Cet article fait suite à la Partie 1, qui détaillait comment intégrer en toute sécurité une flotte d'appareils IoT à grande échelle envoyant des données de télémétrie vers votre environnement Google Cloud via IoT Core et Pub/Sub, ainsi qu'à la Partie 2, où ces données transitaient sans accroc de Pub/Sub vers BigQuery via Dataflow, avant d'être visualisées dans Data Studio.
Si vous avez suivi mes articles précédents, vous avez pu installer des capteurs de température dans toute votre maison et observer leurs données diffusées en direct s'écouler vers GCP, pour finir dans BigQuery, l'entrepôt de données de Google. Et maintenant ? Comment tirer parti concrètement de ces données ?
Pour répondre à ces questions, j'aimerais vous présenter un exemple concret reposant sur l'une des fonctionnalités les plus singulières et puissantes de BigQuery : BigQuery ML.
Si vous n'avez pas suivi les articles précédents, pas d'inquiétude ! J'ai mis mon jeu de données à disposition sur Kaggle ; n'hésitez pas à l'utiliser pour suivre la démarche.
Vue d'ensemble de BigQuery ML
Contrairement à d'autres services d'entrepôt de données, l'entraînement et le déploiement de modèles de machine learning sont directement intégrés à BigQuery. Les deux opérations s'effectuent à l'aide de commandes de type SQL, simples à écrire.
Avec seulement quelques lignes de code à la syntaxe SQL, vous pouvez spécifier le type de modèle à créer : régression logistique ou linéaire, k-means clustering, réseaux de neurones profonds, etc. Vous pouvez aussi laisser Google s'en charger en créant un modèle AutoML Tables, comme nous le ferons dans cet article. La plupart des modèles ne nécessitent aucune autre indication que les colonnes de label et de features.
Avant de plonger dans les détails de l'entraînement ML au sein de BigQuery, il faut d'abord déterminer comment des données brutes de température peuvent servir de modèle prédictif et quelles transformations doivent précéder la construction du modèle. Le machine learning, c'est 90 % de préparation des données, après tout.
Objectif et méthodologie de machine learning
Au moment où j'écris ces lignes (février 2021), il fait 48 °F (environ 9 °C) en Oregon. Le chauffage tourne à plein régime pour me garder bien au chaud pendant que je travaille, mais j'aimerais bien, de temps en temps, ouvrir une fenêtre pour renouveler l'air — surtout que j'ai un Corgi de neuf semaines pas encore tout à fait propre !
L'idée, c'est de pouvoir ouvrir une fenêtre et, si elle reste ouverte trop longtemps, que GCP me rappelle qu'elle l'est encore. Pas question de gaspiller trop d'électricité ! Et, si possible, j'aimerais que les capteurs de température répartis dans la pièce de vie principale m'indiquent aussi quelle fenêtre précisément fermer.

Voici Maple ! Le chiot le plus mignon que vous ayez jamais vu. Rassurez-vous, il y en aura d'autres.
Trois capteurs envoient en streaming des données de télémétrie de température vers mon projet GCP, chacun positionné près d'une fenêtre dans le salon principal de ma maison.
Deux capteurs sont très proches de leur fenêtre respective, tandis qu'un troisième se trouve à environ 2,5 mètres de la fenêtre la plus proche. Cette proximité se reflète dans les données : un capteur (device_id) affiche des valeurs supérieures de plusieurs degrés aux deux autres :
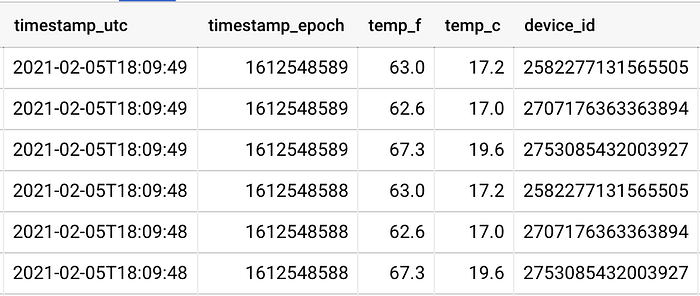
Les capteurs 258* et 270* sont placés près de leur fenêtre, tandis que le capteur 275* se trouve à environ 2,5 mètres de la troisième fenêtre.
