Concevoir et déployer des modèles de machine learning de niveau production peut s'avérer délicat. Même avec des technologies comme Google Cloud AutoML, Cloud ML Engine et d'autres outils de machine learning prêts à l'emploi, entraîner ses modèles et les exploiter en production exige généralement un large éventail de compétences : Python avancé, modèles complexes, SQL et bases de données. Cet article montre comment bâtir un système de prédiction pour des voitures, vélos ou trottinettes en libre-service avec des outils très simples.
BigQuery GIS dote Google BigQuery de nouvelles capacités d'ingestion, de gestion et d'analyse de données géospatiales. BigQuery ML facilite la création et l'exécution de modèles de machine learning directement dans BigQuery, en SQL standard. Dans cet article, nous montrons comment s'appuyer uniquement sur le SQL pour déployer un pipeline ML complet de bout en bout sur un cas d'usage géospatial dépendant du temps.
 Visualisation des prédictions sur une carte avec Geo Viz
Visualisation des prédictions sur une carte avec Geo Viz
Pour réduire le nombre de voitures particulières, la ville de Tel-Aviv a lancé un projet d'autopartage baptisé AutoTel. Les utilisateurs réservent une voiture via une application mobile et paient à la minute. Lancé en octobre 2017, le projet a séduit plus de 7 500 utilisateurs, dont plus de 50 % se servent du service au moins une fois par semaine.
Les données récentes témoignent d'une croissance soutenue de l'usage du service AutoTel. La fréquentation a même atteint un tel niveau que de nouveaux problèmes sont apparus. Comme pour beaucoup de services de transport, la fiabilité conditionne largement l'adoption par le public. Les passagers se détournent d'un service peu fiable, car ne pas arriver à destination à l'heure voulue coûte généralement cher.
Pour garantir cette fiabilité, AutoTel doit veiller à ce que l'offre et la demande soient équilibrées géographiquement, autrement dit que les voitures soient disponibles aux bons endroits et au bon moment. La tâche est extrêmement complexe : ce sont les clients qui conduisent et stationnent les véhicules, sans aucun souci de cet objectif d'optimisation. La plupart du temps, la répartition des voitures n'est pas corrélée à la demande : si une voiture est garée dans un quartier résidentiel, il peut s'écouler beaucoup de temps avant qu'un autre utilisateur ne la ramène vers le centre-ville, où la demande est forte ; on observe ainsi très souvent des grappes de voitures inutilisées en périphérie.
Grâce au machine learning, AutoTel peut prédire la disponibilité géospatiale des voitures à un instant donné et exploiter ces prédictions pour ajuster son modèle économique. L'entreprise pourrait par exemple moduler les tarifs pour rendre le stationnement moins coûteux dans les zones à forte demande, ou planifier la maintenance pour récupérer les voitures dans les zones à forte offre et faible demande, et les redéployer là où la demande est élevée. Si ce modèle peut profiter à AutoTel, son développement est potentiellement coûteux et complexe ; nous allons donc, dans cet article, construire et déployer un modèle qui prédit le nombre de voitures disponibles, en n'utilisant que Google BigQuery. Le code complet de cette démonstration est disponible dans ce dépôt GitHub.
Partie 1 : Acquisition des données
Depuis le site web d'AutoTel, j'ai extrait l'emplacement des voitures stationnées toutes les deux minutes pendant plusieurs mois. Les données brutes ont été enregistrées dans Google Storage au format CSV, puis chargées dans une table BigQuery. Ce court extrait montre une visualisation des données collectées avec kepler.gl, l'outil d'Uber.
https://www.youtube.com/watch?v=ys6PfEugYrw
J'ai également récupéré des données depuis le site open data de la municipalité de Tel-Aviv, et chargé dans BQ des tables couvrant l'âge de la population, les zones commerciales, les emplacements des hôtels et des crèches, ainsi que les limites des quartiers. Nous partons du principe que ces variables entretiennent une relation linéaire avec le nombre total de voitures disponibles ; l'analyse des données pourra nous donner tort, mais c'est notre point de départ.
Partie 2 : Jointures géographiques et regroupement
Chaque ligne du jeu de données brut correspond à l'emplacement d'une voiture stationnée à un instant donné. Pour agréger les données à l'échelle du quartier, j'ai dû recourir à une jointure spatiale.
