Sviluppare e mettere in produzione modelli di machine learning di livello enterprise può essere tutt'altro che semplice. Anche con tecnologie come Google Cloud AutoML, Cloud ML Engine e altri strumenti di machine learning pronti all'uso, addestrare i modelli e portarli in produzione richiede solitamente un ampio bagaglio di competenze: programmazione Python avanzata, conoscenza di modelli complessi, SQL e tecnologie di database. In questo articolo vediamo come realizzare un sistema di previsione per auto, bici e monopattini in sharing usando strumenti davvero semplici.
BigQuery GIS aggiunge a Google BigQuery nuove funzionalità per l'acquisizione, la gestione e l'analisi di dati geospaziali. BigQuery ML consente invece di creare ed eseguire modelli di machine learning direttamente all'interno di BigQuery, usando il linguaggio SQL standard. In questo articolo vedremo come sfruttare il solo SQL per realizzare una pipeline ML completa end-to-end per un caso d'uso geospaziale e tempo-dipendente.
 Visualizzazione delle previsioni su mappa con Geo Viz
Visualizzazione delle previsioni su mappa con Geo Viz
Per ridurre il numero di auto private, la città di Tel Aviv ha lanciato un progetto di car sharing chiamato AutoTel. Gli utenti possono prenotare un'auto tramite app e pagare al minuto. Il progetto, partito nell'ottobre 2017, ha conquistato oltre 7.500 utenti, di cui più del 50% utilizza il servizio almeno una volta a settimana.
I dati più recenti mostrano una crescita costante nell'utilizzo di AutoTel. Anzi, l'utilizzo è cresciuto a tal punto da far emergere nuove criticità. Come per molti servizi di trasporto, uno dei fattori chiave del tasso di adozione è l'affidabilità: difficilmente gli utenti scelgono un mezzo poco affidabile, perché il costo di non arrivare a destinazione all'orario previsto è di norma molto elevato.
Per essere affidabile, AutoTel deve garantire un equilibrio geospaziale tra domanda e offerta: le auto devono trovarsi dove e quando servono. Un'impresa estremamente complessa, perché le auto vengono guidate e parcheggiate da clienti che non hanno alcun interesse per questo obiettivo di ottimizzazione. Nella maggior parte dei casi, la distribuzione delle auto non è correlata alla domanda: se un'auto viene parcheggiata in un quartiere periferico, ad esempio, può passare molto tempo prima che un altro utente la riporti in centro città, dove la domanda è alta. Il risultato è che spesso si formano agglomerati di auto inutilizzate nelle aree periferiche.
Grazie al machine learning, AutoTel può prevedere la disponibilità geospaziale delle auto in determinati momenti e usare queste previsioni per adattare il proprio modello di business. Potrebbe ad esempio modulare i prezzi per rendere più conveniente parcheggiare nelle zone ad alta domanda, oppure pianificare la manutenzione in modo da spostare le auto dalle aree con offerta in eccesso e domanda bassa verso quelle ad alta domanda. Anche se un modello del genere sarebbe utile ad AutoTel, svilupparlo può rivelarsi costoso e complicato. In questo articolo costruiremo e metteremo in produzione un modello che prevede il numero di auto disponibili usando esclusivamente Google BigQuery. Il codice completo della demo è disponibile in questa repository GitHub.
Parte 1: acquisizione dei dati
Dal sito di AutoTel ho estratto la posizione delle auto parcheggiate ogni due minuti per diversi mesi. I dati grezzi sono stati salvati su Google Storage in formato CSV e successivamente caricati in una tabella BigQuery. Questo breve filmato mostra una visualizzazione dei dati raccolti realizzata con kepler.gl di Uber.
https://www.youtube.com/watch?v=ys6PfEugYrw
Ho inoltre scaricato dati dal portale open data del Comune di Tel Aviv e caricato in BQ tabelle con informazioni sull'età della popolazione, le aree commerciali, la posizione di hotel e asili e i confini dei quartieri. Si presume che queste variabili abbiano una relazione lineare con il numero totale di auto disponibili: l'analisi dei dati potrà smentirci, ma partiamo da questa ipotesi.
Parte 2: join geografici e raggruppamento
Ogni riga del dataset grezzo rappresenta la posizione di un'auto parcheggiata in un determinato momento. Per aggregare i dati a livello di quartiere è stato necessario ricorrere a un'istruzione di spatial join.
