Esta publicación es la continuación de la Parte Uno , en la que vimos cómo incorporar de forma segura una flota de dispositivos IoT a escala de producción que envían datos de telemetría a tu entorno de Google Cloud mediante IoT Core y Pub/Sub, y de la Parte Dos , donde esos datos se trasladaron sin fricciones desde Pub/Sub a BigQuery mediante Dataflow, para luego visualizarse con Data Studio.
Si has seguido mis artículos anteriores, ya pasaste por la experiencia de instalar sensores de temperatura por toda tu casa y viste cómo sus datos en streaming llegan sin sobresaltos a GCP, hasta aterrizar finalmente en BigQuery, el servicio de data warehouse de Google. ¿Y ahora qué? ¿Cómo le sacamos provecho real a estos datos?
Para responder a esas preguntas, quiero mostrarte un ejemplo práctico usando una de las funcionalidades más singulares y potentes de BigQuery: BigQuery ML.
Si no seguiste los artículos anteriores, ¡tranquilo! Dejé mi dataset disponible en Kaggle; úsalo sin problema mientras avanzas.
Resumen de BigQuery ML
A diferencia de otros servicios de data warehouse, el entrenamiento y la implementación de machine learning vienen integrados directamente en BigQuery. Ambos procesos se ejecutan con comandos parecidos a SQL que son muy fáciles de armar.
Con apenas unas pocas líneas de código tipo SQL, puedes definir el tipo de modelo a crear: regresión logística o lineal, clustering k-means, redes neuronales profundas, etc. O puedes dejarlo en manos de Google creando un modelo de AutoML Tables, como haremos en este artículo. La mayoría de los modelos no requieren más especificaciones que indicar las columnas de etiqueta y de features.
Antes de meternos en los detalles de cómo iniciar el entrenamiento de ML dentro de BigQuery, primero hay que definir cómo pueden usarse los datos crudos de temperatura como modelo predictivo y qué transformaciones de datos hacen falta antes de construir el modelo. Al final, el machine learning es 90% preparación de datos.
Objetivo y metodología del Machine Learning
Mientras escribo este artículo (febrero de 2021), hace unos fríos 48 grados Fahrenheit en Oregón. La calefacción funciona a todo dar y me mantiene calentito mientras trabajo, pero de vez en cuando me gustaría dejar una ventana abierta para ventilar la casa, ¡sobre todo porque tengo un Corgi de nueve semanas que todavía no aprende del todo a ir al baño!
Lo que quiero lograr es poder abrir una ventana y, si se queda abierta demasiado tiempo, que GCP me avise. ¡No quiero gastar electricidad de más! Y, si fuera posible, que los sensores de temperatura repartidos por la zona principal de la casa también me digan qué ventana específica tengo que cerrar.

¡Es Maple! El cachorro más tierno que hayas visto. Tranquilo, vienen más fotos.
Hay tres sensores enviando datos de telemetría de temperatura a mi proyecto de GCP, y cada uno está cerca de una ventana distinta en la sala principal de mi casa.
Dos están muy pegados a sus respectivas ventanas, mientras que el tercero está a unos 8 pies de la ventana más cercana. Esa cercanía se nota en los datos: un sensor (device_id) reporta valores varios grados más cálidos que los otros dos:
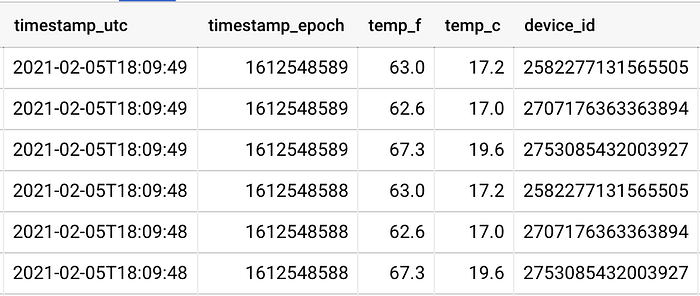
Los sensores 258* y 270* están cada uno cerca de su propia ventana, mientras que el 275* está a unos 8 pies de una tercera ventana
Para construir un modelo de machine learning capaz de identificar cuándo se abre una ventana específica, hay que aplicar varios pasos de transformación hasta llegar a la tabla final lista para el entrenamiento. Entrenar el modelo requiere:
- Registrar los intervalos en los que una ventana está abierta. Anoté manualmente en Excel los tiempos de inicio y fin de "ventana #1/2/3 abierta". Los intervalos no registrados se asumen como ventanas cerradas. Esta tabla luego se exportará a CSV y se cargará como tabla de BigQuery.