Pour construire un modèle de machine learning capable de détecter l'ouverture d'une fenêtre précise, il faut enchaîner plusieurs étapes de transformation afin d'obtenir la table finale prête pour l'entraînement. L'entraînement nécessite :
- Le suivi des plages horaires durant lesquelles une fenêtre est ouverte. J'ai saisi manuellement dans Excel les heures de début et de fin pour fenêtre n°1/2/3 ouverte. Les plages horaires non suivies sont considérées comme correspondant à des fenêtres fermées. Cette table sera ensuite convertie en CSV puis chargée comme table BigQuery.
- La transformation de la table brute des températures en streaming, où chaque ligne contient une valeur de température propre à un capteur pour une seconde donnée, en une table pivotée où chaque seconde dispose de sa propre ligne. Chaque ligne par seconde aura des colonnes contenant la température de chaque appareil à cet instant, ainsi que des colonnes affichant l'écart entre la valeur actuelle d'un capteur et sa valeur x secondes auparavant. L'objectif : suivre la valeur actuelle de chaque capteur ainsi que son évolution sur différents intervalles passés (10 minutes, 5 minutes, 3 minutes, 1 minute, jusqu'à 5 secondes auparavant). Ces colonnes feront d'excellentes features prédictives.
- La table BQ définissant les plages d'ouverture et de fermeture des fenêtres doit être fusionnée avec la table de température pivotée, ce qui nous donne une table finale contenant nos colonnes de features prédictives de température et une colonne de label fenêtre ouverte / toutes fenêtres fermées.
Passons rapidement en revue chacune de ces étapes.
Suivi des plages d'ouverture des fenêtres et chargement dans BigQuery
Au fil de l'ouverture des trois fenêtres de ma maison, j'ai noté manuellement le moment précis dans une table Excel :
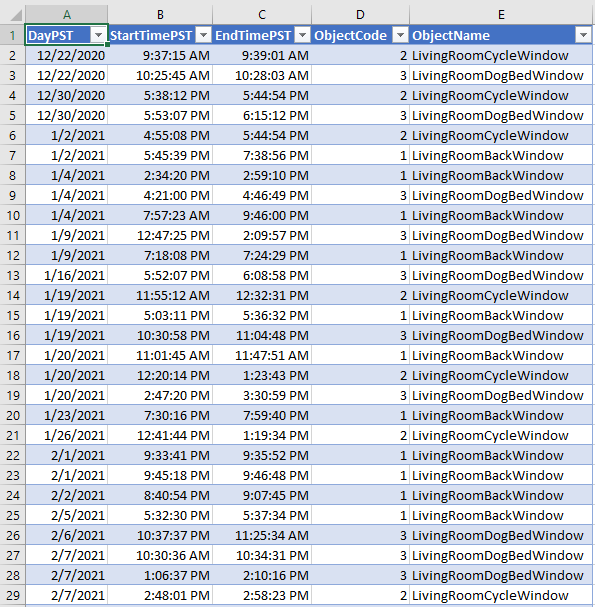
Plages horaires (heure du Pacifique) durant lesquelles une fenêtre spécifique a été ouverte.
Notez que les valeurs ObjectCode de un à trois représentent chacune une fenêtre spécifique, tandis qu'une valeur non spécifiée de zéro servira plus tard à représenter le cas où toutes les fenêtres sont fermées.
Après avoir collecté ce que j'estimais être suffisamment de points de données sur 1,5 mois, j'ai exporté le tout en CSV, téléversé ce CSV dans un bucket Cloud Storage (GCS), puis exécuté la commande suivante pour créer une nouvelle table BigQuery avec détection automatique du schéma :
Création d'une table des plages horaires d'ouverture et de fermeture en UTC.
