Questo articolo prosegue la Parte uno, in cui abbiamo visto come effettuare l'onboarding sicuro di una flotta di dispositivi IoT su scala produttiva che inviano dati di telemetria in streaming verso il proprio ambiente Google Cloud tramite IoT Core e Pub/Sub, e la Parte due, in cui quegli stessi dati sono stati spostati senza interruzioni da Pub/Sub a BigQuery tramite Dataflow e poi visualizzati con Data Studio.
Se ha seguito i miei articoli precedenti, si è divertito a installare sensori di temperatura in tutta la casa e ha visto i dati in streaming live confluire senza intoppi in GCP, fino ad atterrare in BigQuery, il servizio di data warehouse di Google. E adesso? Come si possono sfruttare questi dati in modo concreto?
Per rispondere a queste domande, vorrei mostrarle un esempio pratico basato su una delle funzionalità più peculiari e potenti di BigQuery: BigQuery ML.
Se non ha seguito gli articoli precedenti, niente paura! Ho reso il mio dataset disponibile su Kaggle: può tranquillamente utilizzarlo per seguire l'articolo.
Panoramica di BigQuery ML
A differenza di altri servizi di data warehouse, l'addestramento e il deployment dei modelli di machine learning sono integrati direttamente in BigQuery. Entrambe le operazioni si eseguono tramite comandi in stile SQL, semplici da scrivere.
Bastano poche righe di codice in stile SQL per specificare il tipo di modello da creare: ad esempio modelli basati su regressione logistica o lineare, k-means clustering, reti neurali profonde e così via. In alternativa, può lasciare la scelta a Google creando un modello AutoML Tables, come faremo in questo articolo. La maggior parte dei modelli non richiede altro che indicare le colonne della label e delle feature.
Prima di entrare nel dettaglio di come avviare l'addestramento ML in BigQuery, dobbiamo capire come i dati grezzi di temperatura possano alimentare un modello predittivo e quali trasformazioni siano necessarie prima della costruzione del modello stesso. Il machine learning è, dopotutto, per il 90% preparazione dei dati.
Obiettivo e metodologia del machine learning
Mentre scrivo (febbraio 2021), in Oregon ci sono freddi 48 gradi Fahrenheit. Il riscaldamento va a pieno regime e mi tiene al calduccio mentre lavoro, ma di tanto in tanto vorrei lasciare aperta una finestra per cambiare aria — soprattutto perché ho un Corgi di nove settimane non ancora del tutto educato ai bisogni!
L'idea è poter aprire una finestra e, se rimane aperta troppo a lungo, ricevere da GCP un promemoria che mi avvisi. Non voglio sprecare troppa elettricità! Possibilmente, vorrei che i sensori di temperatura distribuiti nella zona giorno mi indicassero anche quale finestra specifica chiudere.

Ecco Maple! Il cucciolo più carino che si possa immaginare. E non si preoccupi, ce ne saranno altre.
Sono tre i sensori che inviano in streaming dati di telemetria della temperatura nel mio progetto GCP, ciascuno posizionato vicino a una diversa finestra del soggiorno principale di casa.
Due sensori sono molto vicini alla rispettiva finestra, mentre il terzo si trova a circa 2,5 metri dalla finestra più vicina. La vicinanza dei sensori alle finestre si riflette nei dati: un sensore (device_id) registra valori di diversi gradi più caldi rispetto agli altri due:
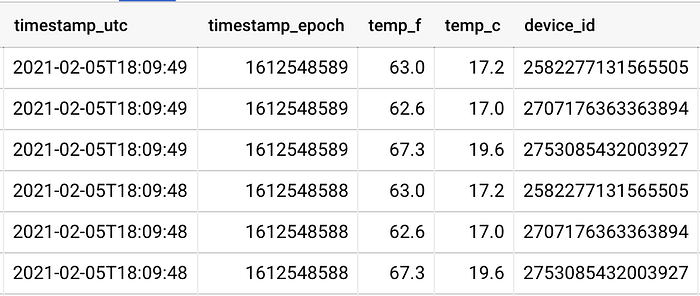
I sensori 258* e 270* sono ciascuno vicino alla propria finestra, mentre il sensore 275* si trova a circa 2,5 metri da una terza finestra
Per costruire un modello di machine learning in grado di identificare quando una specifica finestra è aperta, occorre eseguire alcune trasformazioni dei dati per ottenere la tabella finale pronta per l'addestramento. Per addestrare un modello servono:
- Il tracciamento degli intervalli temporali in cui una finestra è aperta. Ho inserito manualmente in Excel gli orari di inizio e fine di "finestra #1/2/3 aperta". Gli intervalli non tracciati si presumono con finestre chiuse. Questa tabella verrà poi convertita in CSV e caricata come tabella BigQuery.