- Transformar la tabla de datos crudos de temperatura en streaming, donde cada fila contiene un valor de temperatura específico de un sensor para un segundo determinado, en una tabla pivoteada donde cada segundo tiene su propia fila. Cada fila por segundo tendrá columnas con la temperatura de cada dispositivo en ese instante, además de columnas con la diferencia entre el valor actual del sensor y su valor de hace x segundos. La idea es seguir tanto el valor actual de cada sensor como cuánto ha cambiado respecto a algún intervalo pasado: hace 10 minutos, 5 minutos, 3 minutos, 1 minuto, hasta hace 5 segundos. Estas columnas serán features predictivas excelentes.
- La tabla de BQ que define los intervalos de ventanas abiertas y cerradas se debe combinar con la tabla pivoteada de temperatura, lo que nos da una tabla final con nuestras columnas de features predictivas de temperatura y una columna de etiqueta de ventana abierta / todas las ventanas cerradas.
Veamos rápidamente cómo se hace cada uno de estos pasos.
Registrar los intervalos de ventanas abiertas y cargarlos en BigQuery
A medida que iba abriendo una de las tres ventanas de mi casa, registré manualmente en una tabla de Excel el momento exacto en el que se abría cada una:
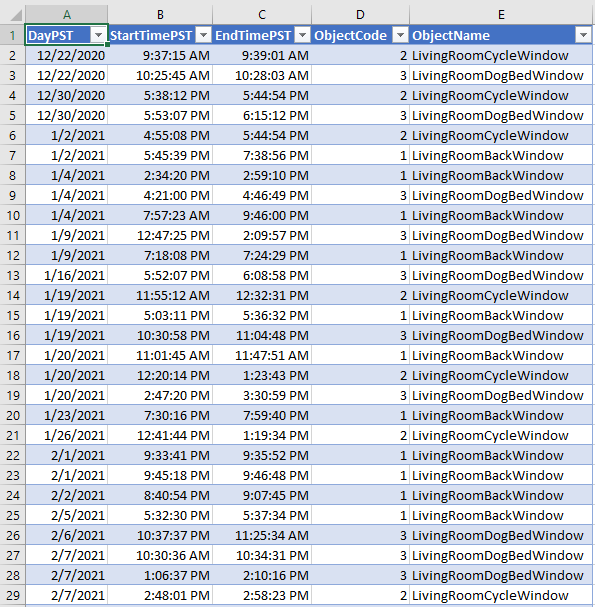
Intervalos en PST en los que se abrió una ventana específica
Ten en cuenta que los valores de ObjectCode del uno al tres representan cada uno una ventana específica, y un valor no especificado de cero se usará más adelante para indicar que todas las ventanas están cerradas.
