Construir e colocar em produção modelos de machine learning pode ser bem complicado. Mesmo com tecnologias como Google Cloud AutoML, Cloud ML Engine e outras ferramentas prontas de machine learning, treinar modelos e usá-los em produção costuma exigir um conjunto amplo de habilidades, que pode incluir programação avançada em Python, conhecimento de modelos complexos, SQL e tecnologias de banco de dados. Este post mostra como criar um sistema de previsão para carros, bicicletas e patinetes compartilhados usando ferramentas bem simples!
O BigQuery GIS traz novos recursos ao Google BigQuery que permitem ingerir, gerenciar e analisar dados geoespaciais. Já o BigQuery ML facilita criar e executar modelos de machine learning de dentro do próprio BigQuery, usando SQL padrão. Neste post, vamos mostrar como aproveitar apenas o SQL para implantar um pipeline de ML completo, de ponta a ponta, em um caso de uso geoespacial dependente do tempo.
 Usando o Geo Viz para visualizar previsões em um mapa
Usando o Geo Viz para visualizar previsões em um mapa
Para reduzir o número de carros particulares, a cidade de Tel Aviv lançou um projeto de carros compartilhados, chamado AutoTel. Pelo serviço, os usuários reservam um carro pelo aplicativo e pagam por minuto de uso. Lançado em outubro de 2017, o projeto atraiu mais de 7.500 usuários, e mais de 50% deles usam o serviço pelo menos uma vez por semana.
Os dados mais recentes mostram um crescimento contínuo no uso do serviço de carros compartilhados da AutoTel. Aliás, o uso cresceu tanto que novos problemas apareceram. Como acontece em muitos serviços de transporte, um dos principais fatores na adoção pelo público é a confiabilidade. Os passageiros não adotam um serviço de transporte pouco confiável, já que o custo de não chegar ao destino na hora certa costuma ser muito alto.
Para que o serviço seja confiável, a AutoTel precisa garantir que oferta e demanda fiquem geoespacialmente equilibradas — ou seja, que os carros estejam onde e quando são necessários. Essa tarefa é extremamente difícil, porque os carros são dirigidos e estacionados por clientes que não têm nenhum compromisso com essa otimização. Na maior parte do tempo, a distribuição dos carros não tem correlação com a demanda: por exemplo, se um carro fica estacionado em um bairro afastado, pode demorar muito até que outro usuário o leve para o centro, onde a procura é alta. Por isso, é muito comum encontrar grupos de carros parados nas regiões periféricas da cidade.
Com machine learning, a AutoTel consegue prever a disponibilidade geoespacial dos carros em determinados horários e usar essas previsões para ajustar o modelo de negócio. Eles poderiam, por exemplo, alterar os preços para que ficasse mais barato estacionar carros em áreas de alta demanda, ou planejar o programa de manutenção de modo que os carros fossem recolhidos em áreas de alta oferta e baixa demanda e devolvidos em áreas de alta demanda. Embora esse modelo possa ser útil para a AutoTel, desenvolvê-lo pode ser caro e complicado. Por isso, neste post vamos construir e implantar um modelo que prevê o número de carros disponíveis usando apenas o Google BigQuery. O código completo desta demonstração está disponível neste repositório no GitHub.
Parte 1: Aquisição dos dados
Do site da AutoTel, extraí a localização dos carros estacionados a cada dois minutos durante vários meses. Os dados brutos foram salvos no Google Storage em formato CSV e, depois, carregados em uma tabela do BigQuery. Este vídeo curto mostra uma visualização dos dados registrados na ferramenta kepler.gl, da Uber.
https://www.youtube.com/watch?v=ys6PfEugYrw
Também baixei dados do site de dados abertos da Prefeitura de Tel Aviv e carreguei tabelas no BQ com informações sobre faixa etária da população, áreas comerciais, localização de hotéis e creches e os limites dos bairros. Partimos do pressuposto de que essas variáveis têm relação linear com o número total de carros disponíveis e, mesmo correndo o risco de essa hipótese ser refutada na análise, é por aí que começamos.
Parte 2: Joins e agrupamentos geográficos
Cada linha do dataset bruto representa a localização de um carro estacionado em um determinado momento. Para agregar os dados em nível de bairro, foi preciso usar um comando de spatial join.
