Construir y desplegar modelos de machine learning a nivel producción puede ser todo un desafío. Incluso con tecnologías como Google Cloud AutoML, Cloud ML Engine y otras herramientas de machine learning listas para usar, entrenar modelos y llevarlos a producción suele exigir un amplio conjunto de habilidades: programación avanzada en Python, comprensión de modelos complejos, SQL y bases de datos. En este post mostramos cómo armar un sistema de predicción para autos, bicicletas o scooters compartidos con herramientas muy simples.
BigQuery GIS suma nuevas capacidades a Google BigQuery para la ingesta, gestión y análisis de datos geoespaciales. BigQuery ML facilita la creación y ejecución de modelos de machine learning desde el propio BigQuery, usando SQL estándar. En este post intentaremos mostrar cómo aprovechar únicamente SQL para desplegar un pipeline de ML completo, de extremo a extremo, en un caso de uso geoespacial dependiente del tiempo.
 Visualización de las predicciones en un mapa con Geo Viz
Visualización de las predicciones en un mapa con Geo Viz
Para reducir la cantidad de autos particulares, la ciudad de Tel Aviv lanzó un proyecto de autos compartidos llamado AutoTel. Los usuarios pueden reservar un auto desde una app móvil y pagar por minuto. El proyecto, lanzado en octubre de 2017, atrajo a más de 7500 usuarios, de los cuales más del 50% utiliza el servicio al menos una vez por semana.
Los datos recientes muestran un crecimiento sostenido en el uso del servicio de autos compartidos AutoTel. De hecho, ese crecimiento fue tan fuerte que aparecieron problemas nuevos. Como en muchos servicios de transporte, uno de los factores clave para la adopción del público es la confiabilidad. La gente no adopta un servicio de transporte poco confiable, ya que el costo de no llegar al destino indicado en el momento deseado suele ser muy alto.
Para que el servicio sea confiable, AutoTel debe asegurarse de que la oferta y la demanda estén equilibradas geoespacialmente; es decir, que los autos estén donde y cuando se los necesita. Esta tarea es muy difícil, porque los autos los manejan y estacionan los propios clientes, que no tienen ningún interés en esa optimización. En la mayoría de los casos, la distribución de los autos no se correlaciona con la demanda: si un auto queda estacionado en un barrio suburbano, puede pasar mucho tiempo antes de que otro usuario lo lleve al centro, donde la demanda es alta; por eso, es habitual que se formen concentraciones de autos sin uso en las afueras.
Con machine learning, AutoTel puede predecir la disponibilidad geoespacial de los autos en momentos determinados y usar esas predicciones para ajustar su modelo de negocio. Podría, por ejemplo, modificar precios para que estacionar en zonas de alta demanda salga más barato, o planificar el mantenimiento de modo que los autos se retiren de zonas con mucha oferta y poca demanda y se devuelvan a zonas de alta demanda. Aunque este modelo puede beneficiar a AutoTel, desarrollarlo puede resultar costoso y complicado, así que en este post vamos a construir y desplegar un modelo que prediga la cantidad de autos disponibles, y todo usando únicamente Google BigQuery. El código completo de esta demo está disponible en este repositorio de GitHub.
Parte 1: Adquisición de datos
Desde el sitio web de AutoTel extraje la ubicación de los autos estacionados, cada dos minutos durante varios meses. Los datos en bruto se guardaron en Google Storage en formato CSV, y luego se cargaron en una tabla de BigQuery. Este clip corto muestra una visualización de los datos registrados con la herramienta kepler.gl de Uber.
https://www.youtube.com/watch?v=ys6PfEugYrw
Además, descargué datos del sitio de datos abiertos de la Municipalidad de Tel Aviv y cargué tablas en BQ con información sobre la edad de la población, áreas comerciales, ubicación de hoteles y jardines de infantes, y los límites de los barrios. Se asume que estas variables tienen una relación lineal con la cantidad total de autos disponibles; aunque al analizar los datos esa hipótesis pueda quedar refutada, partimos de ese supuesto.
Parte 2: Joins geográficos y agrupamiento
Cada fila del dataset en bruto representa la ubicación de un auto estacionado en un momento dado. Para agregar los datos a nivel de barrio, hizo falta usar una sentencia de spatial join.