Después de reunir suficientes puntos de datos a lo largo de mes y medio, exporté la tabla a CSV, la subí a un bucket de Cloud Storage (GCS) y luego ejecuté el siguiente comando para crear una nueva tabla de BigQuery con el esquema autodetectado:
Crear una tabla con los datetimes de los intervalos de ventanas abiertas y cerradas en UTC
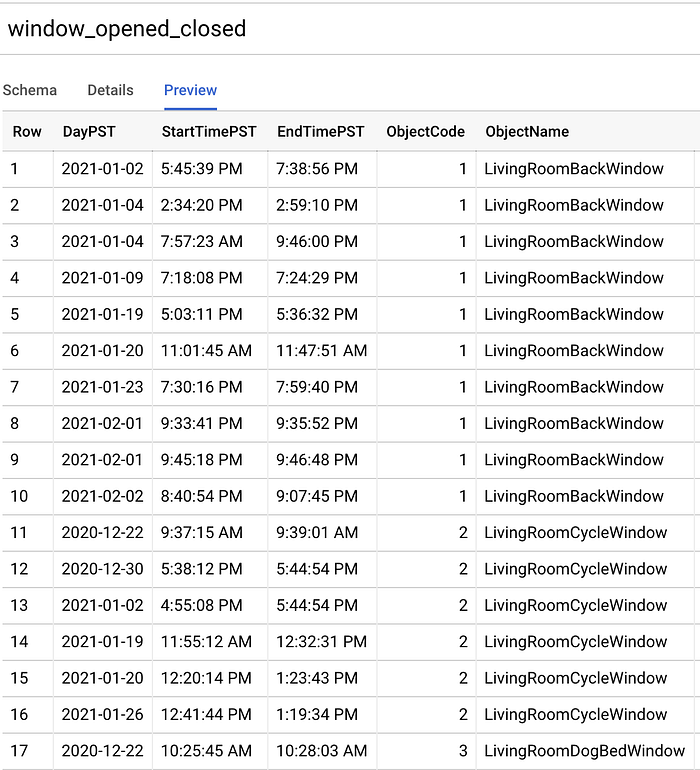
Tabla de BigQuery "window_opened_closed" creada con el comando "bq load"
Como los datos en streaming:
- Se almacenan en UTC en lugar del valor PST que registré manualmente, y
- Guardan valores datetime en lugar de los valores separados de fecha y timestamp que registré manualmente,
ejecuté el siguiente comando SQL para convertir los puntos de inicio y fin de ventana abierta a datetimes en estándar de tiempo universal:
Crear una tabla con los datetimes de los intervalos de ventanas abiertas y cerradas en UTC
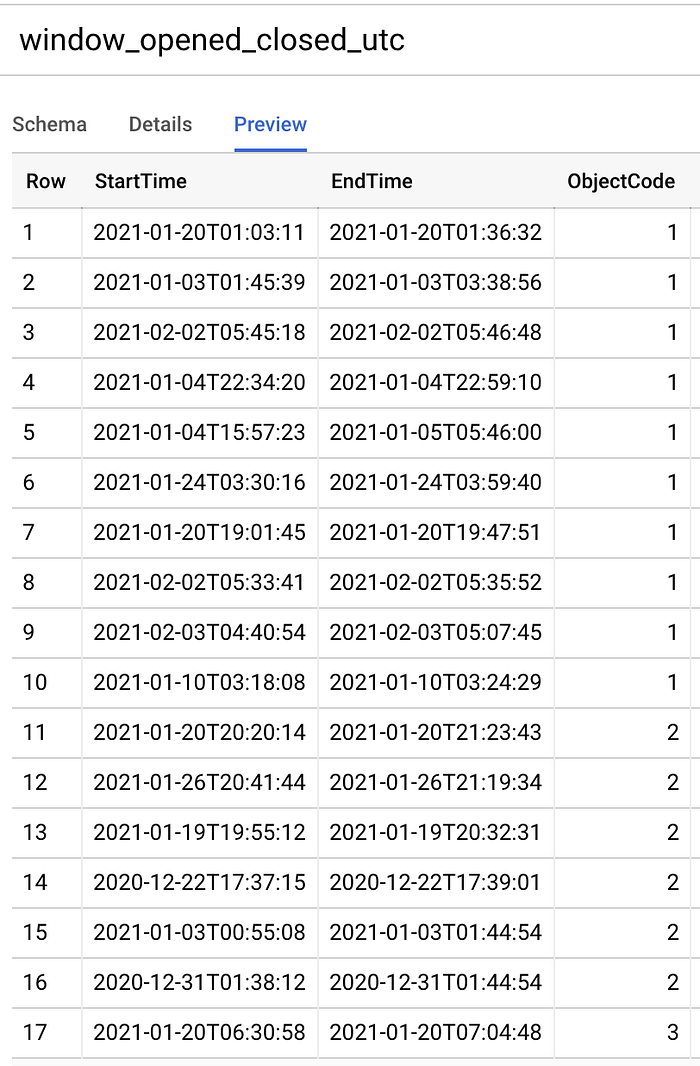
Timestamps un poco más amigables para la máquina
Antes de unir estos estados de ventana abierta/cerrada con los puntos de tiempo de temperatura, primero hay que pivotear la tabla de datos crudos para que todos los valores de los sensores en un segundo dado queden en una sola fila.