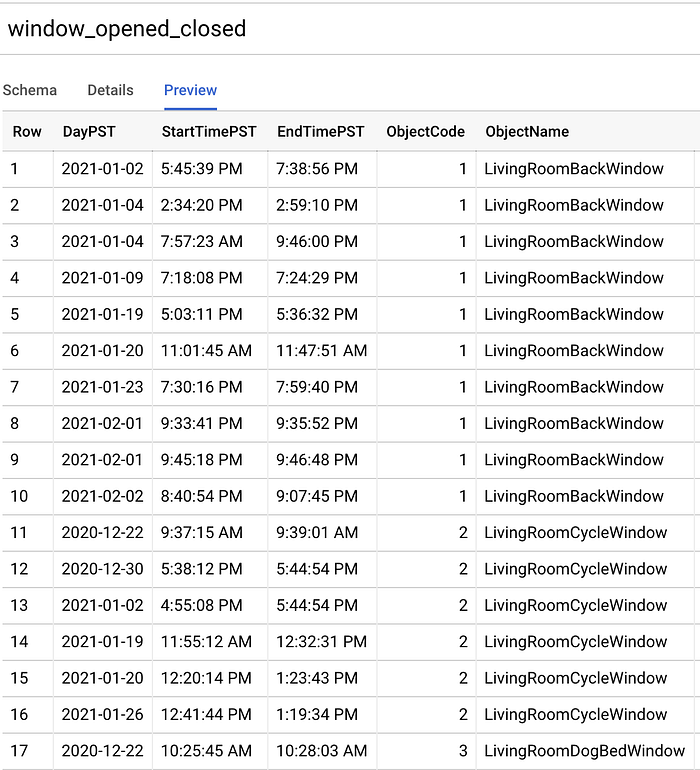
Table BigQuery window_opened_closed créée à partir de la commande bq load.
Comme les données en streaming sont :
- Stockées en UTC plutôt qu'à l'heure du Pacifique que j'ai notée manuellement, et
- Stockées sous forme de valeurs datetime plutôt que de valeurs date et timestamp séparées comme je les ai notées manuellement
J'ai exécuté la commande SQL suivante pour convertir les heures de début et de fin d'ouverture des fenêtres en datetimes au standard universel :
Création d'une table des plages horaires d'ouverture et de fermeture en UTC.
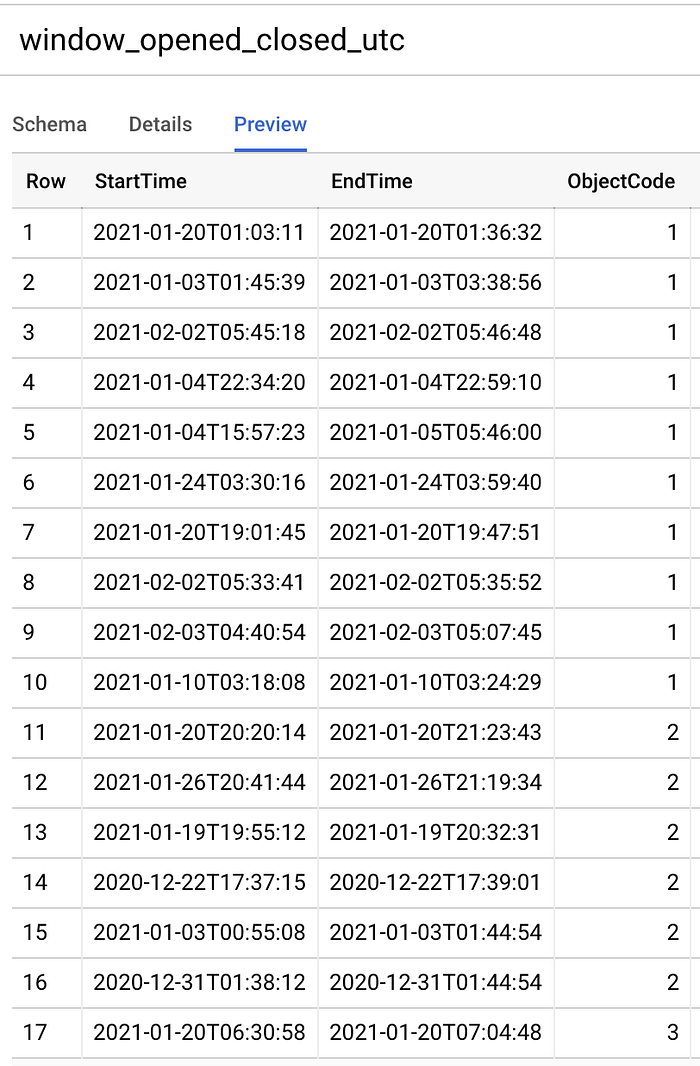
Des timestamps un peu plus exploitables par la machine.
Avant de joindre ces états ouvert/fermé aux points temporels de température, nous devons d'abord pivoter notre table de données brutes pour que toutes les valeurs des capteurs pour une seconde donnée tiennent sur une seule ligne.