O código a seguir mostra como executar spatial joins:
SELECT car_locs.*, ta_dis.neighbourhood_name FROM car_locs JOIN ta_dis ONST_WITHIN(ST_GEOGPOINT(car_locs.longitude, car_locs.latitude), ST_GeogFromText(ta_dis.area_polygon))
Parte 3: Treinamento do modelo
Em dezembro de 2018, o BQML oferece suporte a dois tipos de modelos — regressão linear para tarefas de regressão e regressão logística para tarefas de classificação. Treinamos os modelos com o seguinte comando SQL:
CREATE OR REPLACE MODE
L `autotel_demo.free_cars_model`--caminho de salvamento do modelo
OPTIONS
(model_type='linear_reg', ls_init_learn_rate=.015, l1_reg=0.1, l2_reg=0.1, data_split_method='seq', data_split_col='split_col', min_rel_progress=0.001, max_iterations=30),SELECT
free_cars label,-- declarando a variável-alvo
timestamp split_col-- variáveis independentes:
,age5to14 ...FROM
`autotel_demo.autotel_dataset` as datasetWHERE
dataset.timestamp <TIMESTAMP
'2018-10-11'Parte 4: Avaliação do modelo
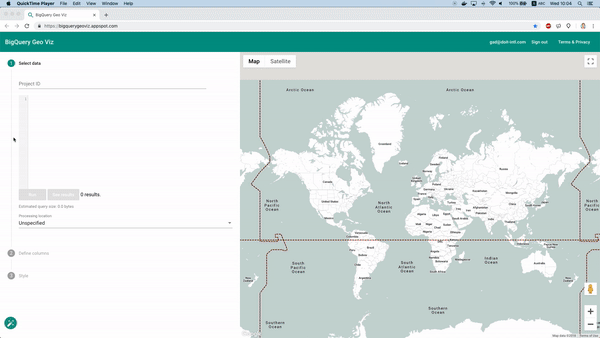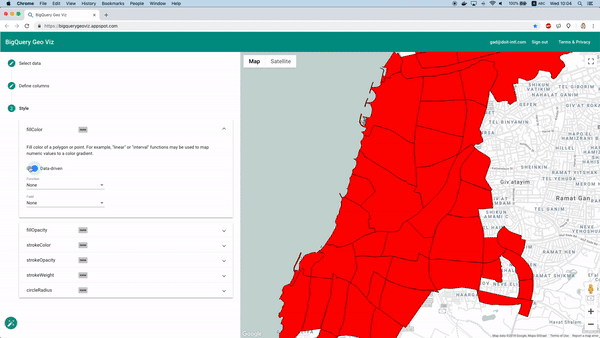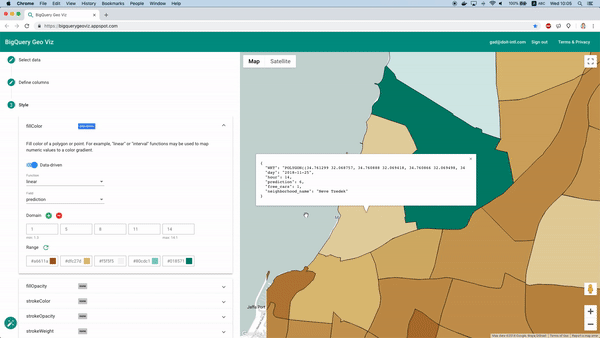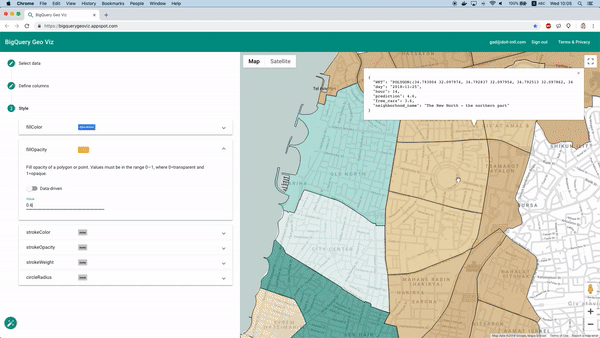
Depois de treinar, podemos usar a função "Model.Evaluate" para obter métricas de desempenho do modelo. Essas métricas são úteis em vários cenários, mas, neste caso, estamos diante de uma tarefa de previsão geoespacial e queremos ver as previsões do modelo em um mapa.
Felizmente, dá para fazer isso com a ferramenta BigQuery Geo Viz. Com ela, conseguimos exibir os polígonos dos bairros em um mapa e comparar a previsão com o número real de carros disponíveis em um momento específico. Esse método permite analisar como o erro se distribui geograficamente.
