Dieser Beitrag knüpft an Teil 1 an, in dem wir gezeigt haben, wie sich eine produktionsreife Flotte von IoT-Geräten sicher anbinden und Telemetriedaten via IoT Core und Pub/Sub in Ihre Google-Cloud-Umgebung streamen lässt, sowie an Teil 2 , in dem diese Daten nahtlos via Dataflow von Pub/Sub nach BigQuery überführt und anschließend mit Data Studio visualisiert wurden.
Wer meinen bisherigen Artikeln gefolgt ist, hat Temperatursensoren im eigenen Zuhause eingerichtet und beobachtet, wie deren Live-Daten reibungslos in GCP einfließen und schließlich in Googles Data-Warehouse-Dienst BigQuery landen. Und jetzt? Wie lassen sich diese Daten sinnvoll nutzen?
Um diese Fragen zu beantworten, möchte ich Ihnen ein konkretes Beispiel zeigen, das eines der spannendsten und leistungsfähigsten Features von BigQuery nutzt: BigQuery ML.
Falls Sie die vorherigen Artikel nicht gelesen haben – kein Problem. Ich habe meinen Datensatz auf Kaggle bereitgestellt; nutzen Sie ihn gerne, um mitzumachen.
BigQuery ML im Überblick
Anders als bei anderen Data-Warehouse-Diensten sind Training und Bereitstellung von Machine-Learning-Modellen direkt in BigQuery integriert. Beides erfolgt mit SQL-ähnlichen Befehlen, die sich einfach formulieren lassen.
Mit nur wenigen Zeilen SQL-artigem Code legen Sie den gewünschten Modelltyp fest – etwa Modelle auf Basis logistischer oder linearer Regression, k-Means-Clustering, Deep Neural Networks und so weiter. Oder Sie überlassen die Wahl Google und erstellen ein AutoML-Tables-Modell, wie wir es in diesem Artikel tun. Bei den meisten Modellen genügt es, die Label- und Feature-Spalten anzugeben.
Bevor wir uns ansehen, wie ein ML-Training in BigQuery konkret angestoßen wird, klären wir zunächst, wie sich Rohtemperaturdaten als Vorhersagemodell nutzen lassen und welche Datentransformationen vorab nötig sind. Schließlich besteht Machine Learning zu 90 % aus Datenaufbereitung.
Ziel und Methodik des Machine Learning
Während ich diesen Artikel schreibe (Februar 2021), sind es in Oregon kühle 48 Grad Fahrenheit. Die Heizung läuft auf Hochtouren und hält mich bei der Arbeit angenehm warm, aber ab und zu möchte ich ein Fenster offenlassen, um die Luft im Haus zu erneuern – vor allem, weil ich einen neun Wochen alten Corgi habe, der noch nicht ganz stubenrein ist.
Mein Ziel: Ich möchte ein Fenster öffnen können und, falls es zu lange offen bleibt, von GCP daran erinnert werden. Schließlich will ich nicht zu viel Strom verschwenden. Im Idealfall sollen mir die im Hauptwohnbereich verteilten Temperatursensoren auch verraten, welches konkrete Fenster ich schließen muss.

Das ist Maple – der süßeste Welpe, den Sie je gesehen haben. Keine Sorge, da kommt noch mehr.
Drei Sensoren streamen Temperatur-Telemetriedaten in mein GCP-Projekt; jeder ist im Hauptwohnzimmer in der Nähe eines eigenen Fensters platziert.