El siguiente código muestra cómo realizar spatial joins:
SELECT car_locs.*, ta_dis.neighbourhood_name FROM car_locs JOIN ta_dis ONST_WITHIN(ST_GEOGPOINT(car_locs.longitude, car_locs.latitude), ST_GeogFromText(ta_dis.area_polygon))
Parte 3: Entrenamiento del modelo
A diciembre de 2018, BQML admite dos tipos de modelos: regresión lineal para tareas de regresión y regresión logística para tareas de clasificación. Entrenamos los modelos con el siguiente comando SQL:
CREATE OR REPLACE MODE
L `autotel_demo.free_cars_model`--ruta donde se guarda el modelo
OPTIONS
(model_type='linear_reg', ls_init_learn_rate=.015, l1_reg=0.1, l2_reg=0.1, data_split_method='seq', data_split_col='split_col', min_rel_progress=0.001, max_iterations=30),SELECT
free_cars label,-- declaración de la variable objetivo
timestamp split_col-- variables independientes:
,age5to14 ...FROM
`autotel_demo.autotel_dataset` as datasetWHERE
dataset.timestamp <TIMESTAMP
'2018-10-11'Parte 4: Evaluación del modelo
Después del entrenamiento, podemos usar la función "Model.Evaluate" para obtener métricas sobre el desempeño del modelo. Aunque estas métricas son útiles en muchos casos, esta vez estamos ante una tarea de predicción geoespacial y queremos ver las predicciones del modelo en un mapa.
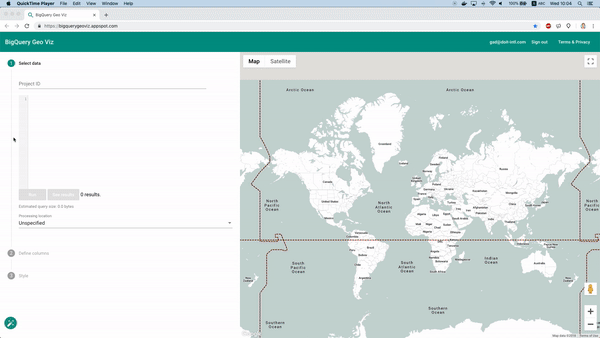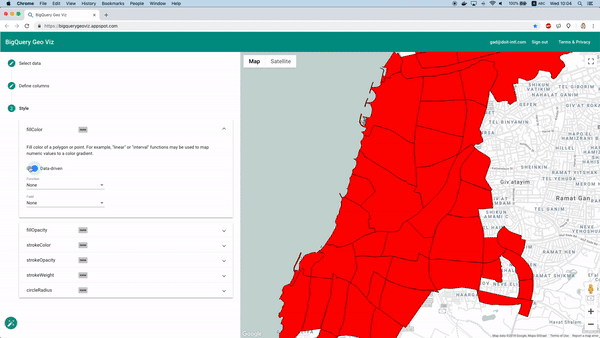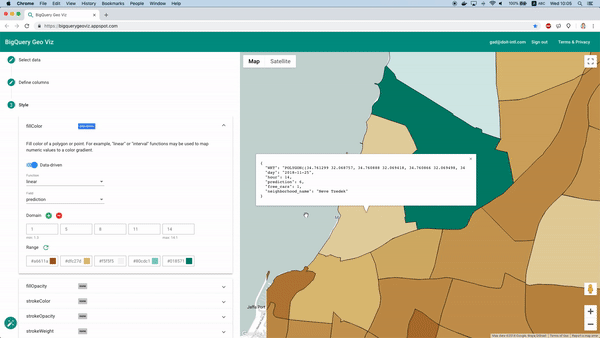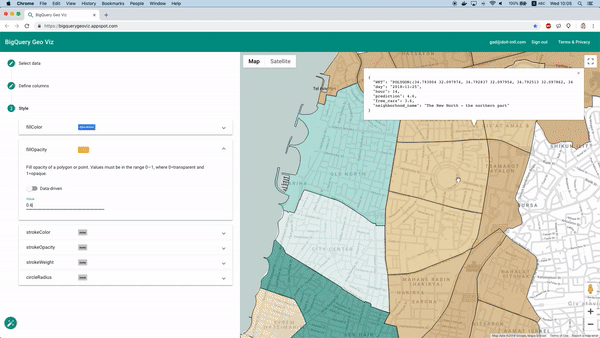
Por suerte, esto se puede hacer con la herramienta BigQuery Geo Viz. Con ella podemos mostrar en un mapa los polígonos que delimitan los barrios y comparar la predicción con la cantidad real de autos disponibles en un momento determinado. Este método permite analizar cómo se distribuye el error a nivel geográfico.