Note : si vous travaillez avec les données brutes de température de mon jeu de données Kaggle plutôt qu'avec vos propres données en streaming, utilisez ce qui suit pour importer ce CSV dans votre projet avant de continuer :
Création de la table de température pivotée par datetime
Le pivotement de la table brute (température par seconde et par capteur) en lignes par seconde contenant toutes les valeurs des capteurs s'effectue avec la requête SQL suivante. Notez que dans cette requête, j'exclus également les lignes pour lesquelles un ou plusieurs capteurs n'ont pas réussi à enregistrer une valeur. Il y a eu de nombreuses occurrences où le courant a sauté — toute la maison pendant une heure le jour de Noël, le Roomba qui percute un cordon d'alimentation, Maple qui renverse un capteur… il faut s'attendre à l'inattendu !
Vous pourriez vous en sortir en imputant des valeurs par défaut raisonnables à ces valeurs nulles (par exemple la moyenne des valeurs du capteur sur les 60 dernières secondes). Toutefois, mon jeu de données comporte environ 10,5 M de lignes brutes, ce qui suffit largement pour entraîner le modèle. Mieux vaut sans doute exclure ces lignes de l'entraînement plutôt que de tenter une estimation approximative.
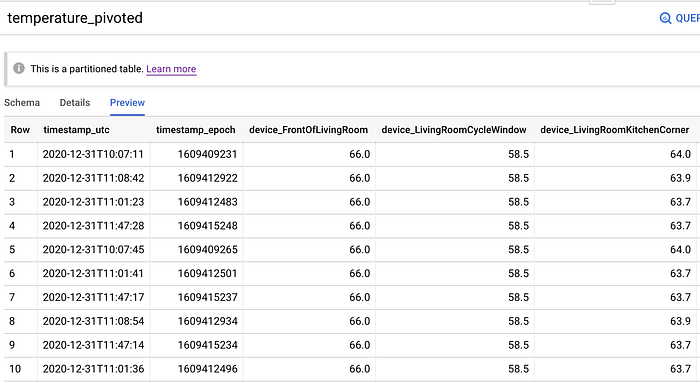
Table des températures de capteurs pivotée par datetime.
Nous sommes presque prêts à entraîner notre modèle ! Il ne nous reste qu'une table à créer, contenant les éléments suivants :
- Une fusion des points temporels avec les états connus d'ouverture des fenêtres. Tous les points temporels sans état d'ouverture associé reçoivent par défaut un état fermé.
- La création de colonnes de valeurs de température rétrospectives. Connaître la température d'un appareil à une seconde donnée est utile, mais comparer la valeur actuelle à différents points temporels passés l'est encore davantage.
Pour atteindre ces objectifs, j'exécute une dernière requête SQL qui crée la table BigQuery finale, qui servira d'entrée à notre processus d'entraînement de machine learning. À noter qu'il existe un moyen bien plus rapide, mais nettement plus coûteux, d'obtenir ces valeurs rétrospectives — nous y reviendrons plus tard.
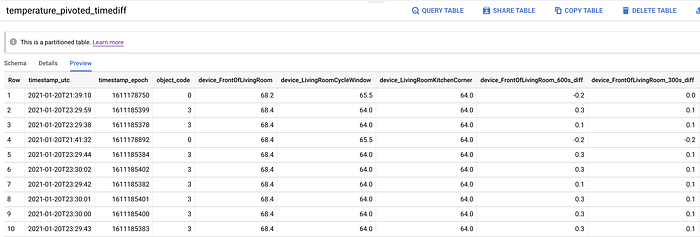
Données de température pivotées, avec les colonnes ajoutées pour l'état ouvert/fermé des fenêtres et les points temporels rétrospectifs.