Nota al margen: si estás trabajando con los datos crudos de temperatura de mi dataset de Kaggle en lugar de tus propios datos en streaming, usa lo siguiente para importar ese CSV a tu proyecto antes de continuar:
Crear la tabla de temperatura pivoteada por datetime
Se puede pivotear la tabla de datos crudos por segundo y por sensor a filas por segundo con todos los valores presentes con el siguiente SQL. Fíjate que en esta consulta también excluyo las filas en las que uno o más sensores no llegaron a registrar valor. Hubo varios incidentes en los que se fue la luz: toda mi casa quedó sin energía durante una hora el día de Navidad, la Roomba chocó con el cable de un sensor, Maple tumbó otro… ¡siempre hay que esperar lo inesperado!
Quizás puedas imputar valores predeterminados razonables para esos nulos (por ejemplo, con un promedio de los valores de ese sensor durante los últimos 60s). Sin embargo, mi dataset tiene unas 10,5 millones de filas de datos crudos, más que suficiente para entrenar el modelo. Probablemente sea mejor excluir directamente del entrenamiento las filas con valores nulos en lugar de intentar adivinar valores razonables.
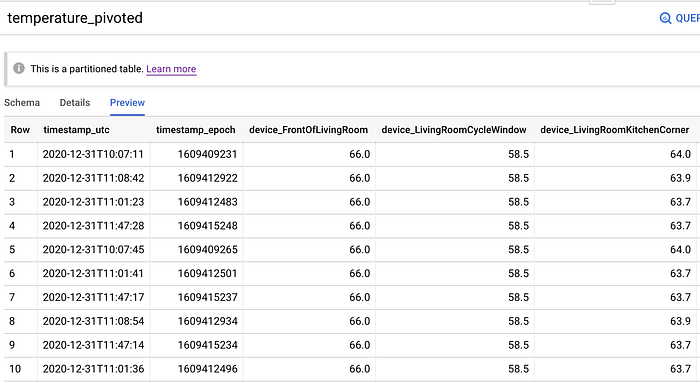
Tabla de temperaturas de los sensores pivoteada por datetime
¡Casi estamos listos para entrenar el modelo! Solo nos falta crear una tabla más que contenga lo siguiente:
- Una combinación de los puntos de tiempo con los estados conocidos de ventanas abiertas. Los puntos de tiempo que no tengan un estado de ventana abierta reciben por defecto un valor de estado cerrado.
- Creación de columnas con valores retrospectivos de temperatura. Conocer la temperatura de un dispositivo en un segundo dado es útil, pero lo es aún más poder comparar el valor actual con varios puntos de tiempo del pasado.
Para conseguirlo, ejecuto una última sentencia SQL que crea la tabla final de BigQuery, la que servirá de entrada para nuestro proceso de entrenamiento de machine learning. Vale la pena mencionar que existe una manera mucho más rápida —aunque considerablemente más cara— de obtener estos valores retrospectivos, pero hablaremos de eso más adelante.
