Este post é a continuação da Parte Um , em que mostramos como integrar com segurança uma frota de dispositivos IoT em escala de produção transmitindo dados de telemetria para o seu ambiente Google Cloud via IoT Core e Pub/Sub, e da Parte Dois , em que esses dados foram movidos sem complicação do Pub/Sub para o BigQuery via Dataflow e, depois, visualizados com o Data Studio.
Se você acompanhou meus artigos anteriores, já curtiu instalar sensores de temperatura pela casa e viu os dados transmitidos ao vivo fluírem tranquilamente para o GCP, parando no BigQuery, o serviço de data warehouse do Google. E agora? Como dar uso prático a esses dados?
Para responder a essas perguntas, quero apresentar um exemplo prático usando um dos recursos mais singulares e poderosos do BigQuery: o BigQuery ML.
Se você não acompanhou os artigos anteriores, fique tranquilo! Disponibilizei meu dataset no Kaggle; fique à vontade para usá-lo enquanto acompanha o tutorial.
Visão geral do BigQuery ML
Diferente de outros serviços de data warehouse, o treinamento e o deployment de machine learning são integrados diretamente ao BigQuery. Tanto o treinamento quanto o deployment são feitos com comandos no estilo SQL, fáceis de montar.
Com poucas linhas de código no estilo SQL, você pode especificar o tipo de modelo a ser criado, como modelos baseados em regressão logística ou linear, k-means clustering, deep neural networks, e por aí vai. Ou pode deixar isso por conta do Google criando um modelo do AutoML Tables, como faremos neste artigo. A maioria dos modelos não exige especificações além das colunas de label e features.
Antes de mergulhar nos detalhes de como iniciar o treinamento de ML no BigQuery, precisamos primeiro definir como os dados brutos de temperatura podem ser usados em um modelo preditivo e quais transformações de dados precisam acontecer antes da construção do modelo. Afinal, machine learning é 90% preparação de dados.
Objetivo e metodologia do machine learning
No momento em que escrevo este artigo (fev/2021), a temperatura aqui em Oregon está em geladinhos 48 graus Fahrenheit. O aquecedor está a todo vapor, me deixando bem aquecido enquanto trabalho, mas, de vez em quando, gostaria de deixar uma janela aberta para renovar o ar da casa — ainda mais porque tenho um Corgi de nove semanas que ainda não está totalmente treinado para fazer as necessidades no lugar certo!
O que eu queria é poder abrir uma janela e, se ela ficar aberta tempo demais, ter o GCP me lembrando que está aberta. Não quero desperdiçar muita eletricidade! Se possível, quero que os sensores de temperatura espalhados pela área principal da casa também me digam qual janela específica fechar.

É a Maple! O filhote mais fofo que você já viu. Calma, ainda tem mais foto pela frente.
Há três sensores transmitindo dados de telemetria de temperatura para o meu projeto no GCP, e cada um está posicionado perto de uma janela diferente na sala principal da minha casa.
Dois sensores ficam bem perto de suas janelas, enquanto o terceiro fica a cerca de 2,4 metros da janela mais próxima. Dá para ver a proximidade dos sensores às janelas refletida nos dados, em que um sensor (device_id) registra valores vários graus mais quentes do que os outros dois:
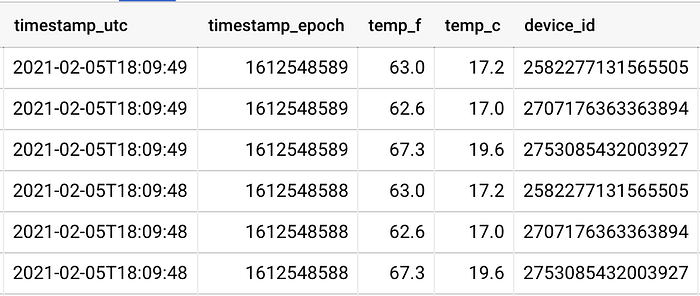
Os sensores 258* e 270* estão posicionados perto de suas janelas, enquanto o sensor 275* fica a cerca de 2,4 metros de uma terceira janela
Para construir um modelo de machine learning capaz de identificar quando uma janela específica está aberta, precisamos passar por algumas etapas de transformação de dados até chegar à tabela final pronta para o treinamento. Treinar um modelo exige:
- Registrar os intervalos de tempo em que uma janela está aberta. Inseri manualmente no Excel os horários de início e fim de "janela #1/2/3 está aberta". Os intervalos não registrados são tidos como janelas fechadas. Essa tabela será convertida para CSV e carregada como uma tabela do BigQuery.