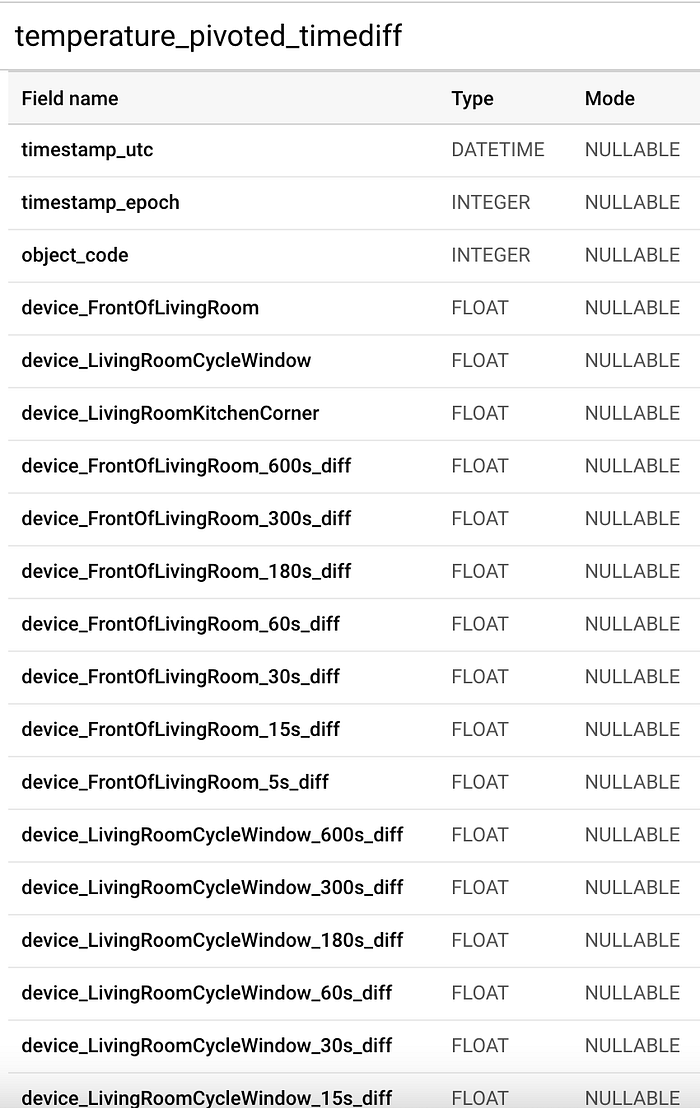
Schéma partiel de la table finale servant d'entrée au processus d'entraînement de machine learning.
Avec cette table finale, nous avons enfin tout ce qu'il faut pour entraîner un modèle BigQuery ML.
Entraînement BigQuery ML
Les quatre lignes de code de type SQL suivantes indiquent à BigQuery de :
- Entraîner un modèle ML à l'aide de l'algorithme AutoML Tables de Google. Si l'opération dépasse 24 heures, l'interrompre et utiliser le meilleur modèle généré jusque-là.
- Utiliser object_code (état ouvert/fermé de la fenêtre) comme colonne à prédire.
- Utiliser toutes les autres colonnes comme features, à l'exception des datetimes.
Lancez la requête, attendez qu'elle se termine, et c'est tout. Sérieusement !
Étant donné que le jeu de données pivoté est plutôt volumineux — 25 colonnes et environ 3,2 M de lignes, soit près de 80 M de cellules — et qu'AutoML entraîne et évalue de manière répétée une multitude de réseaux de neurones profonds gourmands en calcul, l'opération prendra un certain temps.
Entraînement BigQuery ML : attention aux coûts
Au moment de la rédaction de cet article, la fonctionnalité AutoML de BigQuery est facturée 5,00 $ par To, plus le coût d'entraînement AI Platform. On pourrait s'attendre à une opération d'entraînement assez bon marché vu que la table pivotée sur laquelle on entraîne ne pèse que 659 Mo :

Taille de la table pivotée utilisée pour la génération du modèle BQ ML.
Sauf qu'AutoML crée et analyse de nombreux jeux de données temporaires dans le cadre de son processus d'entraînement de DNN. Lorsque le modèle limité à 24 heures a enfin terminé sa génération, il avait traité (et facturé !) plus de 89 To de données :

Un entraînement AutoML de 24 heures coûte bien plus cher qu'on ne l'imagine.
Cela représente un coût de 445,85 $, sans compter les frais de traitement opaques facturés en coulisse par BigQuery via AI Platform pour son entraînement, ce qui porte le coût total à environ 500 $.
Si vous comptez tester BQ ML sans dépenser une fortune, soyez prudent quant au nombre d'heures d'entraînement budgétées. Faire passer BUDGET_HOURS de 24,0 à 1,0 heure produit un modèle qui se termine en 1h41 et n'a traité que 3,87 To, soit environ 19,35 $ (plus les coûts de calcul d'entraînement masqués) :

Un entraînement AutoML d'une heure revient nettement moins cher.