- La trasformazione della tabella grezza dei dati di temperatura in streaming — in cui ogni riga contiene un valore di temperatura specifico per sensore in un determinato secondo — in una tabella pivotata in cui ogni singolo secondo dispone di una propria riga di dati. Ogni riga al secondo conterrà colonne con la temperatura di ciascun dispositivo in quel momento, oltre a colonne che mostrano la differenza tra il valore attuale di un sensore e quello di x secondi prima. L'obiettivo è tracciare il valore di temperatura attuale di ciascun sensore e di quanto è cambiato rispetto a un intervallo passato: 10 minuti fa, 5 minuti, 3 minuti, 1 minuto e così via fino a 5 secondi prima. Queste colonne fungeranno da ottime feature predittive.
- La tabella BQ che definisce gli intervalli temporali con finestre aperte e chiuse va unita alla tabella di temperatura pivotata, fornendoci una tabella finale contenente le nostre colonne di feature predittive di temperatura e una colonna label finestra aperta / tutte le finestre chiuse.
Vediamo rapidamente come eseguire ciascuno di questi passaggi.
Tracciare gli intervalli di apertura delle finestre e caricarli in BigQuery
Mentre aprivo una delle tre finestre di casa, ho annotato manualmente in una tabella Excel l'istante esatto in cui veniva aperta una specifica finestra:
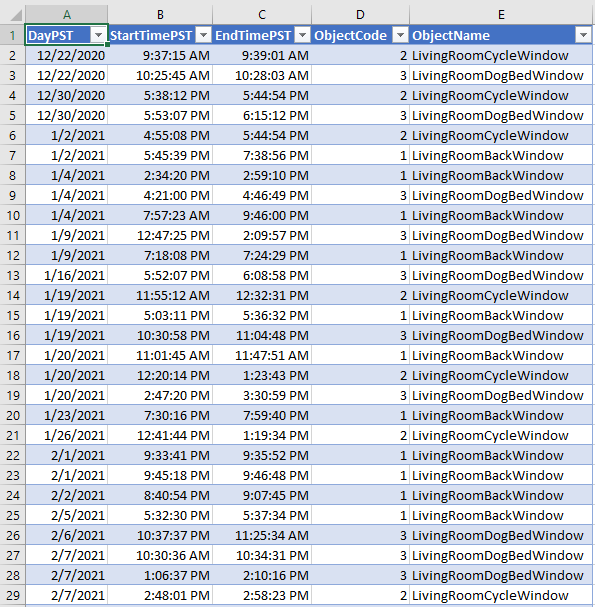
Intervalli temporali in PST in cui una specifica finestra è stata aperta
I valori di ObjectCode da uno a tre rappresentano ciascuno una finestra specifica, mentre il valore zero (non specificato) verrà utilizzato in seguito per indicare che tutte le finestre sono chiuse.
Dopo aver raccolto quelli che ritenevo punti dati sufficienti nell'arco di 1,5 mesi, ho esportato il file in CSV, caricato il CSV in un bucket Cloud Storage (GCS) ed eseguito il seguente comando per creare una nuova tabella BigQuery con schema rilevato automaticamente:
Crea una tabella di datetime degli intervalli di finestre aperte e chiuse in UTC
Tabella BigQuery 'window_opened_closed' creata con il comando 'bq load'
Dato che i dati in streaming sono:
- Memorizzati in UTC anziché nel valore PST registrato manualmente, e
- Memorizzati come valori datetime anziché come valori separati di data e timestamp registrati manualmente
Ho eseguito il seguente comando SQL per convertire gli istanti di inizio e fine di apertura delle finestre in datetime nello standard UTC:
Crea una tabella di datetime degli intervalli di finestre aperte e chiuse in UTC
Timestamp un po' più digeribili per un computer
Prima di unire questi stati di apertura/chiusura delle finestre agli istanti di temperatura, dobbiamo pivotare la tabella dei dati grezzi in modo che tutti i valori dei sensori per un dato secondo siano presenti in un'unica riga.