Zwei Sensoren sind sehr nah an ihrem jeweiligen Fenster, der dritte rund 2,5 Meter vom nächstgelegenen Fenster entfernt. Die Sensornähe spiegelt sich in den Daten wider: Ein Sensor (device_id) meldet Werte, die mehrere Grad wärmer sind als die der anderen beiden:
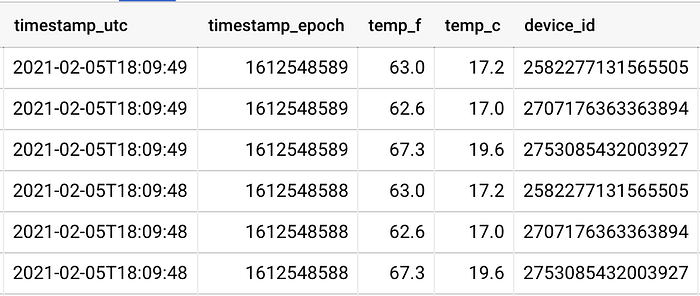
Sensor 258* und 270* befinden sich jeweils nahe am eigenen Fenster, während Sensor 275* etwa 2,5 Meter von einem dritten Fenster entfernt steht
Damit ein Machine-Learning-Modell erkennen kann, wann ein bestimmtes Fenster offen ist, sind einige Datentransformationen nötig, bis die finale Tabelle für das ML-Training bereitsteht. Für das Modelltraining brauchen wir:
- Eine Erfassung der Zeiträume, in denen ein Fenster offen ist. Ich habe die Start- und Endzeiten für "Fenster #1/2/3 ist offen" manuell in Excel eingetragen. Nicht erfasste Zeiträume gelten standardmäßig als geschlossen. Diese Tabelle wird später in CSV konvertiert und als BigQuery-Tabelle geladen.
- Eine Transformation der rohen Streaming-Tabelle: Statt einer Zeile pro Sensor und Sekunde entsteht eine pivotierte Tabelle, in der jede Sekunde eine eigene Datenzeile besitzt. Jede dieser Zeilen enthält Spalten mit der Temperatur jedes Geräts zu diesem Zeitpunkt sowie Spalten, die die Differenz zwischen dem aktuellen Sensorwert und dessen Wert vor x Sekunden ausweisen. So erfassen wir sowohl den aktuellen Temperaturwert jedes Sensors als auch dessen Veränderung gegenüber zurückliegenden Zeitintervallen: 10 Minuten, 5 Minuten, 3 Minuten, 1 Minute und so weiter bis hinunter zu 5 Sekunden. Diese Spalten liefern hervorragende Predictive Features.
- Die BQ-Tabelle mit den Zeiträumen offener und geschlossener Fenster wird mit der pivotierten Temperaturtabelle zusammengeführt. Daraus entsteht eine finale Tabelle mit unseren Predictive-Feature-Spalten zur Temperatur und einer Label-Spalte für "offenes Fenster / alle Fenster geschlossen".
Gehen wir die einzelnen Schritte kurz durch.
Zeiträume offener Fenster erfassen und in BigQuery laden
Während ich eines von drei Fenstern in meinem Haus öffnete, habe ich den genauen Zeitpunkt manuell in einer Excel-Tabelle festgehalten:
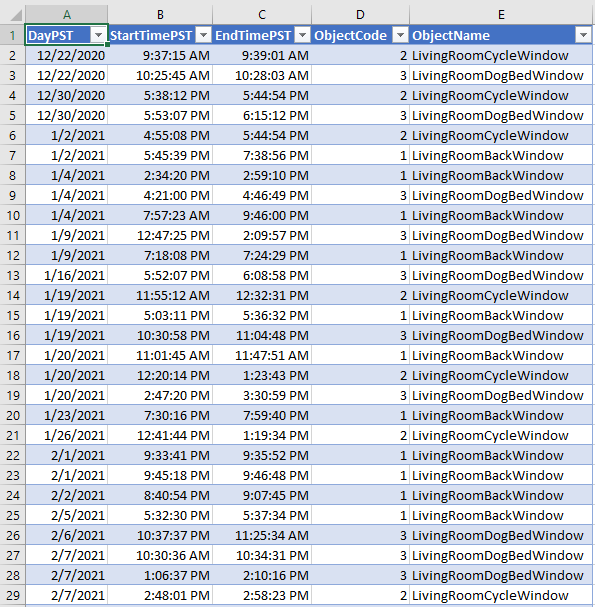
Zeiträume in PST, in denen ein bestimmtes Fenster geöffnet wurde
Hinweis: Die ObjectCode-Werte 1 bis 3 stehen jeweils für ein bestimmtes Fenster; der Wert 0 wird später dafür verwendet, dass alle Fenster geschlossen sind.