- Transformar a tabela de dados brutos de temperatura em streaming, em que cada linha contém um valor de temperatura específico de um sensor para um segundo específico, em uma tabela pivotada na qual cada segundo individual tem sua própria linha de dados. Cada linha por segundo terá colunas com a temperatura de cada dispositivo naquele momento, além de colunas mostrando a diferença entre o valor atual de um sensor e seu valor x segundos atrás. O objetivo aqui é acompanhar o valor de temperatura atual de cada sensor e o quanto esse valor mudou em relação a algum intervalo no passado: 10 minutos atrás, 5 minutos, 3 minutos, 1 minuto, e assim por diante até 5 segundos atrás. Essas colunas vão funcionar como excelentes features preditivas.
- A tabela do BQ que define os intervalos de tempo em que as janelas estão abertas e fechadas deve ser combinada com a tabela pivotada de temperaturas, gerando uma tabela final que contém nossas colunas de features preditivas de temperatura e uma coluna de label janela aberta / todas as janelas fechadas.
Vamos passar rapidamente por cada uma dessas etapas.
Registrando os intervalos de janelas abertas e carregando-os no BigQuery
Conforme abria uma das três janelas da minha casa, registrei manualmente em uma tabela do Excel o momento exato em que cada janela específica foi aberta:
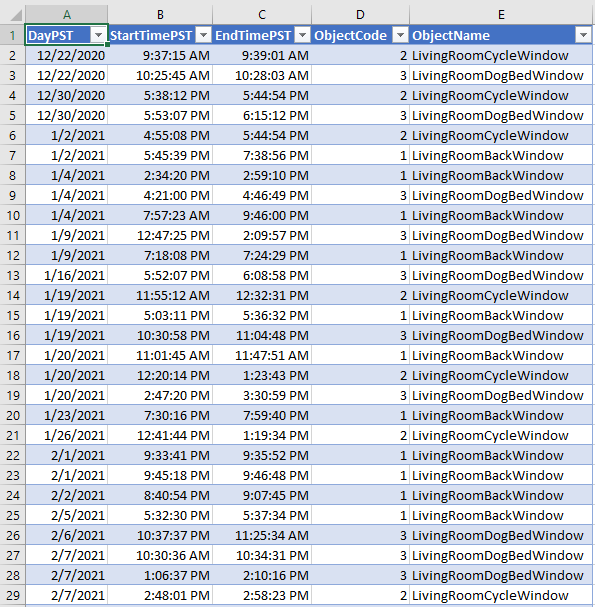
Intervalos de tempo em PST em que uma janela específica foi aberta
Os valores de ObjectCode de um a três representam, cada um, uma janela específica, enquanto um valor não especificado igual a zero será usado mais adiante para representar todas as janelas fechadas.