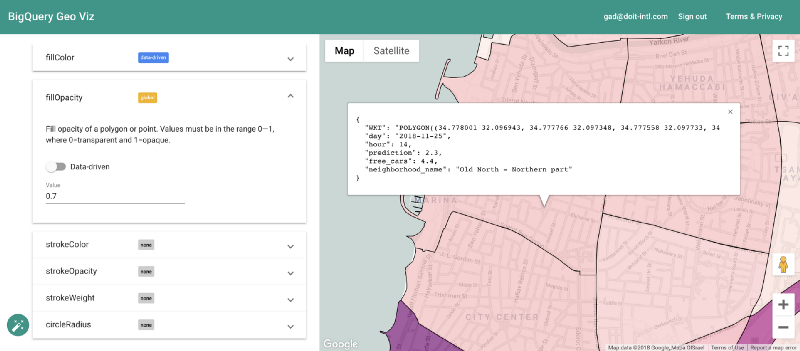 Visualización de las predicciones con Geo Viz
Visualización de las predicciones con Geo Viz
Parte 5 — Despliegue a producción
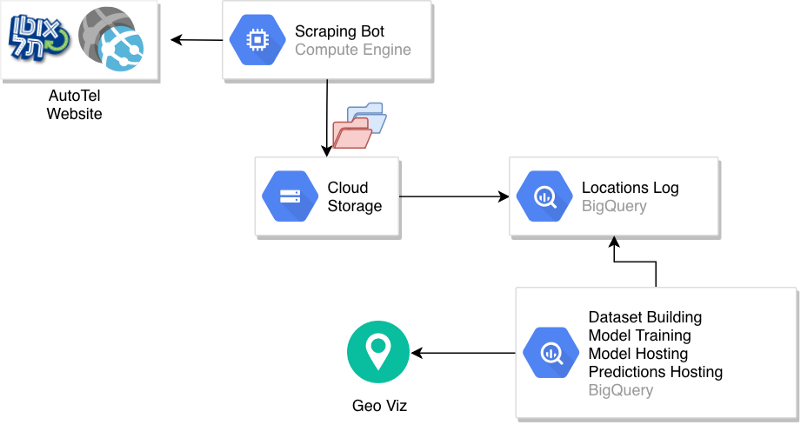
Veamos la arquitectura general que se construyó.
Arquitectura del pipeline
Un bot de scraping accede al sitio de AutoTel y sube un archivo CSV con las ubicaciones de los autos a un bucket particionado en GCS.
Sobre esos datos en bruto se construye una tabla de BigQuery y se inicia de forma manual el proceso de creación del dataset y de entrenamiento del modelo. Una vez creado, el modelo queda alojado en BigQuery y se usa para servir predicciones o para generar una tabla de predicciones. Esa tabla, a su vez, se puede usar para crear visualizaciones y alimentar otros componentes del sistema productivo.
Lo que falta aquí es la automatización del proceso. Cargar nuevos datos en la tabla de ubicaciones, crear nuevos datasets, entrenar modelos y generar predicciones se describieron como pasos manuales. Una forma de automatizar todo esto es aprovechar que BigQuery, en realidad, es un servicio al que se puede invocar mediante llamadas de cliente.
Podemos escribir un código Python muy simple que ejecute todos estos pasos y luego usar Google Cloud Composer para orquestarlos. Cloud Composer encaja muy bien con este tipo de tarea, dado que hay pasos que dependen de otros; sin embargo, ejecuta un cluster para administrarlos, lo que puede resultar bastante caro si se usa solo para esto.
Hay otras formas de programar el script de entrenamiento y predicción, como Cron o Jenkins, pero la cuestión es esta: por unos pocos dólares al día, Google Cloud Composer te evita tener que lidiar con configuraciones y permisos complicados; y cuantos más procesos gestiones con él, más rentable se vuelve.
Resumen
Como parte del esfuerzo por simplificar la integración de modelos de machine learning en sistemas productivos, BigQuery ML funciona como herramienta gestionada y puede servir como mecanismo de extremo a extremo para el núcleo del pipeline. Si un modelo simple de regresión lineal/logística alcanza, vas a ver que BQML soporta:
- Hosting de los datos
- Creación del dataset
- Entrenamiento y hosting del modelo
- Inferencia y servicio
Con otras herramientas como Airflow o Jenkins, estos bloques de software se pueden gestionar y automatizar.
Vale la pena destacar que en este proceso no nos tuvimos que preocupar por la asignación de recursos ni por el acceso a los datos, ya que la mayor parte del flujo se mantuvo dentro de un data warehouse gestionado que se encarga de eso por nosotros.
\\\__________________________________
Asesoría técnica y edición: Tony Braun
¿Querés leer más historias? Visitá nuestro blog o seguí a Gad en Twitter.