Nota a margine: se sta lavorando con i dati grezzi di temperatura del mio dataset Kaggle anziché con dati propri in streaming, utilizzi quanto segue per importare il CSV nel suo progetto prima di proseguire:
Creazione della tabella di temperatura pivotata per datetime
Per pivotare la tabella grezza dei dati di temperatura per secondo e per sensore in righe per secondo che contengano tutti i valori dei sensori, si può utilizzare il seguente SQL. In questa query escludo anche le righe in cui uno o più sensori non sono riusciti a registrare un valore. Si sono verificati molti episodi in cui è mancata la corrente — un'ora intera in tutta la casa il giorno di Natale, il Roomba che ha urtato il cavo di alimentazione di un sensore, Maple che ha rovesciato un sensore… aspettiamoci sempre l'imprevisto!
Si potrebbe pensare di sostituire questi valori null con valori predefiniti ragionevoli (ad esempio, con la media dei valori di quel sensore negli ultimi 60 secondi). Tuttavia, nel mio dataset ci sono circa 10,5 milioni di righe di dati grezzi, più che sufficienti per addestrare il modello. È probabilmente meglio escludere del tutto le righe con valori null dall'addestramento piuttosto che tentare una stima approssimativa.
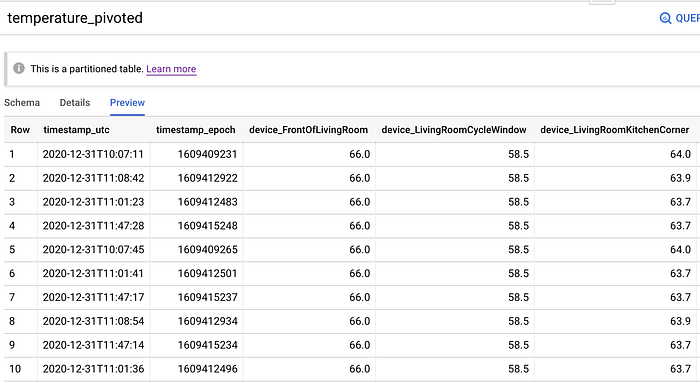
Tabella delle temperature dei sensori pivotata per datetime
Siamo quasi pronti a iniziare l'addestramento del modello! Resta solo da creare un'altra tabella che contenga:
- Un'unione tra gli istanti temporali e gli stati noti di apertura delle finestre. A tutti gli istanti privi di uno stato di finestra aperta viene assegnato per impostazione predefinita uno stato di chiusura.
- La creazione di colonne con valori di temperatura retrospettivi. Conoscere la temperatura di un dispositivo per un dato secondo è utile, ma lo è ancora di più poter confrontare il valore attuale con vari istanti del passato.
Per raggiungere questi obiettivi eseguo un ultimo comando SQL che crea la tabella BigQuery finale, destinata a fungere da input per il nostro processo di addestramento ML. Tengo a sottolineare che esiste un metodo molto più rapido, anche se considerevolmente più costoso, per ottenere questi valori retrospettivi, ma ne parleremo più avanti.