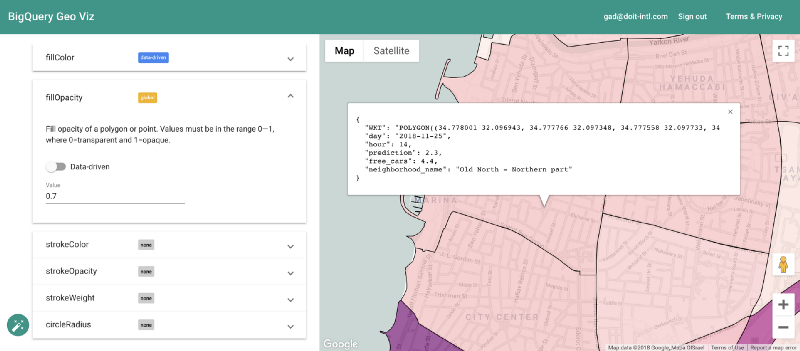 Visualizando as previsões com o Geo Viz
Visualizando as previsões com o Geo Viz
Parte 5 — Implantação em produção
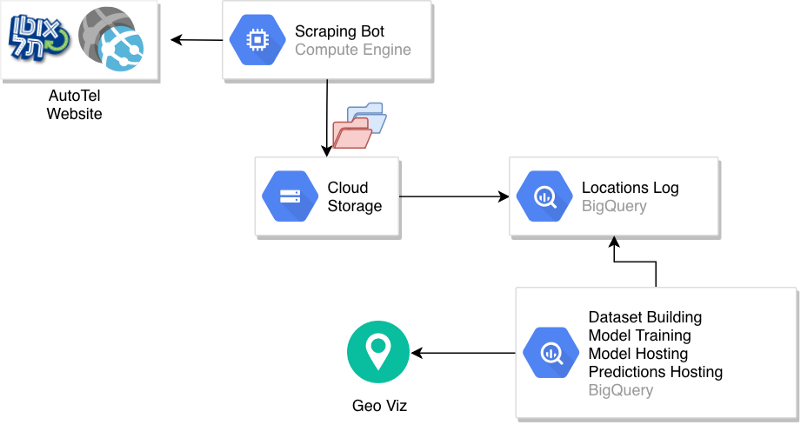
Vamos analisar a arquitetura geral que foi criada.
Arquitetura do pipeline
Um bot de scraping acessa o site da AutoTel e envia um arquivo CSV com a localização dos carros para um bucket particionado no GCS.
Uma tabela do BigQuery é construída sobre os dados brutos, e a criação do dataset e o treinamento do modelo são iniciados manualmente. Depois que o modelo é criado, ele fica hospedado no BigQuery e é usado para gerar previsões sob demanda ou produzir uma tabela de previsões. Essa tabela pode então alimentar visualizações e outros componentes do sistema de produção.
O ponto que falta aqui é a automação do processo. Carregar novos dados na tabela de localizações, criar novos datasets, treinar modelos e gerar previsões — tudo isso foi descrito como etapas manuais. Uma forma de automatizar é aproveitar o fato de que o BigQuery, na prática, é um serviço que pode ser acionado por chamadas de cliente.
Dá para escrever um código Python bem simples para executar todas essas etapas e, em seguida, usar o Google Cloud Composer para gerenciá-las. O Cloud Composer cai como uma luva nesse tipo de tarefa, já que algumas etapas dependem umas das outras; mas, como ele executa um cluster para gerenciar as tarefas, pode ficar caro se for usado só para isso.
Você pode pensar em outras formas de agendar o script de treinamento e previsão, como o Cron ou o Jenkins, mas a questão é a seguinte: por alguns dólares por dia, o Google Cloud Composer poupa você de configurações e permissões complicadas — e quanto mais processos forem gerenciados por ele, mais vantajoso ele se torna.
Resumo
Como parte do esforço para simplificar a integração de modelos de machine learning a sistemas de produção, o BigQuery ML é uma ferramenta gerenciada que pode atuar como um mecanismo de ponta a ponta na parte central do pipeline. Se um modelo simples de regressão linear ou logística for suficiente, você vai ver que o BQML dá conta de:
- Hospedagem dos dados
- Criação do dataset
- Treinamento e hospedagem do modelo
- Inferência e disponibilização
Com outras ferramentas, como Airflow ou Jenkins, esses blocos podem ser gerenciados e automatizados.
Vale destacar que, neste processo, não precisamos nos preocupar com alocação de recursos nem com acesso aos dados, já que mantivemos quase tudo dentro de um data warehouse gerenciado, que cuida disso para nós.
\\\__________________________________
Consultoria técnica e edição: Tony Braun
Quer mais conteúdos? Confira nosso blog ou siga o Gad no Twitter.