Résultats de l'entraînement BigQuery ML
Après 24 heures d'attente, le modèle est généré. Les résultats sont assez impressionnants ! Les métriques d'évaluation classiques (accuracy, précision, rappel, score F1, ROC AUC) affichent toutes des valeurs ≥ 0,99 :
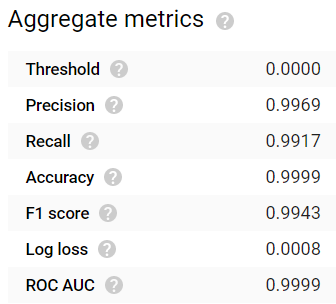
Excellentes valeurs d'accuracy, de précision et de rappel pour un modèle entraîné sur 24 heures. Pas mal du tout !
Malgré une représentation extrêmement déséquilibrée entre les classes de label — les fenêtres restent fermées bien plus souvent qu'ouvertes, car je tiens à ne pas trop faire grimper ma facture d'électricité — chaque état de fenêtre ouverte affiche tout de même un taux de vrais positifs très élevé. Même la troisième fenêtre, dont le capteur le plus proche se trouve à environ 2,5 mètres plutôt qu'à quelques centimètres, atteint un taux de détection des vrais positifs supérieur à 97 % :
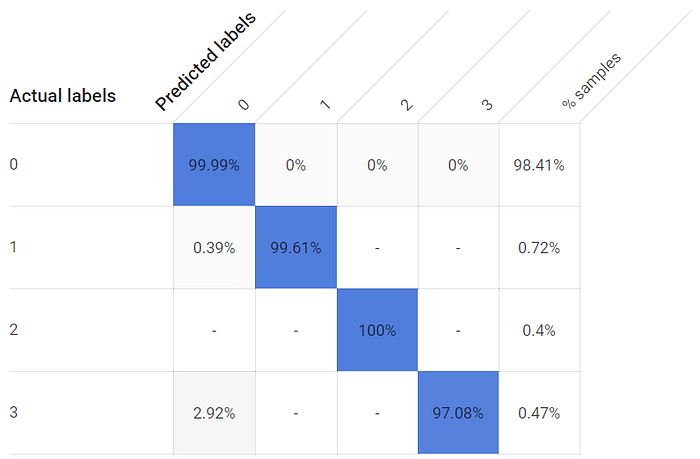
Les taux de vrais positifs pour les états ouvert et fermé sont élevés avec un modèle entraîné sur 24 heures.
La génération d'un modèle limité à une heure produit un modèle exploitable, même si les taux de vrais positifs des classes individuelles sont plus faibles, et nettement plus pour la troisième fenêtre dont le capteur de température est plus éloigné :
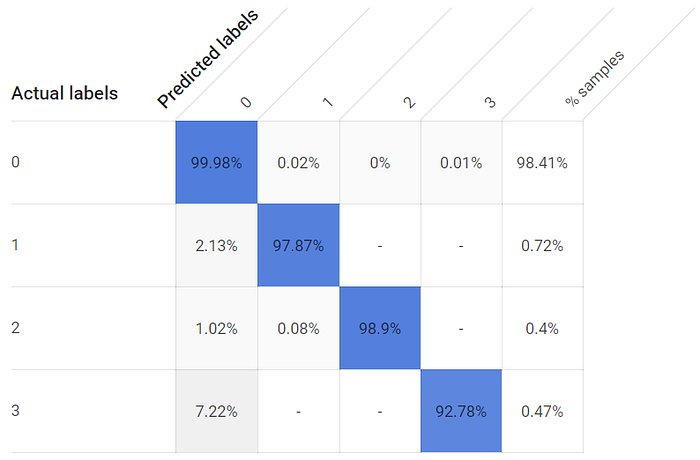
Les taux de vrais positifs des états ouvert et fermé sont plus faibles avec un modèle entraîné sur une heure.
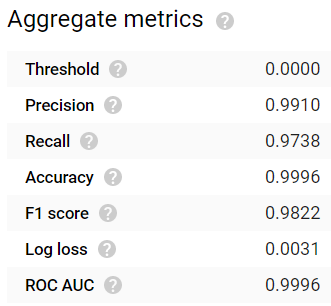
Bonne accuracy et bonne précision, mais un rappel plus faible avec un modèle entraîné sur une heure.