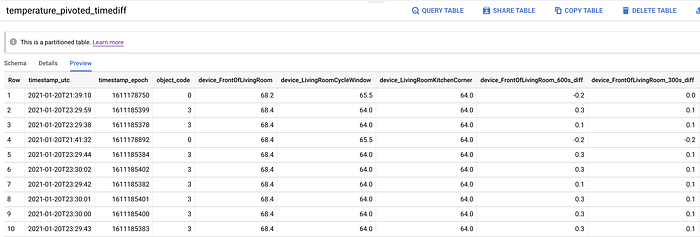
Dati di temperatura pivotati, con colonne aggiunte per lo stato aperto/chiuso delle finestre e gli istanti retrospettivi
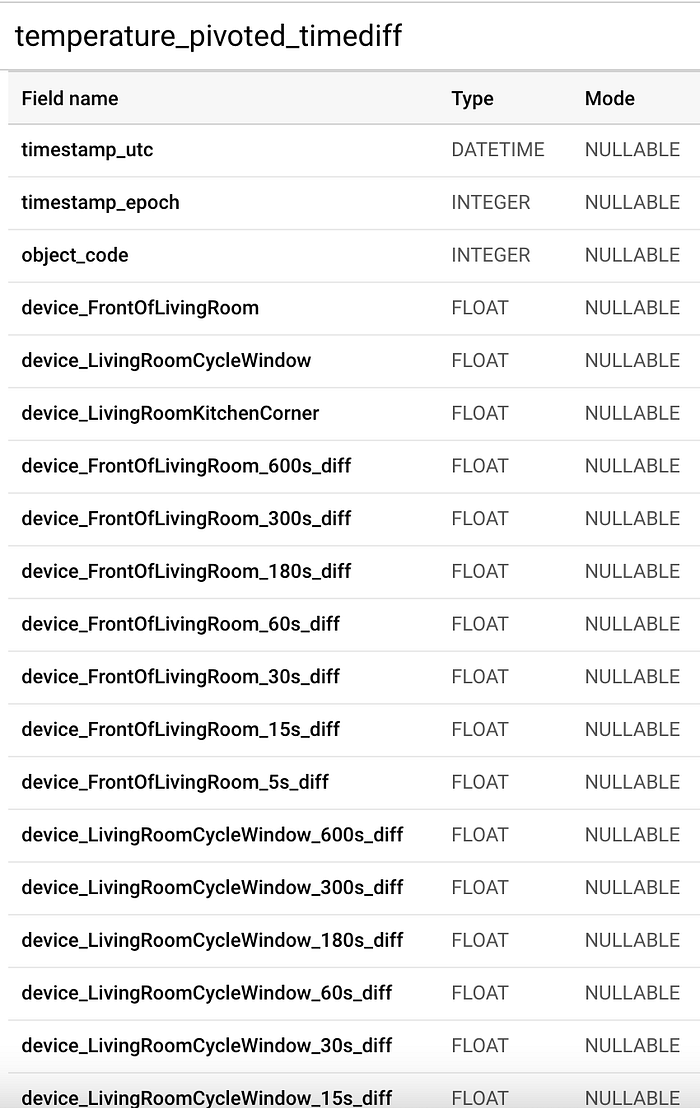
Schema parziale della tabella finale che funge da input per il processo di addestramento del machine learning
Con questa tabella finale abbiamo finalmente tutto il necessario per iniziare ad addestrare un modello BigQuery ML.
Addestramento di BigQuery ML
Le seguenti quattro righe di codice in stile SQL indicano a BigQuery di:
- Addestrare un modello ML utilizzando l'algoritmo AutoML Tables di Google. Se richiede più di 24 ore, interrompere l'addestramento e utilizzare il miglior modello generato fino a quel momento.
- Utilizzare "object_code" (stato di apertura/chiusura della finestra) come colonna da prevedere.
- Utilizzare tutte le altre colonne come feature, eccetto i datetime.
Esegua il comando, attenda il completamento ed è fatta. Sul serio!
Considerato che il dataset pivotato è piuttosto grande, con 25 colonne e circa 3,2 milioni di righe (ovvero circa 80 milioni di celle di dati), e che AutoML addestra e valuta ripetutamente una moltitudine di reti neurali profonde computazionalmente onerose, il completamento richiederà del tempo.
Addestramento di BigQuery ML: avviso sui costi
Al momento della stesura di questo articolo, la funzionalità AutoML di BigQuery viene fatturata a "5,00 $ per TB, più il costo di addestramento di AI Platform". Verrebbe da pensare che si tratti di un'operazione di addestramento piuttosto economica, dato che la tabella pivotata su cui addestriamo è di 659 MB:

Dimensione della tabella pivotata utilizzata per la generazione del modello BQ ML
In realtà AutoML, durante il processo di addestramento delle DNN, crea e poi analizza numerosi dataset temporanei. Quando il modello, limitato a 24 ore, ha finalmente terminato la generazione, aveva elaborato (e fatturato!) oltre 89 TB di dati:

L'addestramento AutoML per 24 ore è molto più costoso di quanto si possa immaginare
Il totale arriva a 445,85 $, senza contare gli oneri di elaborazione poco trasparenti sostenuti dietro le quinte da BigQuery che utilizza AI Platform per l'addestramento, i quali hanno portato il costo complessivo intorno ai 500 $.
