Produktionsreife Machine-Learning-Modelle zu bauen und in den Live-Betrieb zu bringen, ist alles andere als trivial. Selbst mit Werkzeugen wie Google Cloud AutoML, Cloud ML Engine und anderen Out-of-the-Box-ML-Tools braucht es für Training und produktiven Einsatz meist ein breites Skill-Set: fortgeschrittenes Python, ein Gespür für komplexe Modelle, SQL- und Datenbank-Know-how. Dieser Beitrag zeigt, wie sich mit ganz einfachen Mitteln ein Vorhersagesystem für Carsharing, Bike- und Scooter-Sharing aufbauen lässt.
BigQuery GIS erweitert Google BigQuery um Funktionen für die Erfassung, Verwaltung und Analyse von Geodaten. BigQuery ML erlaubt es, Machine-Learning-Modelle direkt in BigQuery mit Standard-SQL zu erstellen und auszuführen. In diesem Beitrag zeigen wir, wie sich allein mit SQL eine vollständige End-to-End-ML-Pipeline für einen geospatialen, zeitabhängigen Use Case umsetzen lässt.
 Vorhersagen mit Geo Viz auf der Karte visualisieren
Vorhersagen mit Geo Viz auf der Karte visualisieren
Um den Bestand privater Pkw zu reduzieren, hat die Stadt Tel Aviv das Carsharing-Projekt AutoTel ins Leben gerufen. Die Nutzer reservieren ein Fahrzeug per App und zahlen minutengenau. Das im Oktober 2017 gestartete Projekt hat mehr als 7.500 Nutzer gewonnen, von denen über 50 % den Service mindestens einmal pro Woche in Anspruch nehmen.
Aktuelle Zahlen zeigen ein konstantes Wachstum bei der Nutzung des AutoTel-Carsharings – so stark, dass dadurch neue Probleme entstanden sind. Wie bei jedem Verkehrsangebot entscheidet vor allem die Zuverlässigkeit über die Akzeptanz. Wer nicht darauf vertrauen kann, pünktlich am Ziel anzukommen, weicht auf andere Angebote aus – die Folgekosten unzuverlässiger Mobilität sind in der Regel hoch.
Damit der Service zuverlässig bleibt, muss AutoTel Angebot und Nachfrage räumlich in Einklang bringen: Die Fahrzeuge müssen dort und dann verfügbar sein, wo und wann sie gebraucht werden. Das ist anspruchsvoll, denn gefahren und abgestellt werden die Autos von Kunden, deren Verhalten sich nicht an dieser Optimierung orientiert. Meist passt die Verteilung der Fahrzeuge nicht zur Nachfrage: Steht ein Auto erst einmal in einer Vorortsiedlung, kann es lange dauern, bis es jemand wieder ins Zentrum fährt, wo die Nachfrage hoch ist. So sammeln sich am Stadtrand häufig ganze Cluster ungenutzter Fahrzeuge.
Mit Machine Learning kann AutoTel die geospatiale Verfügbarkeit der Fahrzeuge zu bestimmten Zeiten prognostizieren und diese Vorhersagen ins Geschäftsmodell einfließen lassen. Beispielsweise lassen sich Preise so steuern, dass das Abstellen in nachfragestarken Zonen günstiger wird, oder die Wartung lässt sich so planen, dass Fahrzeuge gezielt aus angebotsstarken, nachfrageschwachen Gebieten in Hochnachfragezonen umgesetzt werden. So wertvoll ein solches Modell für AutoTel auch wäre – Entwicklung und Betrieb können teuer und komplex sein. Deshalb bauen und deployen wir in diesem Beitrag ein Modell, das die Anzahl verfügbarer Fahrzeuge vorhersagt – und das ausschließlich mit Google BigQuery. Den vollständigen Code zur Demo finden Sie in diesem GitHub-Repo.
Teil 1: Datenerhebung
Von der AutoTel-Website habe ich über mehrere Monate hinweg im Zwei-Minuten-Takt die Standorte der geparkten Fahrzeuge ausgelesen. Die Rohdaten landeten als CSV in Google Storage und wurden anschließend in eine BigQuery-Tabelle geladen. Dieser kurze Clip zeigt eine Visualisierung der erfassten Daten mit Ubers kepler.gl-Tool:
https://www.youtube.com/watch?v=ys6PfEugYrw
Zusätzlich habe ich Daten vom Open-Data-Portal der Stadt Tel Aviv heruntergeladen und Tabellen zu Altersstruktur der Bevölkerung, Gewerbegebieten, Hotel- und Kindergartenstandorten sowie Stadtteilgrenzen in BQ geladen. Die Annahme: Diese Merkmale stehen in einem linearen Verhältnis zur Gesamtzahl verfügbarer Fahrzeuge. Vielleicht widerlegt die Analyse das später noch – aber damit starten wir.
Teil 2: Geografische Joins und Gruppierungen
Jede Zeile im Rohdatensatz steht für den Standort eines geparkten Fahrzeugs zu einem bestimmten Zeitpunkt. Um die Daten auf Stadtteilebene zu aggregieren, war ein Spatial Join nötig.