Nachdem ich über 1,5 Monate hinweg ausreichend Datenpunkte gesammelt hatte, exportierte ich diese als CSV, lud sie in einen Cloud-Storage-Bucket (GCS) hoch und führte den folgenden Befehl aus, um daraus eine neue BigQuery-Tabelle mit automatisch erkanntem Schema zu erstellen:
Tabelle der Zeiträume offener und geschlossener Fenster als Datetimes in UTC erstellen
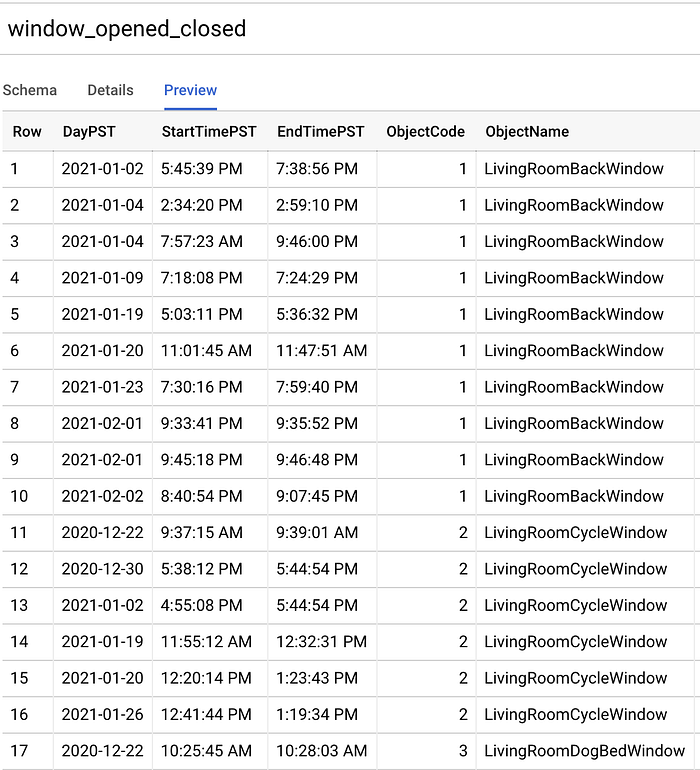
Die per "bq load"-Befehl erzeugte BigQuery-Tabelle "window_opened_closed"
Da die Streaming-Daten
- in UTC statt im manuell erfassten PST gespeichert sind und
- Datetime-Werte enthalten statt der von mir manuell erfassten getrennten Datums- und Zeitstempelwerte,
habe ich folgenden SQL-Befehl ausgeführt, um die Start- und Endzeitpunkte offener Fenster in UTC-Datetimes umzuwandeln:
Tabelle der Zeiträume offener und geschlossener Fenster als Datetimes in UTC erstellen
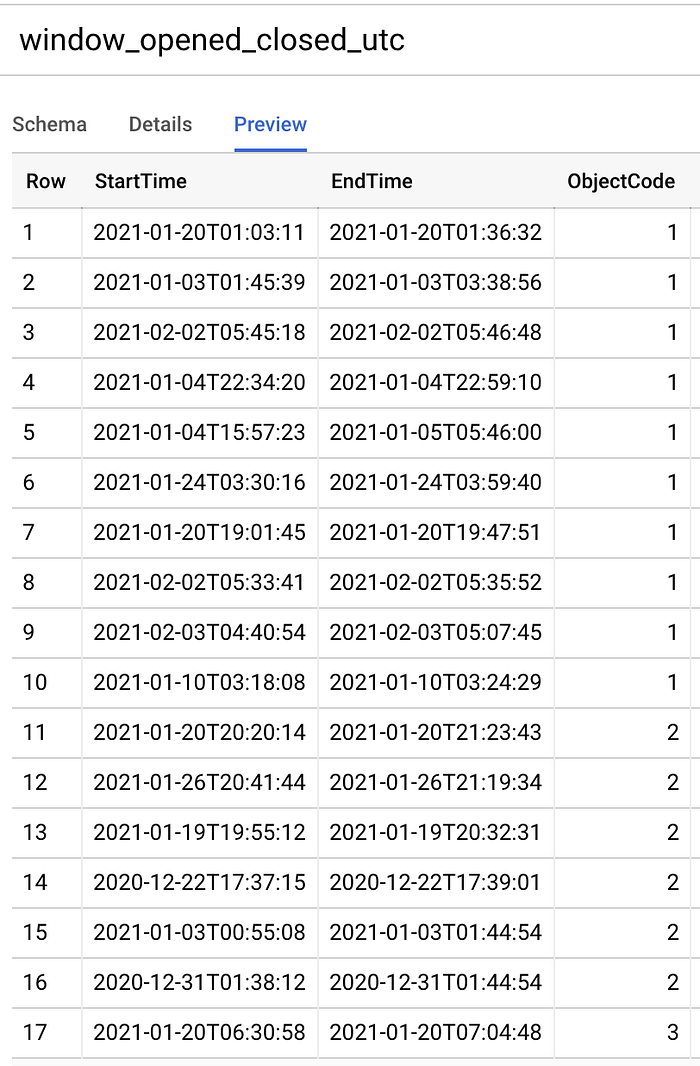
Zeitstempel, mit denen ein Computer besser umgehen kann
Bevor wir diese Offen/Geschlossen-Zustände mit den Temperatur-Zeitpunkten verknüpfen, müssen wir zunächst unsere Rohdatentabelle pivotieren, sodass alle Sensorwerte für eine gegebene Sekunde in einer einzigen Zeile vorliegen.
Hinweis am Rande: Wenn Sie statt eigener Streaming-Daten die Rohdaten aus meinem Kaggle-Datensatz verwenden, importieren Sie die CSV mit folgendem Befehl in Ihr Projekt, bevor Sie weitermachen:
Pivotierte Temperaturtabelle nach Datetime erstellen
Die Pivotierung der rohen, sekunden- und sensorbezogenen Temperaturdaten in Zeilen pro Sekunde mit allen Sensorwerten lässt sich mit folgendem SQL erreichen. Beachten Sie: In dieser Abfrage schließe ich auch Zeilen aus, in denen ein oder mehrere Sensoren keinen Wert geliefert haben. Davon gab es einige Vorfälle: am Weihnachtstag fiel im ganzen Haus eine Stunde lang der Strom aus, der Roomba ist gegen ein Sensor-Stromkabel gefahren, Maple hat einen Sensor umgestoßen … rechnen Sie immer mit dem Unerwarteten.
Sie könnten zwar versuchen, für diese Null-Werte sinnvolle Defaults zu setzen (etwa den Durchschnitt der Werte dieses Sensors über die letzten 60 Sekunden). In meinem Datensatz gibt es jedoch rund 10,5 Mio. Rohdatenzeilen – mehr als genug, um das Modell zu trainieren. Es ist daher besser, Zeilen mit Null-Werten ganz vom Training auszuschließen, statt plausible Defaults zu schätzen.
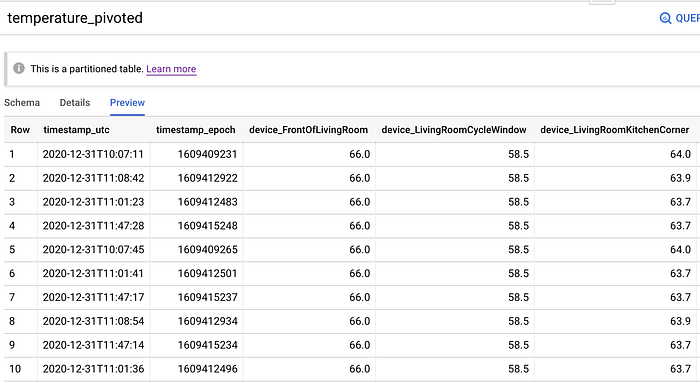
Tabelle mit nach Datetime pivotierten Sensor-Temperaturen
Wir sind fast bereit, das Modelltraining zu starten. Wir müssen nur noch eine weitere Tabelle erstellen, die Folgendes enthält:
- Eine Verknüpfung der Zeitpunkte mit den bekannten Zuständen offener Fenster. Alle Zeitpunkte ohne offenen Fensterzustand erhalten standardmäßig den Zustand "geschlossen".