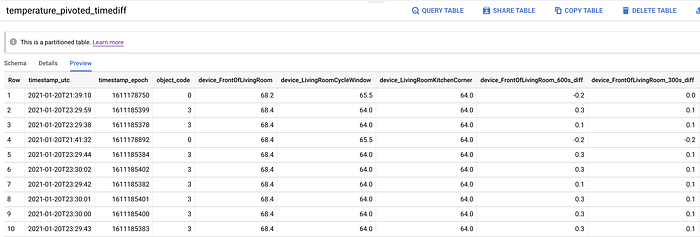
Datos de temperatura pivoteados, con columnas añadidas para el estado de ventana abierta/cerrada y los puntos de tiempo retrospectivos
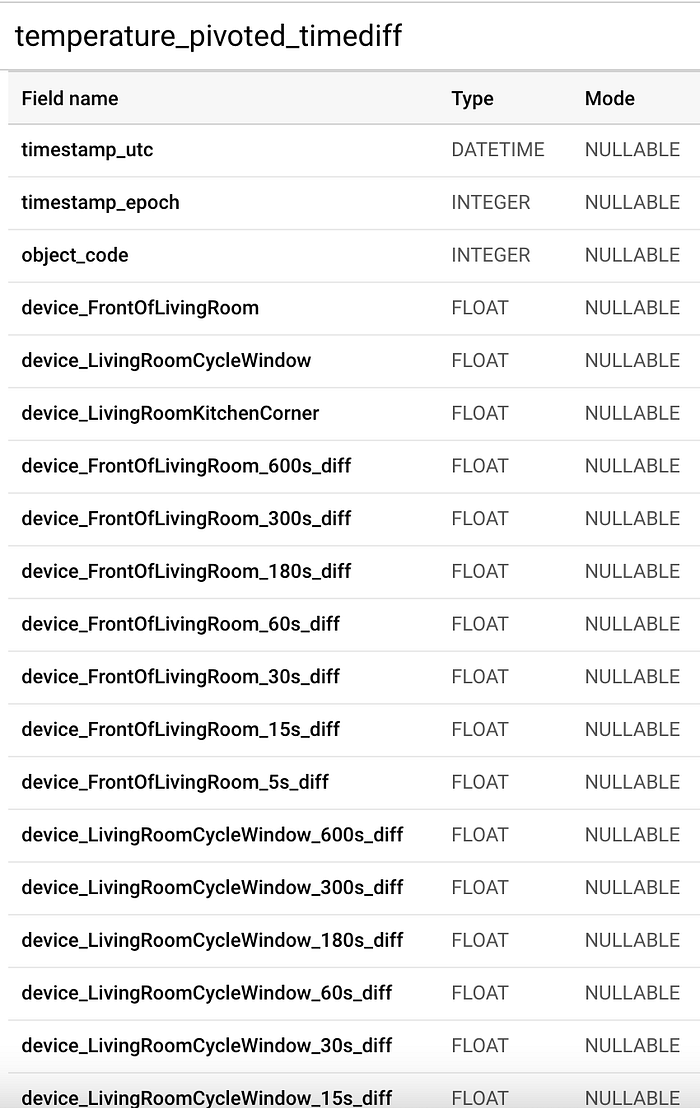
Esquema parcial de la tabla final que actúa como entrada para el proceso de entrenamiento de machine learning
Con esta tabla final, por fin tenemos todo lo necesario para empezar a entrenar un modelo de BigQuery ML.
Entrenamiento con BigQuery ML
Las siguientes cuatro líneas de código tipo SQL le indican a BigQuery que:
- Entrene un modelo de ML con el algoritmo AutoML Tables de Google. Si tarda más de 24 horas, que corte el entrenamiento y se quede con el mejor modelo generado hasta ese momento.
- Use "object_code" (estado de ventana abierta/cerrada) como la columna a predecir.
- Todas las demás columnas se usarán como features, excepto los datetimes.
Lo ejecutas, esperas a que termine y eso es todo. ¡En serio!
Como el dataset pivoteado es bastante grande —25 columnas y unos 3,2 millones de filas, cerca de 80 millones de celdas— y AutoML entrena y evalúa repetidamente una multitud de redes neuronales profundas con un alto costo computacional, esto va a tardar un buen rato.
Entrenamiento con BigQuery ML: advertencia de costo
Al momento de escribir este artículo, la funcionalidad AutoML de BigQuery se cobra a "$5.00 por TB, más el costo de entrenamiento de AI Platform". Uno podría suponer que se trata de una operación de entrenamiento bastante barata, dado que la tabla pivoteada con la que entrenamos pesa 659 MB:

Tamaño de la tabla pivoteada utilizada para generar el modelo de BQ ML
Sin embargo, AutoML crea y luego escanea una gran cantidad de datasets temporales como parte de su proceso de entrenamiento de DNN. Cuando el modelo limitado a 24 horas por fin terminó de generarse, ¡había procesado (y facturado!) más de 89 TB de datos:

Entrenar AutoML durante 24 horas sale mucho más caro de lo que uno esperaría
Esto da un costo de $445.85, sin contar los cargos de procesamiento opacos en los que incurre BigQuery por detrás al usar AI Platform para el entrenamiento, lo que llevó el costo total a unos $500.