Der folgende Code zeigt, wie ein Spatial Join ausgeführt wird:
SELECT car_locs.*, ta_dis.neighbourhood_name FROM car_locs JOIN ta_dis ONST_WITHIN(ST_GEOGPOINT(car_locs.longitude, car_locs.latitude), ST_GeogFromText(ta_dis.area_polygon))
Teil 3: Modelltraining
Stand Dezember 2018 unterstützt BQML zwei Modelltypen – lineare Regression für Regressionsaufgaben und logistische Regression für Klassifikationsaufgaben. Trainiert werden die Modelle mit folgendem SQL-Befehl:
CREATE OR REPLACE MODE
L `autotel_demo.free_cars_model`--Speicherpfad des Modells
OPTIONS
(model_type='linear_reg', ls_init_learn_rate=.015, l1_reg=0.1, l2_reg=0.1, data_split_method='seq', data_split_col='split_col', min_rel_progress=0.001, max_iterations=30),SELECT
free_cars label,-- Zielvariable definieren
timestamp split_col-- unabhängige Variablen:
,age5to14 ...FROM
`autotel_demo.autotel_dataset` as datasetWHERE
dataset.timestamp <TIMESTAMP
'2018-10-11'Teil 4: Modellbewertung
Nach dem Training liefert die Funktion "Model.Evaluate" Kennzahlen zur Modellgüte. In vielen Fällen reichen diese Metriken aus – hier geht es jedoch um eine geospatiale Vorhersage, und wir möchten die Prognosen auf einer Karte sehen.
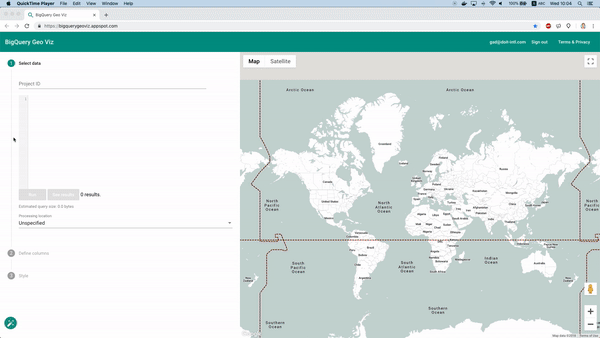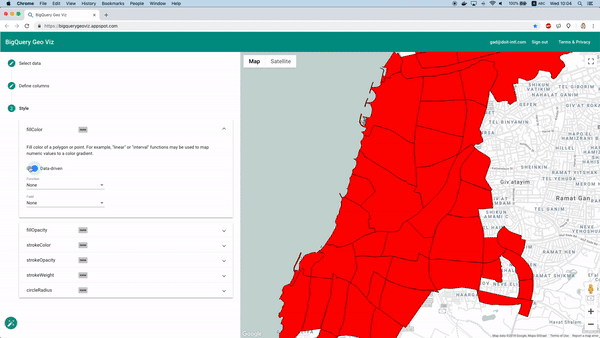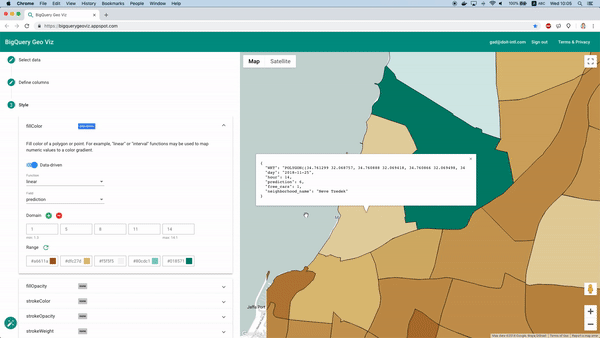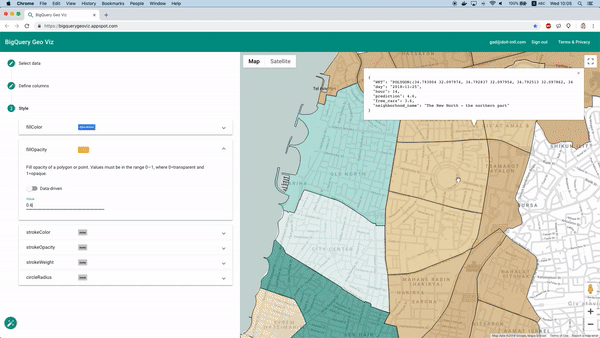
Zum Glück lässt sich das mit dem Tool BigQuery Geo Viz umsetzen. Damit stellen wir die Polygone der Stadtteilgrenzen auf einer Karte dar und vergleichen die Vorhersage mit der tatsächlichen Anzahl verfügbarer Fahrzeuge zu einem bestimmten Zeitpunkt. So sehen wir auf einen Blick, wie sich der Fehler räumlich verteilt.