- Spalten mit retrospektiven Temperaturwerten. Es ist zwar nützlich, die Gerätetemperatur für eine bestimmte Sekunde zu kennen, doch noch wertvoller ist der Vergleich des aktuellen Werts mit verschiedenen vergangenen Zeitpunkten.
Dazu führe ich ein letztes SQL-Statement aus, das die finale BigQuery-Tabelle erzeugt – sie dient als Input für unseren Machine-Learning-Trainingsprozess. Übrigens gibt es einen deutlich schnelleren, aber auch erheblich teureren Weg, an diese retrospektiven Werte zu kommen; dazu später mehr.
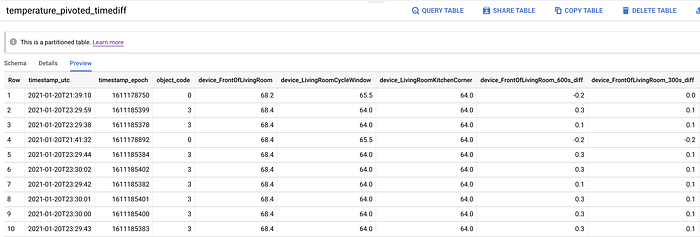
Pivotierte Temperaturdaten, ergänzt um Spalten für den Offen/Geschlossen-Zustand und retrospektive Zeitpunkte
Teilschema der finalen Tabelle, die als Input für den Machine-Learning-Trainingsprozess dient
Mit dieser finalen Tabelle haben wir endlich alles beisammen, was wir brauchen, um ein BigQuery-ML-Modell zu trainieren.
BigQuery-ML-Training
Die folgenden vier Zeilen SQL-ähnlichen Codes weisen BigQuery an:
- ein ML-Modell mit Googles AutoML-Tables-Algorithmus zu trainieren. Dauert dies länger als 24 Stunden, soll das Training abgebrochen und mit dem bisher besten Modell weitergearbeitet werden.
- "object_code" (Offen/Geschlossen-Zustand des Fensters) als vorherzusagende Spalte zu verwenden.
- alle übrigen Spalten – außer den Datetimes – als Features zu nutzen.
Ausführen, abwarten, fertig. Wirklich!
Der pivotierte Datensatz ist mit 25 Spalten und rund 3,2 Mio. Zeilen, also etwa 80 Mio. Datenzellen, recht groß. Da AutoML zudem zahlreiche rechenintensive Deep Neural Networks wiederholt trainiert und evaluiert, wird das Training einige Zeit in Anspruch nehmen.
BigQuery-ML-Training: Kostenwarnung
Zum Zeitpunkt der Erstellung dieses Artikels wird BigQuerys AutoML-Feature mit "5,00 USD pro TB zuzüglich AI-Platform-Trainingskosten" abgerechnet. Man könnte erwarten, dass dies ein vergleichsweise günstiger Trainingsvorgang ist, da unsere pivotierte Tabelle nur 659 MB groß ist:

Größe der pivotierten Tabelle, die für die BQ-ML-Modellgenerierung verwendet wird
Allerdings erstellt und scannt AutoML im Rahmen des DNN-Trainings zahlreiche temporäre Datasets. Als das auf 24 Stunden begrenzte Modell schließlich fertig war, hatte es mehr als 89 TB an Daten verarbeitet – und in Rechnung gestellt:

Ein 24-stündiges AutoML-Training ist deutlich teurer, als man erwarten würde
Das ergibt Kosten von 445,85 USD – noch ohne die verdeckten Verarbeitungsgebühren, die BigQuery hinter den Kulissen über die AI Platform für das Training in Rechnung stellt und die die Gesamtkosten auf rund 500 USD trieben.