Si tu intención es probar BQ ML sin gastar mucho, ten cuidado con cuántas horas de entrenamiento presupuestas. Cambiar BUDGET_HOURS de 24.0 a 1.0 produce un modelo que termina en 1h 41m y solo procesó 3,87 TB, es decir, unos $19.35 (más los costos ocultos de cómputo del entrenamiento):

Entrenar AutoML durante 1 hora resulta considerablemente más barato
Resultados del entrenamiento con BigQuery ML
Tras esperar 24 horas, el modelo terminó de generarse. ¡Los resultados son bastante impresionantes! Métricas comunes de evaluación como accuracy, precision, recall, F1 score y ROC AUC arrojan valores ≥0.99:
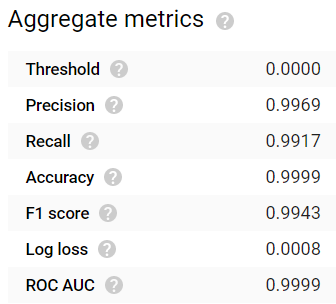
Valores altos de Accuracy, Precision y Recall con un modelo entrenado durante 24 horas. ¡Nada mal!
A pesar de que las clases de la etiqueta están muy desbalanceadas —las ventanas pasan mucho más tiempo cerradas que abiertas, porque no quiero dispararme la cuenta de la luz—, cada estado de ventana abierta presenta tasas de verdaderos positivos excepcionalmente altas. Incluso la tercera ventana, cuyo sensor más cercano está a unos ocho pies en lugar de a pocas pulgadas, logró una tasa de detección de verdaderos positivos >97%:
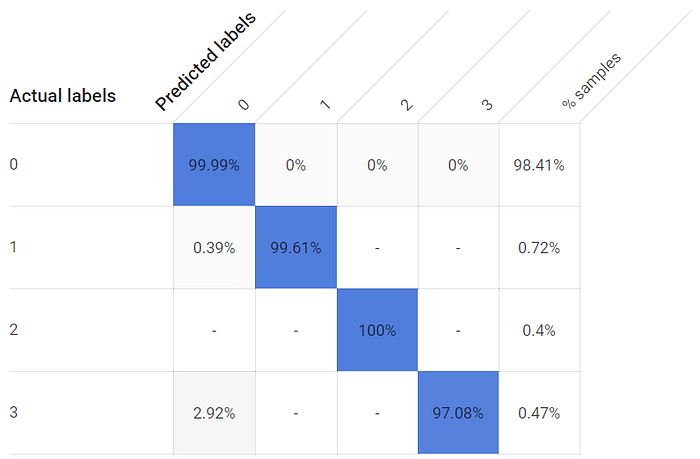
Las tasas de verdaderos positivos para los estados de ventana abierta y cerrada son altas con un modelo entrenado durante 24 horas
Generar un modelo con un corte de una hora produce un modelo utilizable, aunque las tasas de TP por clase son más bajas, y bastante más bajas en el caso de la tercera ventana, cuyo sensor de temperatura está más alejado:
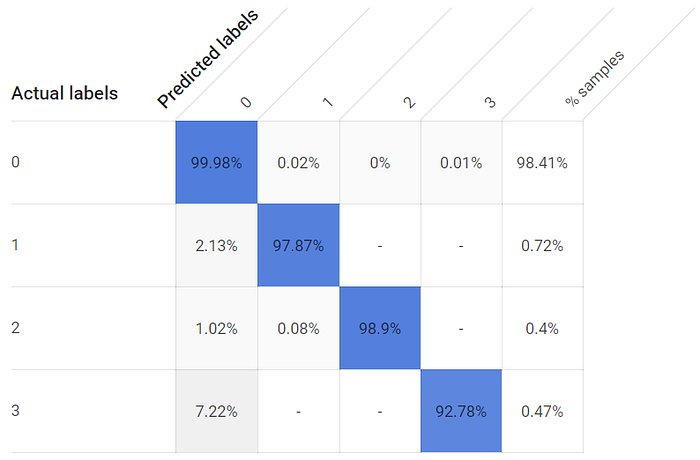
Las tasas de verdaderos positivos para los estados de ventana abierta y cerrada son más bajas con un modelo entrenado durante una hora
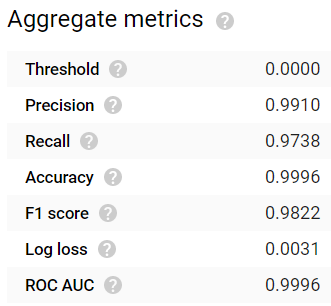
Accuracy y Precision altas, pero valores de Recall más bajos con un modelo entrenado durante una hora
Está bastante bueno lo fácil que es construir un modelo de ML funcional con BQ… pero ¿es útil? ¿El modelo de 24h es realmente efectivo? ¿Cómo obtenemos predicciones con este modelo?