Depois de coletar o que considerei pontos de dados suficientes ao longo de 1,5 mês, exportei tudo para um CSV, fiz upload desse CSV em um bucket do Cloud Storage (GCS) e, em seguida, executei o seguinte comando para criar uma nova tabela do BigQuery a partir disso, com o schema detectado automaticamente:
Crie uma tabela com os datetimes em UTC dos intervalos de janelas abertas e fechadas
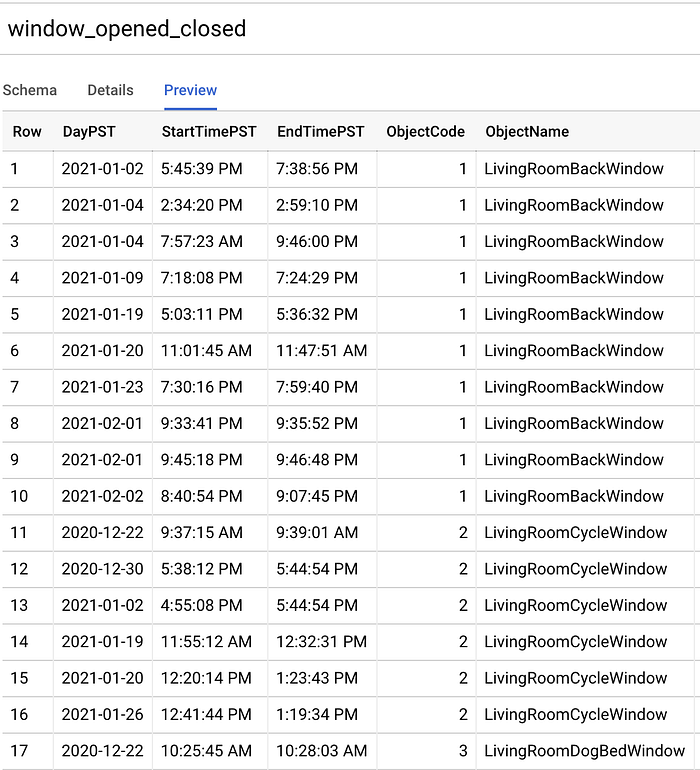
Tabela do BigQuery 'window_opened_closed' criada a partir do comando 'bq load'
Como os dados em streaming estão:
- Armazenados em UTC, e não no valor PST que registrei manualmente, e
- Armazenados como valores datetime, e não como valores separados de date e timestamp, como registrei manualmente
Executei o seguinte comando SQL para converter os pontos de início e fim das janelas abertas em datetimes no padrão de tempo universal:
Crie uma tabela com os datetimes em UTC dos intervalos de janelas abertas e fechadas
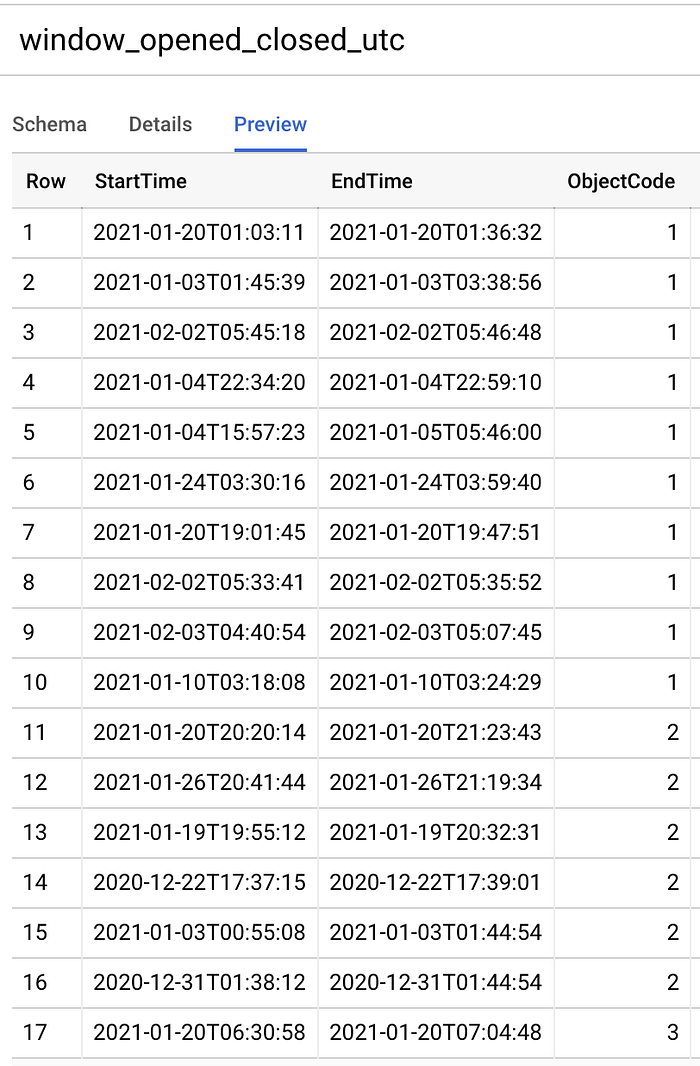
Timestamps um pouquinho mais amigáveis para o computador
Antes de juntar esses estados de aberto/fechado das janelas aos pontos de tempo das temperaturas, precisamos primeiro pivotar nossa tabela de dados brutos para que todos os valores dos sensores em um determinado segundo fiquem em uma única linha.