Se intende provare BQ ML senza spendere troppo, presti attenzione a quante ore di addestramento mette a budget. Modificando BUDGET_HOURS da 24,0 a 1,0 ore si ottiene un modello che termina in 1h41m e ha elaborato solo 3,87 TB, ovvero circa 19,35 $ (più i costi nascosti di calcolo per l'addestramento):

L'addestramento AutoML per 1 ora è considerevolmente più economico
Risultati dell'addestramento di BigQuery ML
Dopo 24 ore di attesa, il modello è stato completato. I risultati sono davvero notevoli! Le metriche di valutazione più comuni come accuracy, precision, recall, F1 score e ROC AUC restituiscono tutte valori ≥0,99:
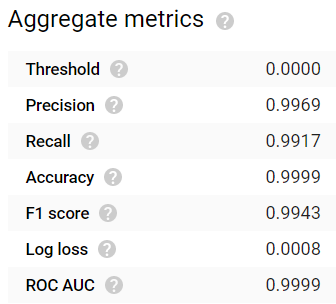
Valori elevati di Accuracy, Precision e Recall con un modello addestrato per 24 ore. Niente male!
Nonostante una distribuzione fortemente sbilanciata fra le classi della label — le finestre rimangono chiuse molto più spesso che aperte, dato che non voglio far lievitare troppo la bolletta della luce — ogni stato di finestra aperta presenta comunque tassi di veri positivi eccezionalmente elevati. Persino la terza finestra, il cui sensore più vicino si trova a circa 2,5 metri anziché a pochi centimetri, ha raggiunto un tasso di rilevamento dei veri positivi superiore al 97%:
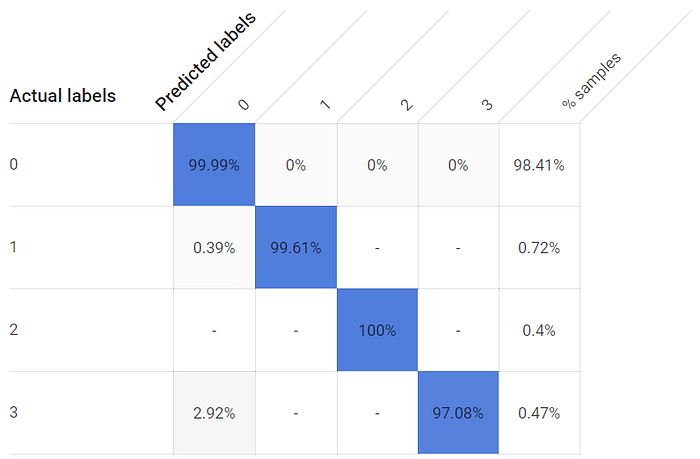
I tassi di veri positivi per gli stati di finestra aperta e chiusa sono elevati con un modello addestrato per 24 ore
Generare un modello con un limite di un'ora produce un risultato utilizzabile, anche se i tassi di TP per le singole classi sono inferiori, e in modo sostanziale per la terza finestra, con il suo sensore di temperatura più distante:
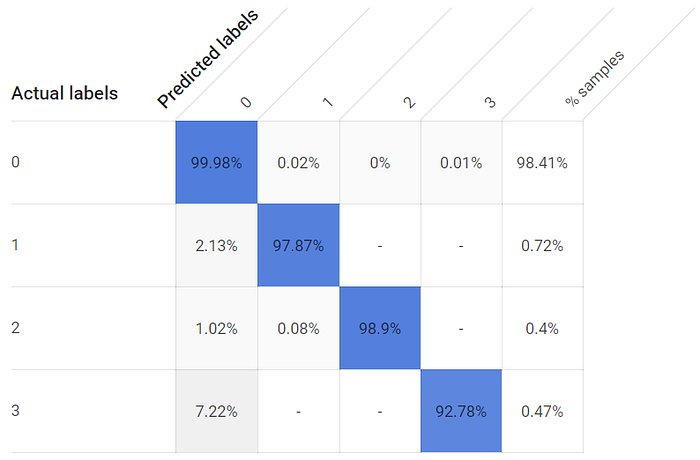
I tassi di veri positivi per gli stati di finestra aperta e chiusa sono inferiori con un modello addestrato per un'ora
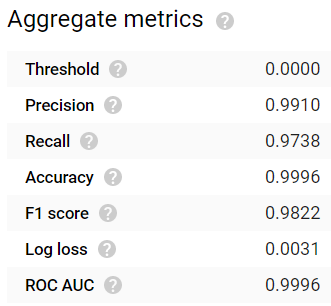
Accuracy e Precision elevate, ma valori di Recall inferiori con un modello addestrato per un'ora
È davvero notevole quanto sia facile costruire un modello ML funzionante con BQ… ma è davvero utile? Il modello da 24 ore è realmente efficace? Come si possono ottenere previsioni con questo modello?