Wenn Sie BQ ML testen möchten, ohne viel Geld auszugeben, kalkulieren Sie die angesetzten Trainingsstunden vorsichtig. Eine Reduzierung von BUDGET_HOURS von 24,0 auf 1,0 Stunden ergibt ein Modell, das in 1 h 41 min fertig ist und nur 3,87 TB verarbeitet hat – also etwa 19,35 USD (zzgl. der versteckten Trainings-Compute-Kosten):

Ein einstündiges AutoML-Training ist deutlich günstiger
Ergebnisse des BigQuery-ML-Trainings
Nach 24 Stunden Wartezeit war das Modell fertig. Die Ergebnisse sind beeindruckend: Gängige Bewertungsmetriken wie Accuracy, Precision, Recall, F1-Score und ROC-AUC liefern allesamt Werte ≥ 0,99:
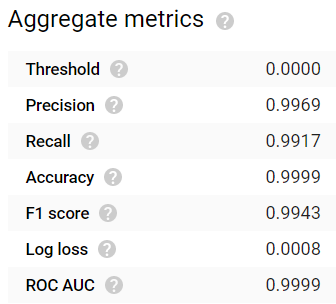
Hohe Accuracy-, Precision- und Recall-Werte beim 24 Stunden trainierten Modell. Wirklich nicht schlecht!
Trotz der stark unausgewogenen Verteilung zwischen den Label-Klassen – Fenster sind weit häufiger geschlossen als offen, schließlich will ich meine Stromrechnung nicht in die Höhe treiben – erreichen die Zustände der offenen Fenster ausgesprochen hohe True-Positive-Raten. Selbst das dritte Fenster, dessen nächstgelegener Sensor rund 2,5 Meter (statt nur Zentimeter) entfernt steht, kommt auf eine True-Positive-Rate von > 97 %:
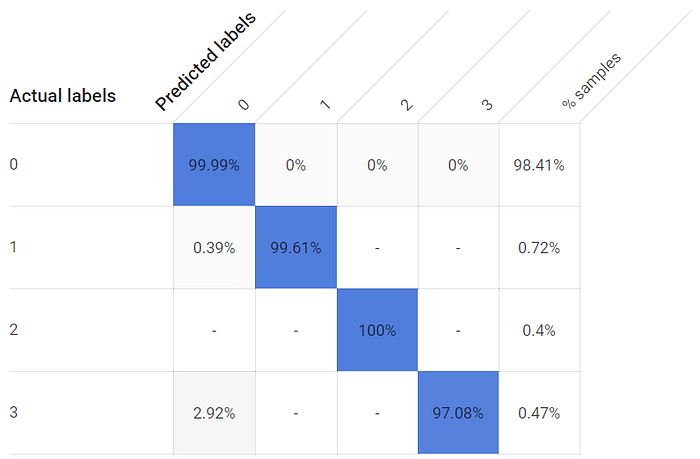
True-Positive-Raten für offene und geschlossene Fenster sind beim 24 Stunden trainierten Modell hoch
Ein Modell mit einstündigem Cutoff ist ebenfalls brauchbar, allerdings sind die TP-Raten der einzelnen Klassen niedriger – beim dritten Fenster mit dem entfernteren Sensor sogar deutlich:
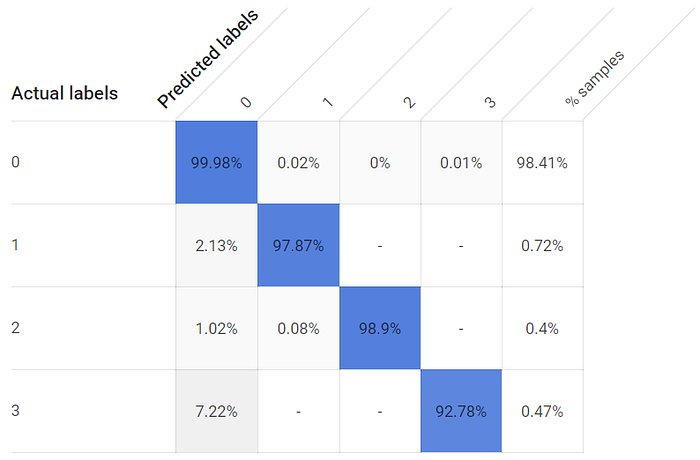
True-Positive-Raten für offene und geschlossene Fenster fallen beim einstündig trainierten Modell niedriger aus
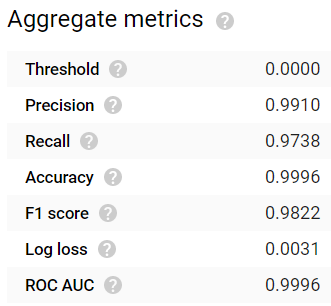
Hohe Accuracy- und Precision-, aber niedrigere Recall-Werte beim einstündig trainierten Modell
Es ist beeindruckend, wie einfach sich mit BQ ein funktionsfähiges ML-Modell bauen lässt – aber ist es auch nützlich? Ist das 24-Stunden-Modell wirklich effektiv? Und wie kommen wir mit diesem Modell an Vorhersagen?
