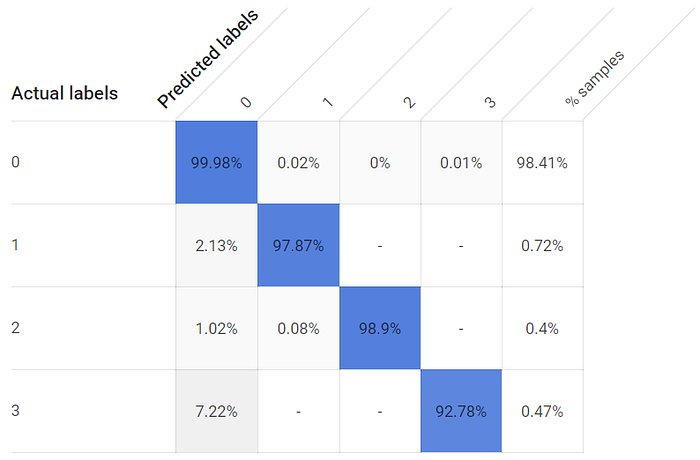
1時間学習モデルでは、窓の開閉状態の真陽性率はやや低め
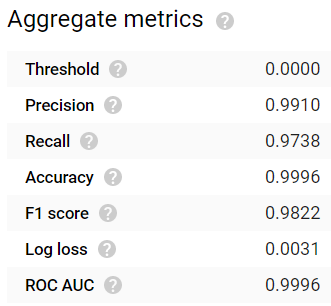
1時間学習モデルでは、AccuracyとPrecisionは高いものの、Recallは低め
BQでこれほど簡単に動くMLモデルを作れるのは確かに魅力的ですが…果たして実用的なのでしょうか?24時間モデルは本当に効果的なのでしょうか?このモデルでどうやって予測を取得すればよいのでしょうか?
BigQuery内でモデルをデプロイして予測を得るのは、生データをピボットテーブル形式に整形したあと、わずか2行のSQLを実行するだけで済みます。
BigQuery MLのデプロイと予測
次のSQLは、生のストリーミング温度データをピボットテーブル形式に整形し、それをBQ MLモデルに渡して予測を取得します。最終的にこのクエリは、過去600秒間の窓の開閉予測を返します。
このクエリをCloud Function(サーバーレスのコード実行サービス)からCloud Scheduler(cronジョブサービス)経由で60秒ごとに実行し、過去10分間の予測のうち95%以上が非ゼロ状態と判定された場合に、そのCloud Functionから「xの窓が長時間開いており閉める必要があります」というメールやテキストメッセージをすぐに送信するように構成できます。こうしたアラートの仕組みなら、窓を一時的に開けることは許容しつつ、開けっ放しの時間が長すぎるときだけ通知してくれます。
下のコードは予測を得るには分量が多く見えるかもしれませんが、最後の数行を除けばほとんどがデータ準備、つまりモデル入力に使うピボットテーブル形式へ生データを揃えるための処理です。
では、すべての窓が閉まっている状態でこのモデルがどう動作するかを見てみましょう:

9秒後、その大半はモデルによる予測ではなくデータテーブルのピボット処理に費やされていました:
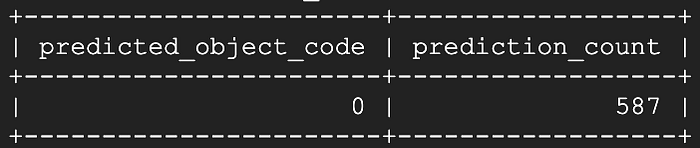
悪くない結果です!1つ以上のデバイスから直近13秒分のライブストリーミング温度値が欠けているようですが、残りの587秒はすべて閉鎖状態として正しく識別されています。
窓#1を開けて約15秒待ってから、予測スクリプトを再実行しました:
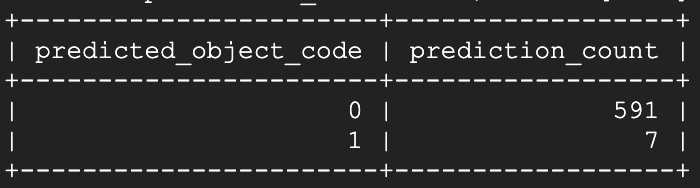
ご覧のとおり!開放してから数秒以内に、モデルはその窓を「開いている」と識別し始めました。さらに約1分半後にもう一度予測スクリプトを実行すると:
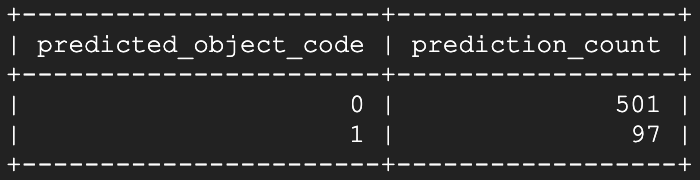
開放状態が明確かつ継続的に識別されているのが分かります!