Eseguire il deployment del modello in BigQuery e ottenere previsioni è semplice come eseguire due righe di codice SQL, dopo aver riportato i dati grezzi in formato di tabella pivotata.
Deployment e previsioni con BigQuery ML
Il seguente SQL trasforma le temperature grezze in streaming nel formato di tabella pivotata e le passa al modello BQ ML per le previsioni. La query restituisce in definitiva le previsioni di apertura/chiusura delle finestre relative agli ultimi 600 secondi.
Se questa query venisse eseguita all'interno di una Cloud Function (un servizio di codice serverless) ogni 60 secondi tramite Cloud Scheduler (un servizio di cron job), e se il ≥95% delle previsioni degli ultimi 10 minuti risultasse in uno stato diverso da zero, si potrebbe configurare la Cloud Function in modo da inviare immediatamente un'e-mail o un SMS che segnala che la finestra x è rimasta aperta troppo a lungo e va chiusa. Un sistema di alerting di questo tipo consente di lasciare la finestra aperta per un breve periodo, inviando una notifica solo quando rimane aperta troppo a lungo.
Anche se quanto segue può sembrare molto codice per ottenere delle previsioni, tutto tranne le ultime righe è semplicemente preparazione dei dati: la raccolta dei dati grezzi nel corretto formato di tabella pivotata da utilizzare come input del modello.
Vediamo come si comporta il modello con tutte le finestre chiuse:

Nove secondi dopo, di cui la maggior parte spesi nel pivoting della tabella e non nella previsione del modello:
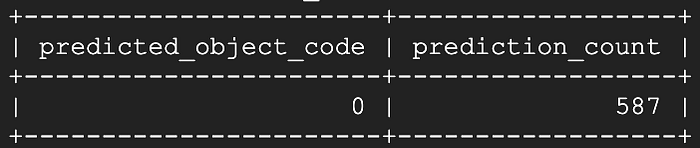
Niente male! Sembra che ci manchino i 13 secondi più recenti di valori di temperatura in streaming live di uno o più dispositivi, mentre i restanti 587 secondi vengono tutti correttamente identificati come stato chiuso.
Dopo aver aperto la finestra #1 e atteso circa 15 secondi, ho rieseguito lo script di previsione:
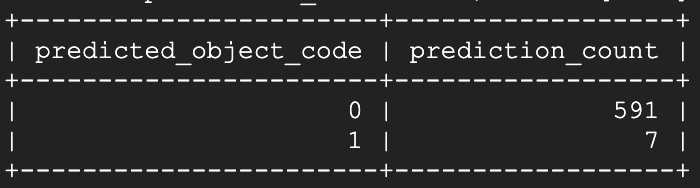
Voilà! Pochi secondi dopo l'apertura, il modello ha iniziato a identificare quella specifica finestra come aperta. Eseguendo nuovamente lo script di previsione circa un minuto e mezzo dopo:
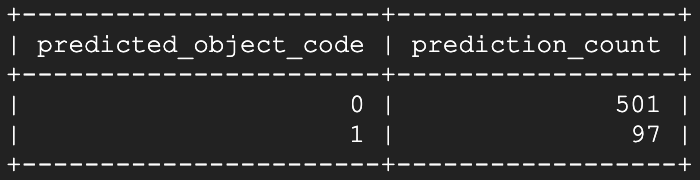
Si vede che lo stato aperto viene identificato in modo chiaro e continuativo!
Con il passare del tempo, lo stato aperto supererà numericamente le previsioni di stato chiuso nell'arco di 10 minuti, fino a dominare il conteggio delle previsioni nella finestra temporale. A quel punto si potrebbe scrivere una Cloud Function che agisca di conseguenza ed emetta una notifica per ricordarmi di chiudere quella benedetta finestra!
Alerting via e-mail con una Cloud Function
Purtroppo Google Cloud non offre servizi SMS o e-mail e indirizza i clienti verso provider terzi. Mostrare l'invio di e-mail o SMS tramite una Cloud Function appoggiata a un servizio esterno sarebbe sia costoso sia ulteriormente prolisso per un articolo già lungo, quindi qui interrompiamo il tutorial.