Il codice qui sotto mostra come eseguire uno spatial join:
SELECT car_locs.*, ta_dis.neighbourhood_name FROM car_locs JOIN ta_dis ONST_WITHIN(ST_GEOGPOINT(car_locs.longitude, car_locs.latitude), ST_GeogFromText(ta_dis.area_polygon))
Parte 3: addestramento del modello
A dicembre 2018 BQML supporta due tipi di modelli: la regressione lineare per i task di regressione e la regressione logistica per quelli di classificazione. Addestriamo i modelli con il seguente comando SQL:
CREATE OR REPLACE MODE
L `autotel_demo.free_cars_model`--percorso di salvataggio del modello
OPTIONS
(model_type='linear_reg', ls_init_learn_rate=.015, l1_reg=0.1, l2_reg=0.1, data_split_method='seq', data_split_col='split_col', min_rel_progress=0.001, max_iterations=30),SELECT
free_cars label,-- dichiarazione della variabile target
timestamp split_col-- variabili indipendenti:
,age5to14 ...FROM
`autotel_demo.autotel_dataset` as datasetWHERE
dataset.timestamp <TIMESTAMP
'2018-10-11'Parte 4: valutazione del modello
Una volta addestrato il modello, possiamo usare la funzione "Model.Evaluate" per ottenere metriche sulle sue performance. Queste metriche sono utili in molti contesti, ma in questo caso ci troviamo davanti a un task di previsione geospaziale e vogliamo visualizzare le previsioni del modello direttamente su una mappa.
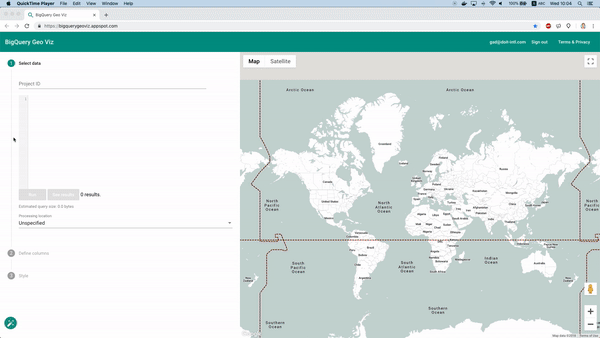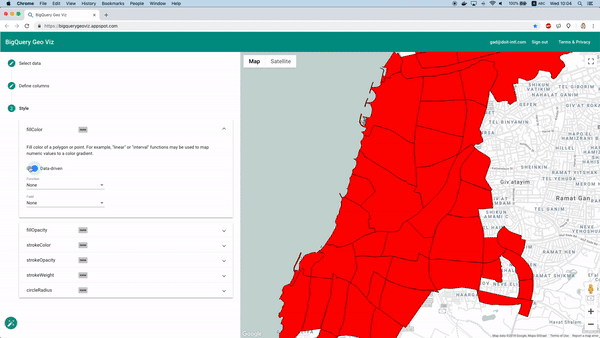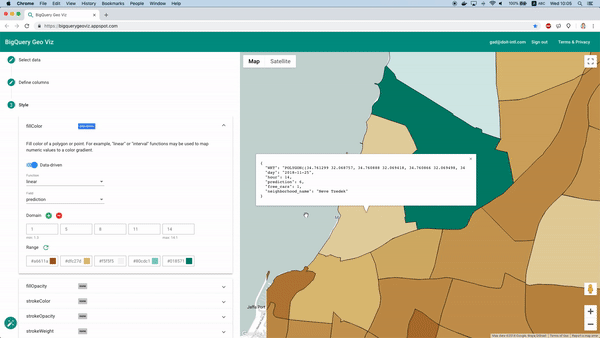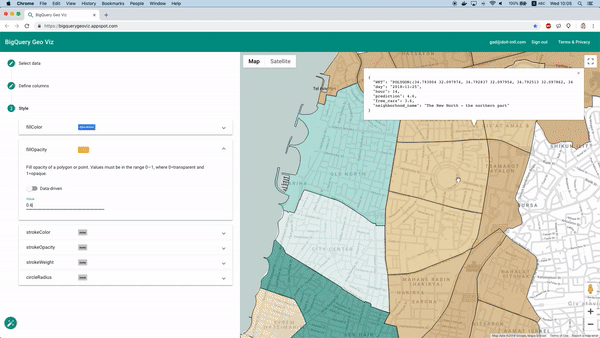
Per fortuna è possibile farlo con lo strumento BigQuery Geo Viz. Permette di mostrare su mappa i poligoni dei confini dei quartieri e di confrontare la previsione con il numero reale di auto disponibili in un dato momento. In questo modo possiamo capire come l'errore si distribuisce dal punto di vista geografico.
