本番運用レベルの機械学習モデルを構築・デプロイするのは、一筋縄ではいきません。Google Cloud AutoMLやCloud ML Engineといった既製の機械学習ツールを使う場合でも、本番システムでモデルを学習・運用するには、応用的なPython、複雑なモデルの理解、SQL、データベース技術など、幅広いスキルが必要になるのが通例です。本記事では、ごくシンプルなツールだけで、シェアカー・自転車・スクーター向けの予測システムを構築する方法をご紹介します。
BigQuery GISは、地理空間データの取り込み・管理・分析を可能にする新機能をGoogle BigQueryに追加するものです。BigQuery MLを使えば、標準SQLでBigQuery内から機械学習モデルを作成・実行できます。本記事では、地理空間かつ時系列のユースケースに対し、SQLだけでエンドツーエンドのMLパイプラインをデプロイする方法をご紹介します。
 Geo Vizによる予測結果の地図上での可視化
Geo Vizによる予測結果の地図上での可視化
自家用車の台数を減らすため、テルアビブ市はAutoTelというカーシェアリングのプロジェクトを立ち上げました。利用者はモバイルアプリで車を予約し、分単位で料金を支払います。2017年10月にスタートしたこのプロジェクトは7,500人を超える利用者を獲得し、その50%以上が週1回以上サービスを利用しています。
直近のデータを見ると、AutoTelのカーシェアリングは利用が伸び続けています。実際、利用が伸びすぎたことで新たな課題も生まれました。多くの交通サービスと同様、利用者に受け入れられるかどうかを大きく左右する要素は信頼性です。必要な場所・時間にたどり着けないことのコストは非常に大きいため、信頼性の低い交通手段は敬遠されがちです。
サービスの信頼性を確保するには、AutoTelは需要と供給を地理的にバランスさせる、つまり「必要な場所と時間に車があること」を担保しなければなりません。とはいえ、この最適化のことなど考えていない利用者が車を運転し、駐車する以上、これは極めて難しい課題です。多くの場合、車の分布と需要は相関しません。たとえば郊外の住宅街に駐車された車は、需要の高い都心へ運ばれるまでに長い時間がかかることがあり、結果として未稼働の車両が郊外に偏って溜まる現象が頻繁に起きます。
機械学習を活用すれば、AutoTelは特定の時刻における車両の地理空間的な空き状況を予測し、その結果をビジネスモデルに反映できます。たとえば、需要の高いエリアに駐車すると料金が安くなるよう価格を変動させる、あるいは供給過多で需要の少ないエリアから車を回収して需要の高いエリアへ戻すようメンテナンス計画を組む、といった施策が考えられます。AutoTelにとってメリットの大きい仕組みですが、開発はコストも複雑さも高くつきがちです。そこで本記事では、Google BigQueryだけを使い、利用可能な車両数を予測するモデルを構築・デプロイしていきます。本デモの完全なコードはこちらのGitHubリポジトリで公開しています。
パート1:データの取得
AutoTelのウェブサイトから、駐車中の車両の位置情報を2分おきに数か月分にわたって抽出しました。生データはCSV形式でGoogle Storageに保存し、その後BigQueryのテーブルに読み込んでいます。下の短いクリップは、Uberのkepler.glを使って記録データを可視化した様子です。