Implementar el modelo dentro de BigQuery y obtener predicciones es tan simple como ejecutar dos líneas de código SQL después de volver a darle a tus datos crudos el formato de tabla pivoteada.
Implementación y predicciones con BigQuery ML
El siguiente SQL transforma las temperaturas crudas en streaming al formato de tabla pivoteada y luego las pasa al modelo de BQ ML para obtener predicciones. En definitiva, la consulta devuelve predicciones de ventana abierta/cerrada para los últimos 600 segundos.
Si esta consulta se ejecutara desde una Cloud Function (un servicio de código serverless) cada 60 segundos usando Cloud Scheduler (un servicio de cron jobs), y si ≥95% de las predicciones de los últimos 10 minutos arrojaran un estado distinto de cero, podrías configurar esa Cloud Function para que envíe de inmediato un correo o un mensaje de texto avisando que la ventana x lleva demasiado tiempo abierta y hay que cerrarla. Un sistema de alertas así permite ventilar un rato y avisarte solo cuando se queda abierta demasiado tiempo.
Aunque lo siguiente parezca mucho código para obtener predicciones, todo salvo las últimas líneas es simple preparación de datos: juntar los datos crudos en el formato adecuado de tabla pivoteada para usarlos como entrada del modelo.
Veamos cómo se desempeña este modelo cuando todas las ventanas están cerradas:

Nueve segundos después, la mayoría de los cuales se dedicaron al pivoteo de la tabla y no a la predicción del modelo:
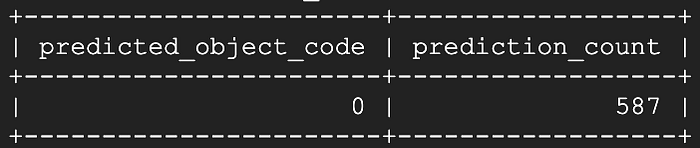
¡Nada mal! Parece que nos faltan los 13 segundos más recientes de valores de temperatura en streaming en vivo de uno o más dispositivos, y los 587 segundos restantes están todos correctamente identificados en estado cerrado.
Después de abrir la ventana #1 y esperar unos 15 segundos, volví a ejecutar el script de predicción:
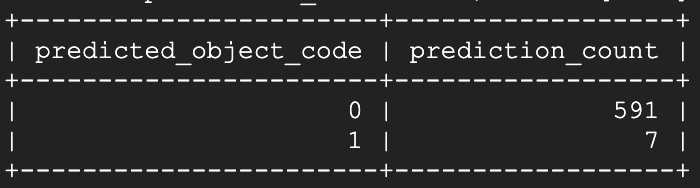
¡Voilà! A los pocos segundos de abrirla, el modelo empezó a identificar esa ventana específica como abierta. Al ejecutar el script de predicción otra vez aproximadamente un minuto y medio después:
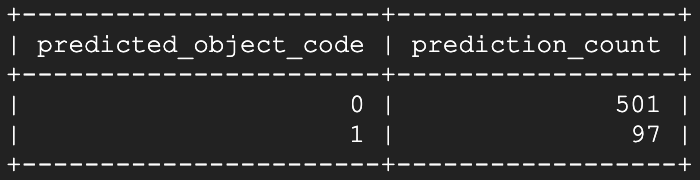
¡El estado abierto se identifica clara y continuamente!
Con el paso del tiempo, las predicciones de estado abierto van a superar a las de estado cerrado dentro de una ventana de 10 minutos, hasta que terminan dominando el conteo. En ese punto se podría escribir una Cloud Function que tome acción y me envíe una notificación para que cierre de una vez la dichosa ventana.
Alertas por correo con una Cloud Function
Lamentablemente, Google Cloud no ofrece servicios de SMS ni de correo electrónico, sino que redirige a sus clientes a empresas externas. Mostrar el envío de correo o SMS desde una Cloud Function con un servicio externo sería costoso y alargaría aún más este artículo de por sí extenso, así que cortaremos el tutorial aquí.