Observação: se você está trabalhando com os dados brutos de temperatura do meu dataset no Kaggle em vez dos seus próprios dados em streaming, use o seguinte para importar esse CSV para o seu projeto antes de seguir em frente:
Criação da tabela de temperaturas pivotada por datetime
Pivotar a tabela bruta de temperaturas por segundo, por sensor, em linhas por segundo com todos os valores dos sensores presentes pode ser feito com o SQL a seguir. Note que, nesta query, também estou excluindo linhas em que um ou mais sensores não conseguiram registrar um valor. Aconteceram várias situações: a casa inteira ficou sem energia por uma hora no Natal, o Roomba esbarrou no cabo de força de um sensor, a Maple derrubou um sensor… espere o inesperado!
Talvez dê para imputar valores padrão razoáveis para esses nulos (por exemplo, com a média dos valores daquele sensor nos últimos 60s). No entanto, no meu dataset há cerca de 10,5 milhões de linhas de dados brutos, mais do que suficiente para treinar o modelo. Provavelmente é melhor excluir totalmente as linhas com valores nulos do treinamento do que tentar adivinhar valores padrão razoáveis.
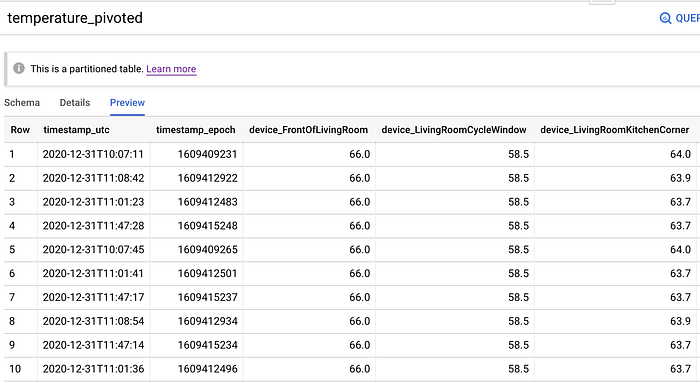
Tabela de temperaturas dos sensores pivotada por datetime
Estamos quase prontos para começar a treinar nosso modelo! Só precisamos criar mais uma tabela contendo o seguinte:
- Uma combinação dos pontos de tempo com os estados conhecidos de janela aberta. Todos os pontos de tempo sem um estado de janela aberta recebem, por padrão, um valor de estado fechado.
- Criação de colunas de valores retrospectivos de temperatura. Saber a temperatura de um dispositivo em um determinado segundo é útil, mas é ainda mais útil permitir uma comparação do valor atual com diversos pontos de tempo no passado.
Para alcançar esses objetivos, executo um último comando SQL que cria a tabela final do BigQuery, que servirá de input para o nosso processo de treinamento de machine learning. Vale destacar que existe uma forma muito mais rápida — embora consideravelmente mais cara — de obter esses valores retrospectivos, mas falaremos disso mais adiante.