https://www.youtube.com/watch?v=ys6PfEugYrw
あわせて、テルアビブ市のオープンデータサイトからデータをダウンロードし、年齢別人口、商業エリア、ホテルや幼稚園の所在地、地区の境界などを含むテーブルをBQに読み込みました。これらの特徴量は利用可能な車両総数と線形の関係にあると仮定しています。データを分析した結果、この仮定が誤っていると判明する可能性もありますが、まずはここから進めていきます。
パート2:地理的結合とグルーピング
生データの各行は、特定の時刻における駐車中の車両の位置を表します。これを地区単位に集約するには、空間結合(spatial join)を使う必要がありました。
空間結合は次のコードで実行できます。
SELECT car_locs.*, ta_dis.neighbourhood_name FROM car_locs JOIN ta_dis ONST_WITHIN(ST_GEOGPOINT(car_locs.longitude, car_locs.latitude), ST_GeogFromText(ta_dis.area_polygon))
パート3:モデルの学習
2018年12月時点で、BQMLは2種類のモデル(回帰用の線形回帰、分類用のロジスティック回帰)に対応しています。次のSQLコマンドでモデルを学習します。
CREATE OR REPLACE MODE
L `autotel_demo.free_cars_model`--モデル保存先パス
OPTIONS
(model_type='linear_reg', ls_init_learn_rate=.015, l1_reg=0.1, l2_reg=0.1, data_split_method='seq', data_split_col='split_col', min_rel_progress=0.001, max_iterations=30),SELECT
free_cars label,-- 目的変数の宣言
timestamp split_col-- 説明変数:
,age5to14 ...FROM
`autotel_demo.autotel_dataset` as datasetWHERE
dataset.timestamp <TIMESTAMP
'2018-10-11'パート4:モデルの評価
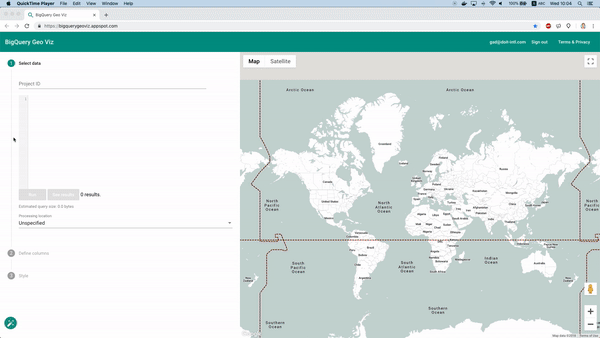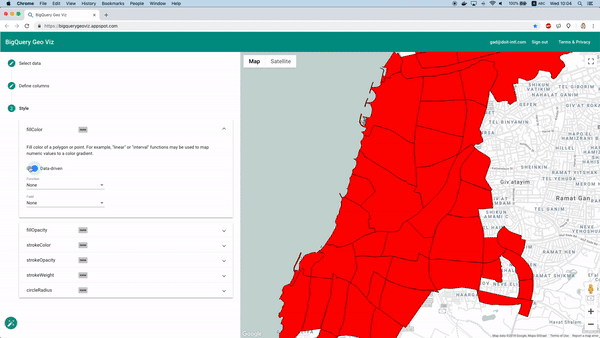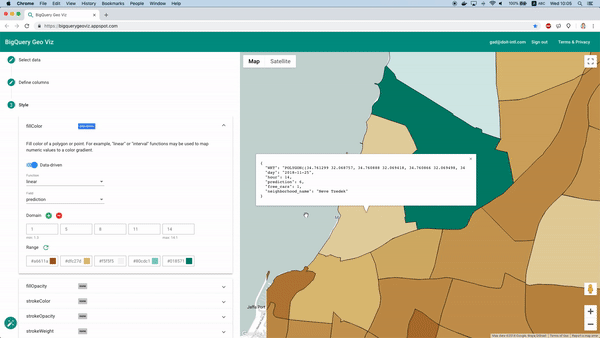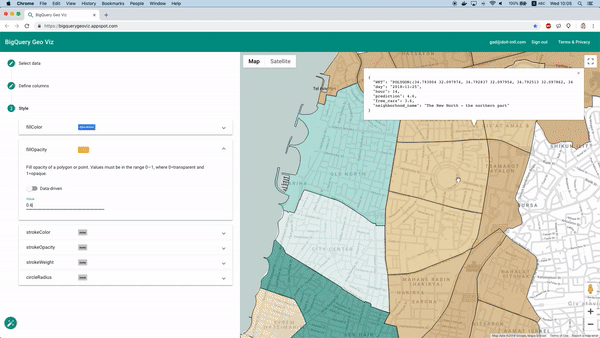
学習後は「Model.Evaluate」関数でモデルの性能指標を取得できます。多くの場面でこれらの指標は有用ですが、今回は地理空間的な予測タスクなので、予測結果を地図上で確認したいところです。
幸い、これはBigQuery Geo Vizで実現できます。このツールを使えば、地区境界のポリゴンを地図に表示し、特定時刻における予測値と実際の利用可能車両数を比較できます。誤差が地理的にどう分布しているかを把握するのに有効です。