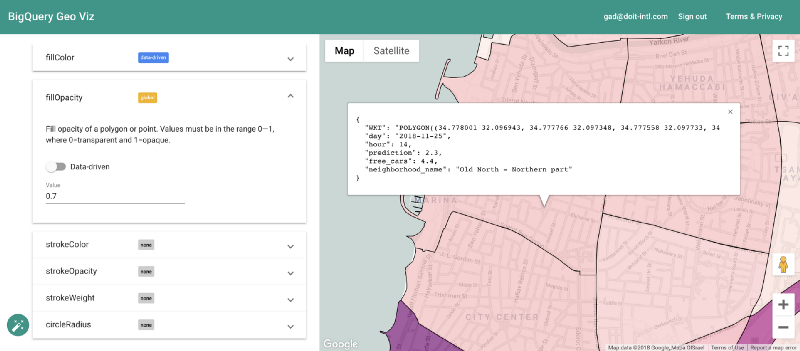 Visualizzazione delle previsioni con Geo Viz
Visualizzazione delle previsioni con Geo Viz
Parte 5 — Messa in produzione
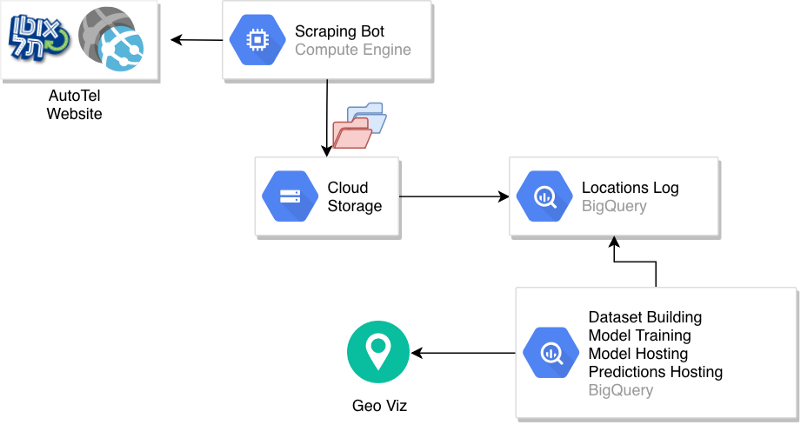
Diamo uno sguardo all'architettura complessiva che abbiamo realizzato.
Architettura della pipeline
Un bot di scraping accede al sito di AutoTel e carica un file CSV con le posizioni delle auto in un bucket partizionato su GCS.
Sui dati grezzi viene poi costruita una tabella BigQuery e si avviano manualmente la creazione del dataset e l'addestramento del modello. Una volta creato, il modello resta ospitato in BigQuery e viene usato per generare previsioni in tempo reale o per produrre una tabella di previsioni. Quest'ultima può poi essere impiegata per realizzare visualizzazioni e alimentare gli altri componenti del sistema di produzione.
L'elemento che ancora manca è l'automazione del processo. Caricare nuovi dati nella tabella delle posizioni, creare nuovi dataset, addestrare i modelli e generare previsioni sono finora tutti passaggi manuali. Un modo per automatizzarli è sfruttare il fatto che BigQuery è di fatto un servizio invocabile tramite chiamate client.
Si può scrivere un semplicissimo script Python per eseguire tutti questi passaggi e poi affidarne la gestione a Cloud Composer di Google. Cloud Composer è la scelta ideale per questo tipo di attività, dato che alcuni passaggi dipendono l'uno dall'altro; ha però bisogno di un cluster per orchestrare i task, il che può risultare piuttosto oneroso se viene usato solo per questo scopo.
Esistono anche alternative per pianificare lo script di addestramento e previsione, come Cron o Jenkins. Il punto, però, è questo: con pochi dollari al giorno Google Cloud Composer vi risparmia configurazioni e gestione dei permessi tutt'altro che banali, e più processi gli si affidano, più conveniente diventa.
In sintesi
Nell'ottica di semplificare l'integrazione dei modelli di machine learning nei sistemi di produzione, BigQuery ML offre uno strumento gestito che può fare da meccanismo end-to-end per la parte centrale della pipeline. Se basta un semplice modello di regressione lineare o logistica, scoprirete che BQML copre:
- Hosting dei dati
- Creazione del dataset
- Addestramento e hosting del modello
- Inferenza e serving
Affiancandolo a strumenti come Airflow o Jenkins, è possibile orchestrare e automatizzare l'intera catena.
Vale la pena sottolineare che in questo processo non abbiamo dovuto preoccuparci né dell'allocazione delle risorse né dell'accesso ai dati, perché abbiamo mantenuto la quasi totalità del flusso all'interno di un sistema di data warehouse gestito che se ne occupa al posto nostro.
\\\__________________________________
Consulenza tecnica ed editing: Tony Braun
Volete leggere altri articoli? Visitate il nostro blog oppure seguite Gad su Twitter.