C'est plutôt bluffant de voir à quel point il est facile de construire un modèle ML fonctionnel avec BQ… mais est-ce vraiment utile ? Le modèle 24h est-il réellement efficace ? Comment obtenir des prédictions à partir de ce modèle ?
Le déploiement du modèle dans BigQuery et l'obtention de prédictions se résument à exécuter deux lignes de code SQL après avoir reformaté vos données brutes en table pivotée.
Déploiement BigQuery ML et prédictions
Le SQL suivant met en forme les températures brutes en streaming au format de table pivotée, puis transmet le tout au modèle BQ ML pour obtenir des prédictions. La requête renvoie au final les prédictions ouvert/fermé des fenêtres pour les 600 dernières secondes.
Si cette requête était exécutée depuis une Cloud Function (un service de code serverless) toutes les 60 secondes via Cloud Scheduler (un service de tâches cron), et si ≥ 95 % des prédictions des 10 dernières minutes étaient dans un état non nul, vous pourriez configurer cette Cloud Function pour envoyer immédiatement un e-mail ou un SMS indiquant que la fenêtre x est ouverte depuis trop longtemps et doit être fermée. Un tel système d'alerte autorise une brève ouverture de la fenêtre, et envoie une notification si elle reste ouverte trop longtemps.
Bien que le code suivant puisse paraître long pour obtenir des prédictions, tout sauf les dernières lignes ne fait que de la préparation de données : agréger les données brutes dans le bon format de table pivotée pour servir d'entrée au modèle.
Voyons comment ce modèle se comporte lorsque toutes les fenêtres sont fermées :

Neuf secondes plus tard, dont la majeure partie consacrée au pivotement de la table plutôt qu'à la prédiction du modèle :
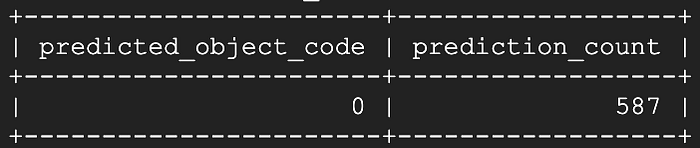
Pas mal du tout ! Il semble qu'il nous manque les 13 dernières secondes de valeurs de température en streaming pour un ou plusieurs appareils, et les 587 secondes restantes sont toutes correctement identifiées comme étant à l'état fermé.
Après avoir ouvert la fenêtre n°1 et attendu une quinzaine de secondes, j'ai relancé le script de prédiction :
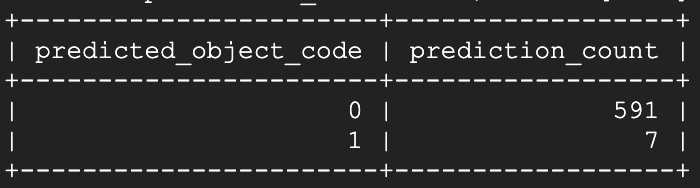
Et voilà ! Quelques secondes après l'ouverture, le modèle commence à identifier cette fenêtre précise comme ouverte. En relançant le script de prédiction environ une minute et demie plus tard :
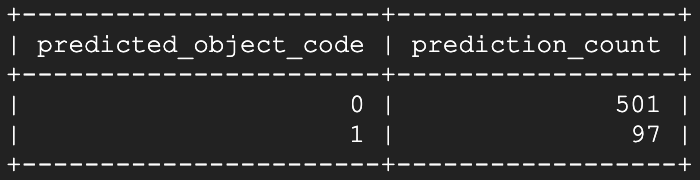
On voit que l'état ouvert est désormais identifié de manière claire et continue !
À mesure que le temps passe, l'état ouvert dépassera l'état fermé dans les prédictions sur une fenêtre glissante de 10 minutes, jusqu'à finir par dominer le décompte. À ce stade, il suffit d'écrire une Cloud Function qui passe à l'action et m'envoie une notification pour me rappeler de fermer cette fichue fenêtre !
Alertes par e-mail avec une Cloud Function
Malheureusement, Google Cloud ne propose pas de service SMS ni e-mail, et redirige les clients vers des fournisseurs tiers. Présenter l'envoi d'e-mails ou de SMS via une Cloud Function avec un service externe serait à la fois coûteux et viendrait allonger un article déjà conséquent ; nous allons donc nous arrêter là pour le tutoriel.