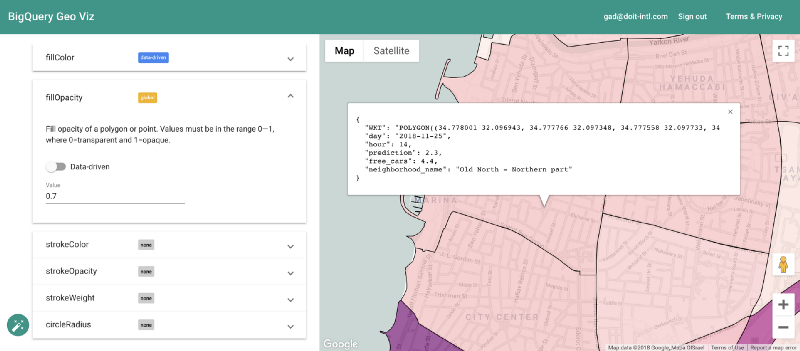 Geo Vizによる予測結果の可視化
Geo Vizによる予測結果の可視化
パート5 — 本番環境へのデプロイ
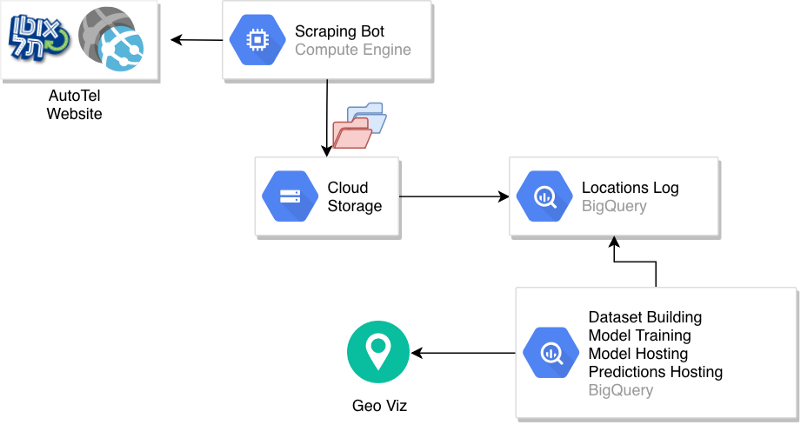
ここまでで構築した全体アーキテクチャを見てみましょう。
パイプラインのアーキテクチャ
スクレイピング用のボットがAutoTelのウェブサイトにアクセスし、車両の位置情報を含むCSVファイルをGCSのパーティション付きバケットにアップロードします。
その生データの上にBigQueryテーブルを構築し、データセットの作成とモデルの学習を手動で実行します。モデルが作成されるとBigQuery上でホストされ、予測の提供や予測テーブルの生成に使われます。予測テーブルは可視化や本番システムの他コンポーネントへのデータ提供にも活用できます。
ここで欠けている重要なピースが、プロセスの自動化です。位置情報テーブルへの新規データ投入、新しいデータセットの作成、モデル学習、予測の生成はいずれも手動ステップでした。これらを自動化する方法のひとつは、「BigQueryはクライアント呼び出しから利用できるサービスである」という事実を活かすことです。
ごくシンプルなPythonコードでこれらのステップを順に実行し、GoogleのCloud Composerで管理する、という方法があります。Cloud Composerはステップ間に依存関係があるこの種のタスクに非常にマッチします。ただし、タスク管理用のクラスタを常時稼働させる必要があり、本タスク単独で見るとコストはやや高くつくかもしれません。
もちろん、CronやKubernetes上のJenkinsなど、学習・予測スクリプトをスケジュール実行する手段は他にもあります。ただし注目すべきは、Google Cloud Composerなら1日あたり数ドルで、面倒な設定や権限まわりの調整から解放されるという点です。管理対象のプロセスが増えるほど、コスト効率はさらに高まります。
まとめ
機械学習モデルを本番システムに組み込みやすくする取り組みの一環として、BigQuery MLはパイプラインの中核部分をエンドツーエンドで担えるマネージドツールを提供しています。シンプルな線形回帰やロジスティック回帰で要件が満たせる場合、BQMLは以下をすべてカバーできます。
- データのホスティング
- データセットの作成
- モデルの学習とホスティング
- 推論とサービング
AirflowやJenkinsといったツールと組み合わせれば、これらのソフトウェアブロックを管理・自動化できます。
もう一点強調しておきたいのは、本プロセスではリソース割り当てやデータアクセスを意識する必要がなかったことです。これらを自動でこなしてくれるマネージドのデータウェアハウスの中で、ほぼすべての処理を完結させたためです。
\\\__________________________________
技術アドバイスおよび編集:Tony Braun
他の記事もぜひブログでご覧ください。TwitterでGadをフォローするのもおすすめです。