時間が経つにつれ、10分間のウィンドウ内では開放状態の予測が閉鎖状態の予測を上回り、最終的にウィンドウ内の予測カウントを支配します。その時点で、Cloud Functionがアクションを起こし、「いい加減に窓を閉めろ!」と私自身に通知を発するように書くことができるわけです!
Cloud Functionによるメールアラート
残念ながら、Google Cloud自体はSMSやメール送信サービスを提供しておらず、サードパーティ製のサービスを使うように案内されています。Cloud Functionから外部サービスを介してメールやSMSを送る仕組みを紹介すると、コストもかさみますし、ただでさえ長い本記事をさらに長くしてしまうので、チュートリアルはここで一区切りとします。
もしお手元で利用できるメールサービスがあれば、PythonによるCloud Functionからのアラート送信には、次のようなスクリプトがうまく機能するはずです:
open_window_alert.py gistの依存ライブラリ
BigTable外部テーブルによる遡及温度の高速取得
ピボットテーブル生成SQLのかなりの部分は、各秒における「現在 − 過去の温度」の値を取得するために割かれています。こうした過去参照のINNER JOINをすべてBigQuery内で行うことは可能ですが、スケールするにつれてパフォーマンスは伸び悩みます。BigQueryは1つのテーブルに対する超大規模な分析に最適化されており、他のあらゆるデータウェアハウスと同様に、ペタバイト級のストレージと分析を実現する代償としてインデックスをサポートしないため、JOIN操作は計算コストが非常に高く、可能な限り避けたいオペレーションになります。
そこで検討したいのが、Google Cloudの大規模スケーラブルなNoSQLデータベースサービスで、個別の行クエリに対して1桁ミリ秒の応答時間を実現するBigTableのインスタンスを立ち上げ、生の温度データをこちらにも複製保存することです。BigQueryからは、BigTableインスタンスを外部テーブルとして設定し、あたかもBigQueryのテーブルのようにクエリを実行できます。
もう1つDataflowジョブを用意して、Pub/Subサブスクリプションへ届くIoTデータをBigTableへ流し込み、deviceIdとdatetimeを組み合わせた主キーを必ず使うようにすれば、特定のデバイス・特定の時点のデータポイントを、ネイティブなBigQueryテーブルから取得するBQ SQLよりはるかに高速に取得できるようになります。
このアプローチでは、ピボットテーブル生成SQLを書き換え、device-datetimeの組み合わせをJOIN ONキーとしてBigTable外部テーブルにINNER JOINする形にします。
このワークフローは理論上はよりスケーラブルで高性能になるはずですが、それなりに高額にもなります。開発テスト用の「安価な」シングルノードインスタンスでさえ、us-central1で月額468ドルかかります。それでも、本番規模でIoT運用を展開するつもりであれば、このアプローチの実装を試してみる価値はあるでしょう。
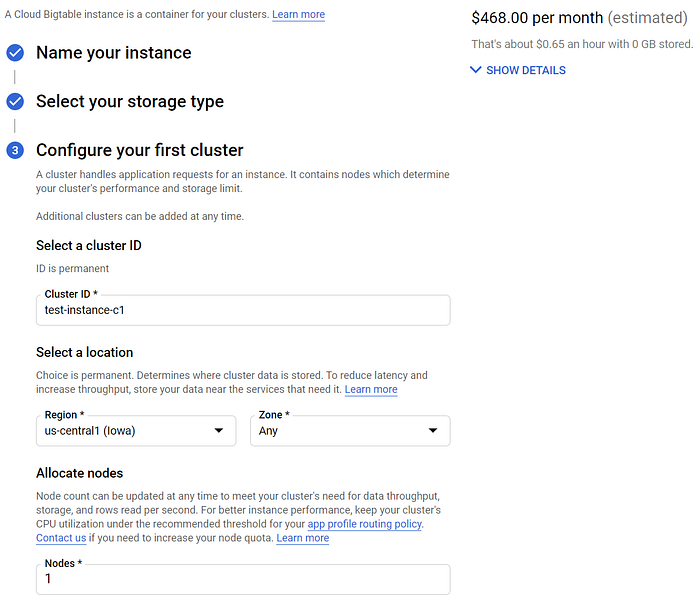
BigTableはデモのウォークスルーには高価すぎます!
GCP上でのIoTとMLに関するこの長編記事に最後までお付き合いいただき、ありがとうございました。本記事が学びにつながり、クラウド上で大規模データセットを取り込み・分析・実用化する取り組みを進めるうえでの一助になれば幸いです。フルマネージド・オートスケール・サーバーレスなサービスをできる限り活用し、クラスターの稼働維持に頭を悩ませる時間を最小化して、意味のある仕事に費やす時間を最大化していきましょう。
ここまで根気よく読んでくださったお礼に、最後にもう1枚だけかわいい子犬の写真をどうぞ!

WafflesとMaple、インスピレーションをありがとう!そして読者のみなさん、ここまで読んでくださって本当にありがとうございました!