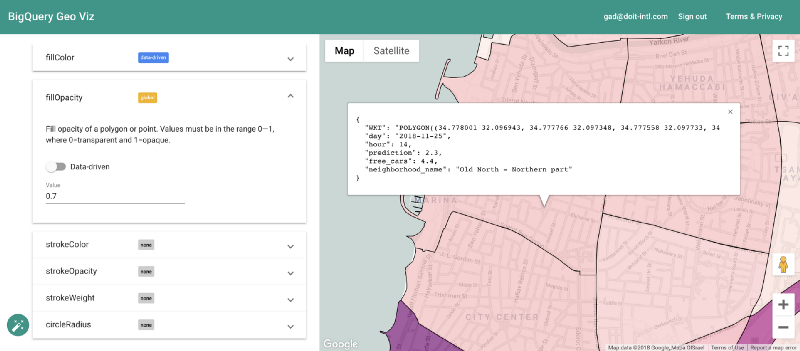 Vorhersagen mit Geo Viz visualisieren
Vorhersagen mit Geo Viz visualisieren
Teil 5 – Deployment in die Produktion
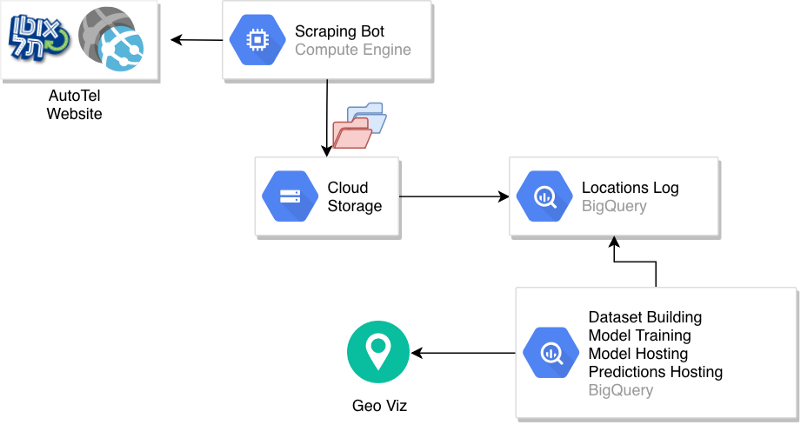
Werfen wir einen Blick auf die Gesamtarchitektur, die dabei entstanden ist:
Pipeline-Architektur
Ein Scraping-Bot greift auf die AutoTel-Website zu und lädt eine CSV mit den Fahrzeugstandorten in einen partitionierten Bucket auf GCS.
Auf den Rohdaten setzt eine BigQuery-Tabelle auf; Datensatzaufbereitung und Modelltraining werden manuell angestoßen. Nach dem Training liegt das Modell in BigQuery, liefert direkt Vorhersagen oder erzeugt eine Predictions-Tabelle. Diese Tabelle dient anschließend als Basis für Visualisierungen und weitere Komponenten des Produktivsystems.
Was hier noch fehlt, ist die Automatisierung. Neue Daten in die Standort-Tabelle laden, neue Datensätze erstellen, Modelle trainieren und Vorhersagen erzeugen – all das wurde bisher als manueller Schritt beschrieben. Ein Weg zur Automatisierung: BigQuery ist letztlich ein Service, den man über Client-Aufrufe ansteuern kann.
Wir können also ein paar Zeilen Python schreiben, die diese Schritte ausführen, und das Ganze dann mit Google Cloud Composer orchestrieren. Cloud Composer eignet sich für solche Aufgaben sehr gut, weil einige Schritte voneinander abhängen. Allerdings betreibt der Dienst ein Cluster zur Verwaltung der Tasks, was nur für diesen einen Anwendungsfall recht teuer werden kann.
Für die Planung des Trainings- und Vorhersage-Skripts gäbe es auch andere Wege – etwa Cron oder Jenkins. Aber: Für ein paar Dollar pro Tag erspart Ihnen Google Cloud Composer den Aufwand für komplexe Konfigurations- und Berechtigungsthemen – und je mehr Prozesse Sie damit verwalten, desto wirtschaftlicher wird es.
Fazit
Um die Integration von Machine-Learning-Modellen in Produktivsysteme einfacher zu machen, bietet BigQuery ML einen Managed Service, der den Kern der Pipeline als End-to-End-Mechanismus abdeckt. Reicht ein einfaches lineares oder logistisches Regressionsmodell, deckt BQML ab:
- Datenhaltung
- Erstellung von Datensätzen
- Modelltraining + Hosting
- Inferenz und Bereitstellung
In Verbindung mit Tools wie Airflow oder Jenkins lassen sich diese Bausteine komfortabel verwalten und automatisieren.
Wichtig: Um Ressourcenzuteilung oder Datenzugriffe mussten wir uns dabei nicht kümmern, da der Großteil des Prozesses in einem Managed Data Warehouse abläuft, das genau das für uns übernimmt.
\\\__________________________________
Fachliche Beratung und Lektorat: Tony Braun
Lust auf mehr Beiträge? Schauen Sie in unseren Blog oder folgen Sie Gad auf Twitter.