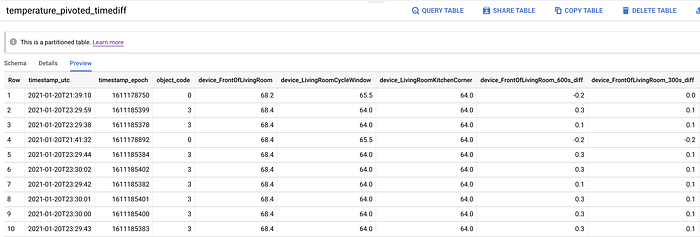
Dados de temperatura pivotados, com colunas adicionadas para o estado da janela (aberta/fechada) e pontos de tempo retrospectivos
Schema parcial da tabela final que serve de input para o processo de treinamento de machine learning
Com essa tabela final, finalmente temos tudo o que precisamos para começar a treinar um modelo do BigQuery ML.
Treinamento do BigQuery ML
As quatro linhas de código no estilo SQL a seguir dizem ao BigQuery para:
- Treinar um modelo de ML usando o algoritmo AutoML Tables do Google. Se demorar mais de 24 horas, encerrar o treinamento e usar o melhor modelo gerado até aquele momento.
- Usar "object_code" (estado aberto/fechado da janela) como a coluna a ser prevista.
- Usar todas as outras colunas como features, exceto os datetimes.
Execute, espere terminar e pronto. Sério!
Como o dataset pivotado é bem grande, com 25 colunas e cerca de 3,2 milhões de linhas, ou aproximadamente 80 milhões de células de dados, e sabendo que o AutoML treina e avalia repetidamente uma série de deep neural networks computacionalmente intensivas, isso vai levar um tempinho para concluir.
Treinamento do BigQuery ML: aviso sobre custos
No momento em que escrevo este artigo, o recurso AutoML do BigQuery é cobrado a "US$ 5,00 por TB, mais o custo de treinamento da AI Platform". Você poderia esperar que essa fosse uma operação de treinamento bem barata, dado que a tabela pivotada que estamos usando para treinar tem 659 MB:

Tamanho da tabela pivotada usada para a geração do modelo de BQ ML
No entanto, o AutoML cria e depois varre vários datasets temporários como parte do processo de treinamento das DNNs. Quando o modelo limitado a 24 horas finalmente terminou de ser gerado, ele havia processado (e cobrado!) mais de 89 TB de dados:

O treinamento do AutoML por 24 horas é bem mais caro do que você imagina
Isso resulta em um custo de US$ 445,85, sem contar os custos de processamento ofuscados incorridos nos bastidores pelo BigQuery ao usar a AI Platform para o treinamento, o que elevou o custo total para cerca de US$ 500.
Se você pretende testar o BQ ML sem gastar muito, tenha cuidado com a quantidade de horas de treinamento que vai orçar. Mudar BUDGET_HOURS de 24,0 para 1,0 hora gera um modelo que termina em 1h41 e processou apenas 3,87 TB, ou aproximadamente US$ 19,35 (mais os custos ocultos de compute do treinamento):

O treinamento do AutoML por 1 hora é consideravelmente mais barato
Resultados do treinamento do BigQuery ML
Depois de esperar 24 horas, o modelo terminou de ser gerado. Os resultados são bem impressionantes! Métricas comuns de avaliação como accuracy, precision, recall, F1 score e ROC AUC apresentam todas valores ≥0,99:
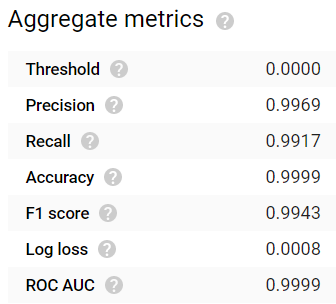
Valores altos de Accuracy, Precision e Recall com um modelo treinado por 24 horas. Nada mau!