Si vous disposez d'un service e-mail, un script proche de celui-ci devrait faire l'affaire pour envoyer des alertes via une Cloud Function en Python :
Dépendances pour le gist open_window_alert.py
Récupération rapide des températures rétrospectives via une table externe BigTable
Une bonne partie du SQL de transformation de la table pivotée est consacrée à la récupération des écarts température actuelle moins température passée pour chaque seconde. Réaliser ces INNER JOINs rétrospectifs entièrement avec BigQuery, bien que faisable, ne sera pas très performant à grande échelle. BigQuery est avant tout optimisé pour des analyses massives sur une seule table. Comme tous les entrepôts de données, il ne peut pas prendre en charge les index — c'est le prix à payer pour le stockage et l'analyse à l'échelle du pétaoctet — ce qui rend les opérations de JOIN très intensives en calcul et à éviter autant que possible.
Une piste consiste à mettre en place une instance BigTable, le service de base de données NoSQL massivement scalable de Google Cloud qui offre des temps de réponse de l'ordre de la milliseconde pour les requêtes par ligne, et à dupliquer le stockage de vos données brutes de température dans ce service. Au sein de BigQuery, vous pouvez configurer une instance BigTable comme table externe, puis exécuter des requêtes sur cette table comme s'il s'agissait d'une table BigQuery.
En montant un second job Dataflow qui transfère vos données IoT arrivant sur une souscription Pub/Sub vers BigTable — en veillant à utiliser une clé primaire combinant deviceId et datetime — vous pourriez récupérer les points temporels individuels pour un appareil et un instant précis bien plus rapidement que ce que permettrait BQ SQL en interrogeant uniquement des tables BigQuery natives.
Avec cette approche, vous mettriez à jour votre SQL de génération de table pivotée pour effectuer un INNER JOIN avec la table externe BigTable en utilisant la combinaison appareil-datetime comme clé de jointure.
Ce workflow devrait, en théorie, être plus scalable et nettement plus performant, mais il sera également bien plus coûteux. Même une instance bon marché à un seul nœud destinée aux tests de développement vous coûtera 468 $ / mois en us-central1. Cela vaut tout de même le coup d'essayer cette approche si vous comptez déployer des opérations IoT à grande échelle.
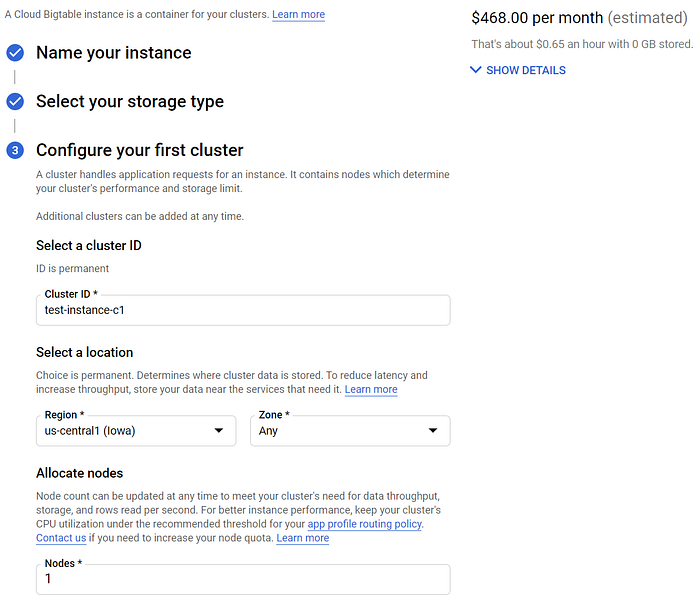
BigTable, c'est trop cher pour une simple démo !
Bravo d'être allé au bout de cette plongée approfondie dans l'IoT et le ML sur GCP. J'espère que cet article vous aura été utile et qu'il accélérera votre parcours dans l'ingestion, l'analyse et l'exploitation concrète de jeux de données à grande échelle dans le cloud, en tirant parti d'un maximum de services entièrement managés, auto-scalables et serverless, afin de réduire le temps passé à vous soucier de la disponibilité des clusters et de maximiser celui consacré à un travail réellement utile.
Pour récompenser votre patience et votre persévérance, le moins que je puisse faire est de vous offrir une dernière photo de chiot tout mignon !

Merci pour l'inspiration, Waffles et Maple ! Et merci à VOUS pour tout votre travail !