Le code suivant montre comment effectuer ces jointures spatiales :
SELECT car_locs.*, ta_dis.neighbourhood_name FROM car_locs JOIN ta_dis ONST_WITHIN(ST_GEOGPOINT(car_locs.longitude, car_locs.latitude), ST_GeogFromText(ta_dis.area_polygon))
Partie 3 : Entraînement du modèle
En décembre 2018, BQML prend en charge deux types de modèles : la régression linéaire pour la régression et la régression logistique pour la classification. Nous entraînons les modèles avec la commande SQL suivante :
CREATE OR REPLACE MODE
L `autotel_demo.free_cars_model`--chemin de sauvegarde du modèle
OPTIONS
(model_type='linear_reg', ls_init_learn_rate=.015, l1_reg=0.1, l2_reg=0.1, data_split_method='seq', data_split_col='split_col', min_rel_progress=0.001, max_iterations=30),SELECT
free_cars label,-- déclaration de la variable cible
timestamp split_col-- variables indépendantes :
,age5to14 ...FROM
`autotel_demo.autotel_dataset` as datasetWHERE
dataset.timestamp <TIMESTAMP
'2018-10-11'Partie 4 : Évaluation du modèle
Une fois l'entraînement terminé, la fonction Model.Evaluate fournit des métriques sur la performance du modèle. Si ces métriques sont utiles dans bien des cas, il s'agit ici d'une tâche de prédiction géospatiale : nous voulons aussi visualiser les prédictions du modèle sur une carte.
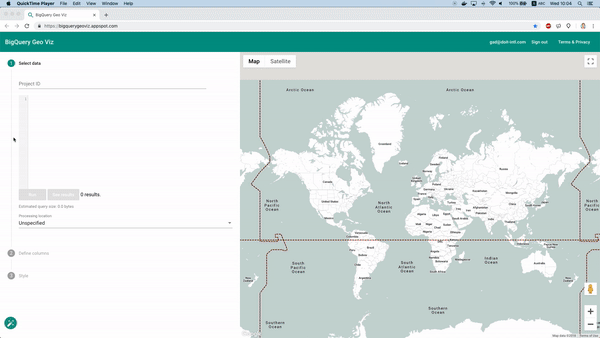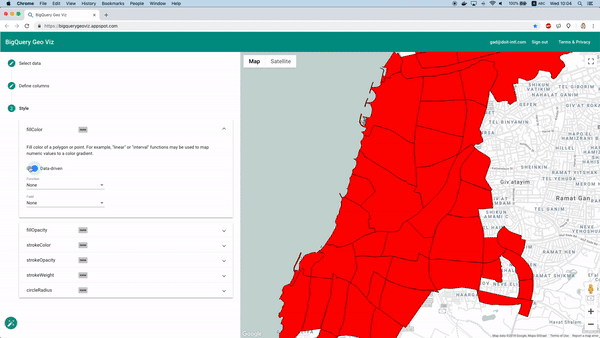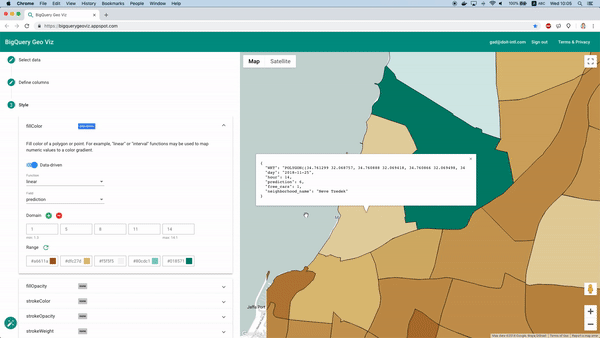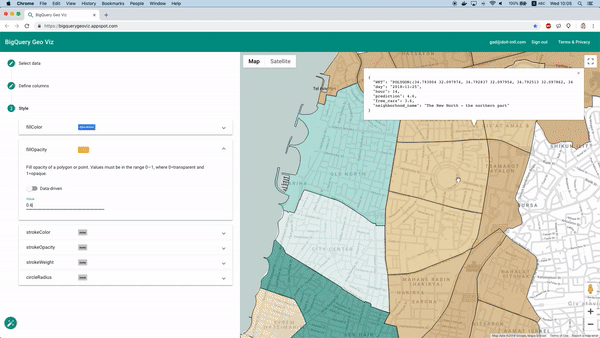
Heureusement, l'outil BigQuery Geo Viz le permet. Il affiche sur une carte les polygones délimitant les quartiers et permet de comparer les prédictions au nombre réel de voitures disponibles à un instant précis. On peut ainsi observer la répartition géographique de l'erreur.