Apesar da representação extremamente desbalanceada entre as classes do label — as janelas ficam fechadas muito mais tempo do que abertas, já que não quero estourar a conta de luz —, cada estado de janela aberta ainda apresenta taxas de true positive excepcionalmente altas. Até a terceira janela, cujo sensor mais próximo está a cerca de 2,4 metros, e não a centímetros, conseguiu uma taxa de detecção de true positive maior que 97%:
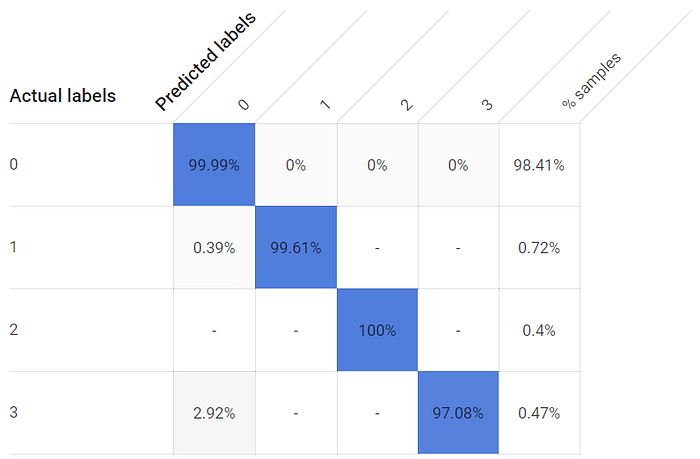
As taxas de True Positive para os estados aberto e fechado da janela são altas com um modelo treinado por 24 horas
Gerar um modelo com corte de uma hora produz um modelo utilizável, embora as taxas de TP para classes individuais sejam menores, e bem mais baixas para a terceira janela, com seu sensor de temperatura mais distante:
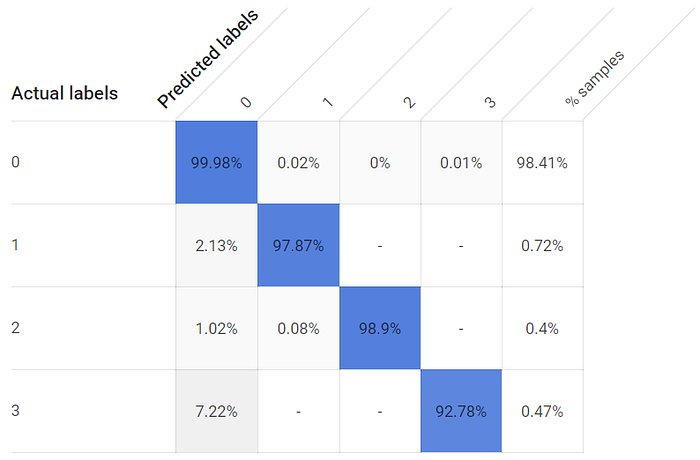
As taxas de True Positive para os estados aberto e fechado da janela são menores com um modelo treinado por uma hora
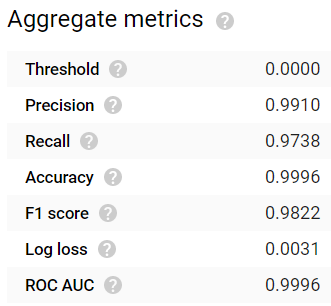
Accuracy e Precision altas, mas valores menores de Recall com um modelo treinado por uma hora
É bem legal como é fácil construir um modelo de ML funcional usando o BQ… mas será que é útil? O modelo de 24h é realmente eficaz? Como obter previsões usando esse modelo?
Fazer o deployment do modelo dentro do BigQuery e gerar previsões é tão simples quanto rodar duas linhas de código SQL depois de formatar seus dados brutos de volta para o formato de tabela pivotada.
Deployment e previsões com o BigQuery ML
O SQL a seguir formata as temperaturas brutas em streaming no formato de tabela pivotada e, em seguida, alimenta o modelo do BQ ML para fazer as previsões. No fim, a query retorna previsões de janela aberta/fechada para os últimos 600 segundos.