Das Modell in BigQuery bereitzustellen und Vorhersagen zu erzeugen, ist so einfach wie das Ausführen von zwei Zeilen SQL-Code – sobald Sie Ihre Rohdaten zurück ins pivotierte Tabellenformat gebracht haben.
BigQuery-ML-Bereitstellung und Vorhersagen
Das folgende SQL überführt rohe Streaming-Temperaturen in das pivotierte Tabellenformat und speist sie für Vorhersagen in das BQ-ML-Modell ein. Im Ergebnis liefert die Abfrage Offen/Geschlossen-Vorhersagen für die letzten 600 Sekunden.
Würde diese Abfrage aus einer Cloud Function (einem Serverless-Code-Dienst) alle 60 Sekunden via Cloud Scheduler (einem Cronjob-Dienst) ausgeführt und wären ≥ 95 % der Vorhersagen der letzten 10 Minuten in einem Nicht-Null-Zustand, könnten Sie die Cloud Function so einrichten, dass sie sofort eine E-Mail oder SMS verschickt – mit dem Hinweis, dass Fenster x zu lange offen ist und geschlossen werden muss. Ein solches Alerting erlaubt kurzes Lüften und meldet sich erst, wenn das Fenster wirklich zu lange offen bleibt.
Das folgende Beispiel mag nach viel Code für eine Vorhersage aussehen, doch alles bis auf die letzten paar Zeilen ist reine Datenaufbereitung – das Zusammenführen der Rohdaten in das richtige pivotierte Tabellenformat als Modell-Input.
Sehen wir uns an, wie sich das Modell verhält, wenn alle Fenster geschlossen sind:

Neun Sekunden später – der Großteil davon entfiel auf das Pivotieren der Tabelle, nicht auf die Modellvorhersage:
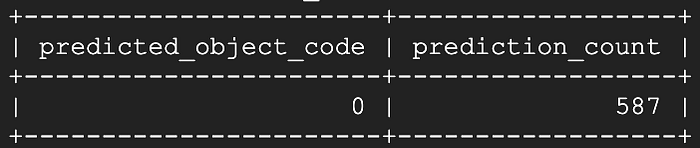
Wirklich nicht schlecht! Es scheint, dass uns die letzten 13 Live-Streaming-Sekunden mit Temperaturwerten von einem oder mehreren Geräten fehlen; die übrigen 587 Sekunden werden korrekt als "geschlossen" erkannt.
Nachdem ich Fenster #1 geöffnet und etwa 15 Sekunden gewartet hatte, ließ ich das Vorhersage-Skript erneut laufen:
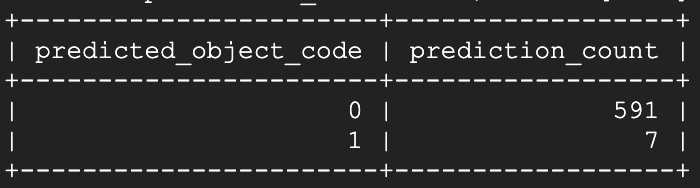
Voilà! Innerhalb weniger Sekunden nach dem Öffnen erkennt das Modell genau dieses Fenster als offen. Etwa eineinhalb Minuten später startete ich das Vorhersage-Skript erneut:
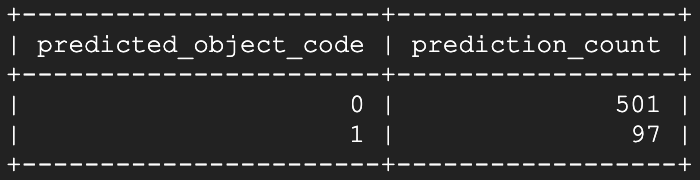
Wir sehen: Der Offen-Zustand wird klar und kontinuierlich erkannt!