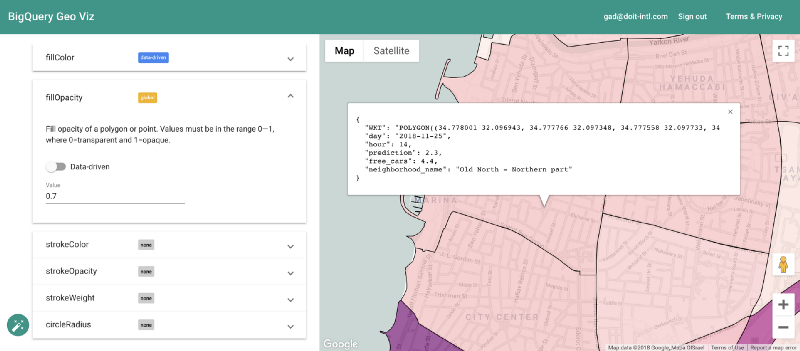 Visualisation des prédictions avec Geo Viz
Visualisation des prédictions avec Geo Viz
Partie 5 — Mise en production
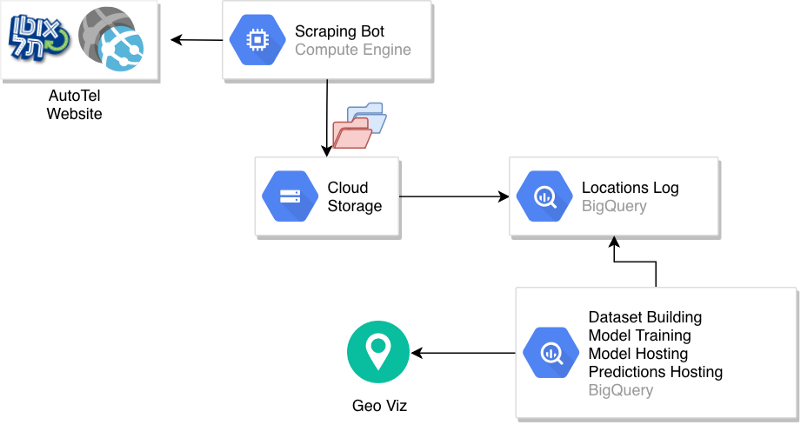
Examinons l'architecture globale mise en place.
Architecture du pipeline
Un bot de scraping interroge le site AutoTel et envoie un fichier CSV contenant les emplacements des voitures vers un bucket partitionné dans GCS.
Une table BigQuery est construite à partir des données brutes, puis la création du jeu de données et l'entraînement du modèle sont lancés manuellement. Une fois créé, le modèle est hébergé dans BigQuery et sert à produire des prédictions, soit à la volée, soit dans une table de prédictions. Cette table peut ensuite alimenter des visualisations ou d'autres composants du système de production.
L'élément qui fait défaut ici, c'est l'automatisation. Le chargement de nouvelles données dans la table des emplacements, la création de jeux de données, l'entraînement des modèles et la génération des prédictions ont tous été décrits comme des étapes manuelles. Une façon d'automatiser ce processus consiste à tirer parti du fait que BigQuery est en réalité un service que l'on peut invoquer via des appels clients.
On peut écrire un script Python très simple pour exécuter toutes ces étapes, puis confier leur orchestration à Google Cloud Composer. Cloud Composer convient très bien à ce type de scénario, car certaines étapes dépendent des autres ; il fait toutefois tourner un cluster pour gérer les tâches, ce qui peut s'avérer assez coûteux si l'on ne traite que ce seul cas d'usage.
D'autres approches sont envisageables pour planifier le script d'entraînement et de prédiction, comme Cron ou Jenkins. L'intérêt de Cloud Composer ? Pour quelques dollars par jour, il vous épargne des configurations et des réglages d'autorisations laborieux, et plus vous y orchestrez de processus, plus il devient rentable.
Synthèse
Dans la perspective de simplifier l'intégration des modèles de machine learning aux systèmes de production, BigQuery ML offre un outil managé qui peut servir de mécanisme de bout en bout pour le cœur du pipeline. Si un simple modèle de régression linéaire ou logistique suffit, BQML prend en charge :
- l'hébergement des données ;
- la création du jeu de données ;
- l'entraînement et l'hébergement du modèle ;
- l'inférence et la mise à disposition.
Couplés à d'autres outils comme Airflow ou Jenkins, ces blocs logiciels peuvent être orchestrés et automatisés.
À noter : tout au long de ce processus, nous n'avons pas eu à nous préoccuper de l'allocation des ressources ni de l'accès aux données, puisque l'essentiel se déroule au sein d'un entrepôt de données managé qui s'en charge à notre place.
\\\__________________________________
Conseil technique et relecture : Tony Braun
Envie d'autres articles ? Consultez notre blog ou suivez Gad sur Twitter.