Se dispone di un servizio e-mail, uno script simile al seguente dovrebbe funzionare bene per l'alerting tramite una Cloud Function in Python:
Requisiti per il gist open_window_alert.py
Recupero rapido di temperature retrospettive con una tabella esterna BigTable
Buona parte dell'SQL di trasformazione dei dati per la tabella pivotata è dedicata al recupero dei valori "temperatura attuale meno temperatura passata" per ogni singolo secondo. Eseguire queste INNER JOIN retrospettive interamente con BigQuery, sebbene fattibile, non risulta altamente performante su larga scala. BigQuery dà il meglio per analytics su scala massiva su una singola tabella. Come tutti i data warehouse, non può supportare gli indici proprio per consentire archiviazione e analisi su scala petabyte: questo rende le operazioni JOIN molto onerose dal punto di vista computazionale e qualcosa da evitare quando possibile.
Potrebbe valutare l'idea di configurare un'istanza BigTable, il servizio di database NoSQL altamente scalabile di Google Cloud che offre tempi di risposta a una sola cifra in millisecondi per query su singole righe, e di duplicare al suo interno l'archiviazione dei dati grezzi di temperatura. In BigQuery è possibile configurare un'istanza BigTable come tabella esterna e poi eseguire query su questa tabella come se fosse una tabella BigQuery.
Configurando un secondo job Dataflow che sposti in BigTable i dati IoT in arrivo su una sottoscrizione PubSub, avendo cura di utilizzare una chiave primaria che combini deviceId e datetime, si potrebbero recuperare singoli istanti per un determinato dispositivo molto più velocemente di quanto possa fare BQ SQL attingendo esclusivamente da tabelle native di BigQuery.
Con questo approccio si dovrebbe quindi aggiornare l'SQL di generazione della tabella pivotata in modo da effettuare INNER JOIN sulla tabella esterna BigTable utilizzando come chiave JOIN ON la combinazione device-datetime.
In teoria questo flusso di lavoro dovrebbe essere più scalabile e altamente performante, ma sarà anche considerevolmente più costoso. Anche un'istanza single-node "economica" per i test di sviluppo costa 468 $ al mese in us-central1. Vale comunque la pena provare a implementare questo approccio se intende rilasciare operazioni IoT su larga scala.
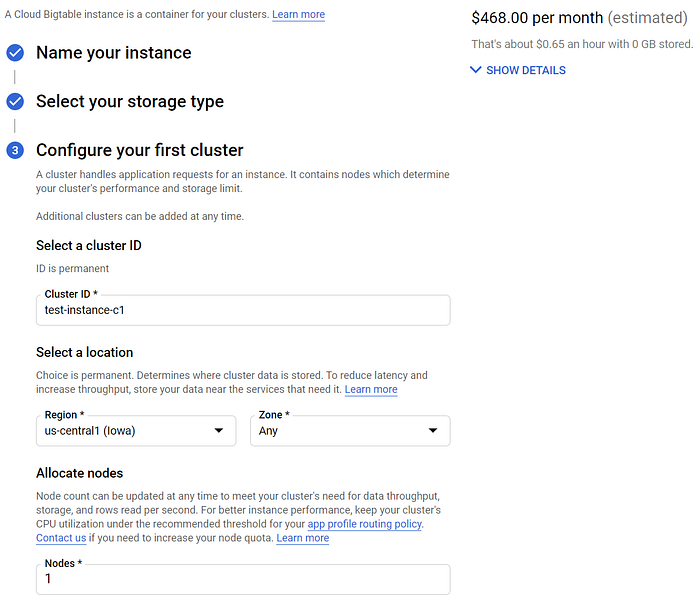
BigTable è troppo costoso per una semplice demo!
Complimenti per aver seguito fino in fondo questo approfondimento su IoT e ML su GCP. Spero sia stato istruttivo e l'abbia aiutata ad accelerare nel suo percorso di ingestion, analisi e utilizzo concreto di dataset su larga scala nel cloud, sfruttando il maggior numero possibile di servizi completamente gestiti, auto-scaling e serverless, in modo da ridurre al minimo il tempo speso a preoccuparsi dell'uptime dei cluster e massimizzare quello dedicato a un lavoro davvero significativo.
Come ricompensa per la sua pazienza e la sua perseveranza, il minimo che possa fare è offrirle un'ultima foto di cucciolo!

Grazie per l'ispirazione, Waffles e Maple! E grazie a LEI per tutto l'impegno!