Se essa query fosse executada de dentro de uma Cloud Function (um serviço de código serverless) a cada 60 segundos usando o Cloud Scheduler (um serviço de cron job), e se ≥95% das previsões dos últimos 10 minutos viessem em um estado diferente de zero, dava para configurar essa Cloud Function para enviar imediatamente um e-mail ou uma mensagem de texto avisando que a janela x está aberta há tempo demais e precisa ser fechada. Esse sistema de alerta permite uma abertura breve da janela e a notificação quando ela é deixada aberta tempo demais.
Embora o trecho a seguir possa parecer muito código só para obter previsões, todas as linhas, exceto as poucas finais, são apenas preparação de dados — reunir os dados brutos no formato de tabela pivotada apropriado para uso como input do modelo.
Vamos ver como esse modelo se comporta quando todas as janelas estão fechadas:

Nove segundos depois, sendo que a maior parte foi gasta na pivotagem da tabela de dados, e não na previsão do modelo:
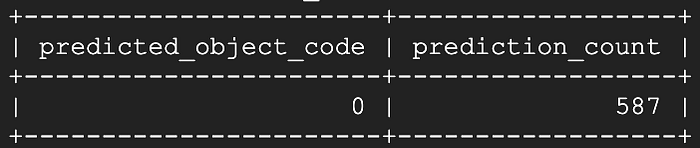
Nada mau! Parece que estamos perdendo os 13 segundos mais recentes de valores de temperatura transmitidos ao vivo de um ou mais dispositivos, e os 587 segundos restantes foram todos corretamente identificados como estado fechado.
Depois de abrir a janela #1 e esperar cerca de 15 segundos, rodei o script de previsão de novo:
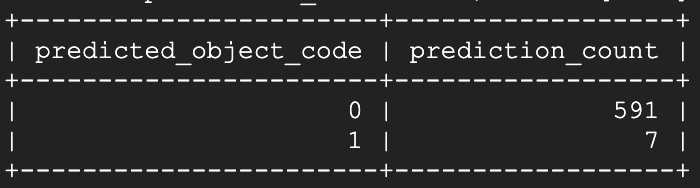
Voilà! Em poucos segundos depois de abrir, o modelo já começou a identificar aquela janela específica como aberta. Rodando o script de previsão novamente cerca de um minuto e meio depois:
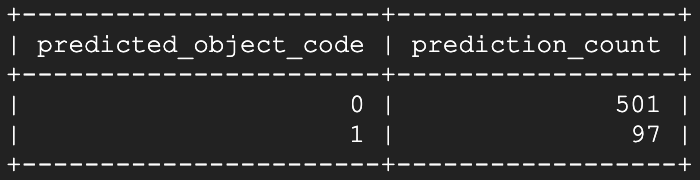
Dá para ver que o estado aberto está sendo identificado de forma clara e contínua!
Conforme o tempo passa, as previsões de estado aberto vão superando as de estado fechado em uma janela de 10 minutos, até dominarem a contagem de previsões nesse intervalo. A partir desse ponto, dá para escrever uma Cloud Function que toma uma ação e envia uma notificação para mim mandando fechar a tal janela!
Alertas por e-mail com uma Cloud Function
Infelizmente, o Google Cloud não oferece serviços de SMS ou e-mail, e direciona os clientes a usar empresas terceirizadas. Mostrar e-mail ou SMS por meio de uma Cloud Function com um serviço externo seria caro e deixaria este artigo, que já está longo, ainda maior, então vamos encerrar o tutorial por aqui.