Si tienes a mano un servicio de correo, un script parecido al siguiente debería funcionar bien para enviar alertas mediante una Cloud Function en Python:
Requirements para el gist open_window_alert.py
Recuperación rápida de temperaturas retrospectivas con una tabla externa de BigTable
Una buena parte del SQL de transformación de la tabla pivoteada se dedica a recuperar valores de "temperatura actual menos pasada" para cada segundo. Hacer estos INNER JOIN retrospectivos enteramente con BigQuery, aunque es factible, no resulta muy performante a escala. BigQuery está optimizado para análisis a escala masiva sobre una sola tabla. Como ocurre con todos los data warehouses, no admite índices al permitir almacenamiento y análisis a escala de petabytes, y eso hace que las operaciones JOIN sean muy intensivas en cómputo y conviene evitarlas siempre que sea posible.
Vale la pena considerar configurar una instancia de BigTable, el servicio de base de datos NoSQL de Google Cloud masivamente escalable que ofrece tiempos de respuesta de un solo dígito de milisegundos para consultas de filas individuales, y duplicar el almacenamiento de tus datos crudos de temperatura ahí. Dentro de BigQuery puedes configurar una instancia de BigTable como tabla externa y luego ejecutar consultas sobre esta tabla como si fuera una tabla nativa de BigQuery.
Si configuraras un segundo job de Dataflow que mueva tus datos IoT que llegan a una Suscripción de PubSub hacia BigTable, asegurándote de usar como clave primaria la combinación de deviceId y datetime, podrías recuperar puntos de tiempo individuales para un dispositivo y un instante específicos mucho más rápido de lo que lo haría el SQL de BQ consultando solo tablas nativas.
Con este enfoque, actualizarías el SQL que genera la tabla pivoteada para hacer INNER JOIN con la tabla externa de BigTable usando la combinación dispositivo-datetime como clave del JOIN ON.
En teoría, este flujo debería ser más escalable y mucho más performante, pero también será considerablemente más caro. Incluso una instancia "barata" de un solo nodo para pruebas de desarrollo cuesta $468 al mes en us-central1. Aun así, conviene que pruebes este enfoque si planeas desplegar operaciones IoT a escala.
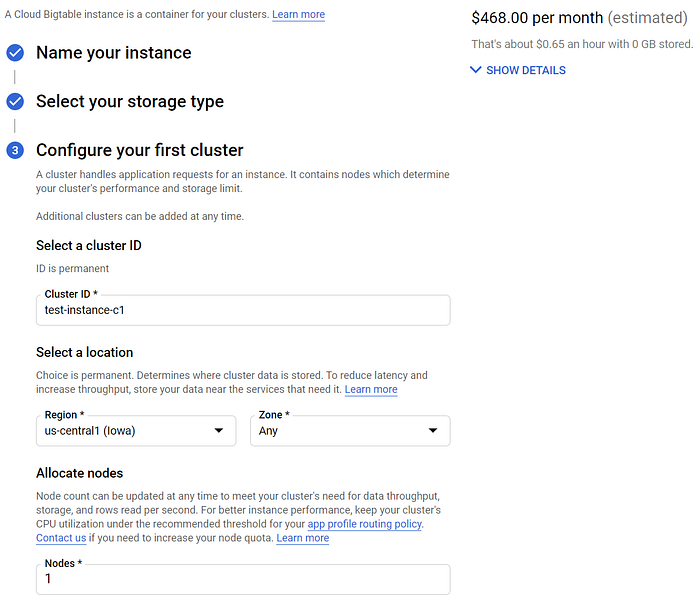
¡BigTable es demasiado caro para un recorrido de demo!
Felicidades por haber llegado hasta el final de este análisis a fondo sobre IoT y ML en GCP. Espero que haya sido didáctico y te ayude a avanzar más rápido en tu camino hacia ingerir, analizar y aprovechar de verdad datasets a gran escala en la nube, apoyándote en la mayor cantidad posible de servicios totalmente administrados, autoescalables y serverless, para minimizar el tiempo que pasas estresándote por el uptime de los clústeres y maximizar el que dedicas a hacer trabajo que valga la pena.
Como recompensa por tu paciencia y perseverancia, lo menos que puedo hacer es regalarte una última foto de cachorro tierno.

¡Gracias por la inspiración, Waffles y Maple! Y ¡GRACIAS a ti por todo tu esfuerzo!