Mit der Zeit überwiegt der Offen-Zustand die Geschlossen-Vorhersagen im 10-Minuten-Fenster, bis er den Zähler dominiert. An diesem Punkt könnte eine Cloud Function aktiv werden und mir eine Benachrichtigung schicken, das verflixte Fenster endlich zu schließen!
E-Mail-Alerting mit einer Cloud Function
Leider bietet Google Cloud weder SMS- noch E-Mail-Dienste an, sondern verweist Kunden auf Drittanbieter. Eine Demo für E-Mail oder SMS via Cloud Function mit einem externen Dienst wäre kostspielig und würde diesen ohnehin langen Artikel weiter strecken – daher beenden wir das Tutorial an dieser Stelle.
Falls Ihnen ein E-Mail-Dienst zur Verfügung steht, eignet sich ein Skript ähnlich dem folgenden gut für das Alerting via Python-Cloud-Function:
Anforderungen für das Gist "open_window_alert.py"
Schneller Abruf retrospektiver Temperaturen über eine externe BigTable-Tabelle
Ein erheblicher Teil des SQL für die pivotierte Tabelle ist dem Abruf der Werte "aktuell minus vergangen" für jede einzelne Sekunde gewidmet. Diese rückblickenden INNER JOINs vollständig in BigQuery durchzuführen, ist zwar möglich, aber im großen Maßstab nicht besonders performant. BigQuery ist primär auf Massive-Scale-Analytics auf einer einzelnen Tabelle optimiert. Wie alle Data Warehouses unterstützt es keine Indizes – das ist der Preis für Petabyte-fähige Speicherung und Analyse – und macht JOIN-Operationen entsprechend rechenintensiv. Sie sollten deshalb vermieden werden, wo immer möglich.
Eine Überlegung wert ist daher BigTable, Google Clouds extrem skalierbarer NoSQL-Datenbankdienst, der einstellige Millisekunden-Antwortzeiten für Einzelzeilenabfragen bietet. Dort lassen sich Ihre rohen Temperaturdaten zusätzlich speichern. In BigQuery können Sie eine BigTable-Instanz als externe Tabelle einbinden und anschließend Abfragen darauf ausführen, als wäre es eine BigQuery-Tabelle.
Wenn Sie zudem einen zweiten Dataflow-Job einrichten, der Ihre IoT-Daten aus einer PubSub-Subscription nach BigTable schreibt – mit einem Primärschlüssel aus deviceId und Datetime –, lassen sich einzelne Zeitpunkte für ein bestimmtes Gerät deutlich schneller abrufen, als BQ SQL es bei reinen BigQuery-Tabellen leisten kann.
Mit diesem Ansatz würden Sie Ihr SQL zur Erzeugung der pivotierten Tabelle so anpassen, dass es per INNER JOIN auf die externe BigTable-Tabelle zugreift – mit der Kombination aus Device und Datetime als JOIN-ON-Schlüssel.
Theoretisch sollte dieser Workflow besser skalieren und sehr performant sein, ist aber auch deutlich teurer. Selbst eine "günstige" Single-Node-Instanz für Entwicklungstests schlägt in us-central1 mit 468 USD pro Monat zu Buche. Trotzdem lohnt es sich, diesen Ansatz auszuprobieren, wenn Sie IoT-Operationen im großen Maßstab betreiben möchten.
BigTable ist für eine Demo zu kostspielig!
Glückwunsch, dass Sie diesem Deep Dive zu IoT und ML auf GCP bis zum Ende gefolgt sind. Ich hoffe, er war lehrreich und hat Sie auf Ihrem Weg vorangebracht, große Datensätze in der Cloud zu erfassen, zu analysieren und sinnvoll zu nutzen – mit so vielen vollständig gemanagten, automatisch skalierenden Serverless-Diensten wie möglich, damit Sie weniger Zeit mit der Cluster-Uptime verbringen und mehr Zeit haben, sinnvolle Arbeit zu erledigen.
Als Belohnung für Ihre Geduld und Ausdauer kann ich zumindest noch ein letztes süßes Welpenfoto anbieten!

Danke für die Inspiration, Waffles und Maple! Und vielen Dank an SIE für all Ihre harte Arbeit!