Se você tiver um serviço de e-mail disponível, um script parecido com o a seguir deve funcionar bem para alertar via uma Cloud Function em Python:
Requirements para o gist open_window_alert.py
Recuperação rápida de temperaturas retrospectivas com uma external table do BigTable
Boa parte do SQL de transformação da tabela pivotada é dedicada a recuperar valores de "temperatura atual menos a passada" para cada segundo. Realizar esses INNER JOINs retrospectivos inteiramente no BigQuery, embora possível, não vai ter alta performance em escala. O BigQuery é mais bem otimizado para análises em escala massiva sobre uma única tabela. Como todos os data warehouses, ele não suporta índices, justamente por habilitar armazenamento e análises em escala de petabytes, e isso torna as operações de JOIN muito intensivas em computação e algo a ser evitado sempre que possível.
Vale considerar configurar uma instância do BigTable, o serviço de banco de dados NoSQL massivamente escalável do Google Cloud, que oferece tempos de resposta de um único dígito em milissegundos para queries de linhas individuais, e duplicar o armazenamento dos seus dados brutos de temperatura nesse serviço. Dentro do BigQuery, você pode configurar uma instância do BigTable como uma external table e, em seguida, executar queries nela como se fosse uma tabela do BigQuery.
Se você configurasse um segundo job do Dataflow que move os dados de IoT que chegam em uma Subscription do PubSub para o BigTable, garantindo o uso de uma chave primária combinando deviceId e datetime, conseguiria recuperar pontos de tempo individuais para um dispositivo e momento específicos muito mais rapidamente do que o SQL do BQ conseguiria buscando inteiramente em tabelas nativas do BigQuery.
Com essa abordagem, você atualizaria o SQL de geração da tabela pivotada para fazer um INNER JOIN com a external table do BigTable usando uma combinação device-datetime como chave do JOIN ON.
Em teoria, esse workflow deve ser mais escalável e ter alta performance, mas também será consideravelmente mais caro. Mesmo uma instância 'barata' de nó único para testes de desenvolvimento custa US$ 468/mês em us-central1. Ainda assim, vale a pena tentar implementar essa abordagem se você pretende fazer o deployment de operações de IoT em escala.
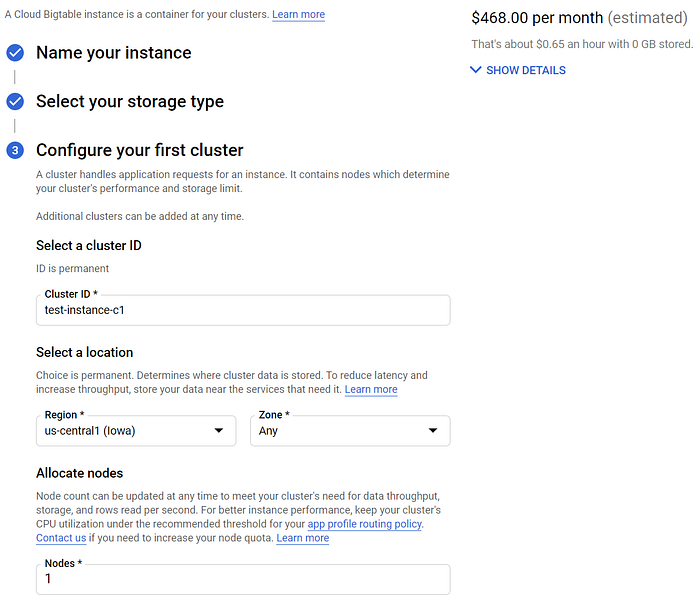
O BigTable é caro demais para um walkthrough de demo!
Parabéns por encarar até o fim este mergulho profundo em IoT e ML no GCP. Espero que tenha sido instrutivo e que ajude a acelerar sua jornada na ingestão, análise e uso real de datasets em larga escala na nuvem, aproveitando o máximo de serviços totalmente gerenciados, com auto-scaling e serverless, para minimizar o tempo gasto se preocupando com o uptime de cluster e maximizar o tempo dedicado a um trabalho que faz diferença.
Como recompensa pela sua paciência e perseverança, o mínimo que posso fazer é oferecer mais uma foto fofa de filhote!

Obrigado pela inspiração, Waffles e Maple! E obrigado a VOCÊ por todo o esforço!