
混合精度と単精度によるGAN学習の比較
前回の記事では、Tensor Core上で混合精度学習を行うためのTensorflowコードの書き換え方法を解説しました。本稿では、その効果を検証するために、異なるハードウェア構成のGoogle CloudのDeep Learning VM上でGenerative Adversarial Network(GAN)を学習させました。検証の結果、混合精度を用いることでクラウドでの学習コストを最大25%削減できることが分かりました。
画像出典:https://bit-media.org/tag/tensorflow-lite-machine-learning-models/
GANの基礎
GANは、2つのサブネットワークから構成される複雑なネットワークです。1つはノイズを入力として受け取り、データ(画像など)を出力するgenerator。もう1つはデータを入力として受け取り、それが生成されたものか、データセットからサンプリングされたものかの確率を出力するdiscriminatorです。本稿では、生成された出力の分類タスクも併せて行う、従来のGANモデルの拡張版であるAC-GANを使用しました。
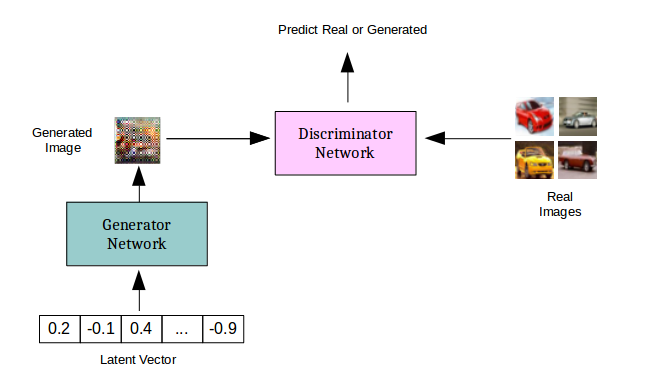
Mixed precision trainingの考え方に基づき、Nvidiaのコードを拡張しています。
パート1 — コードに混合精度を組み込む
ステップ1 — モデルをfloat16データ型に変換する。
混合精度学習でtensor coreを活用するには、負荷の高い計算でFP16を使用する必要があります。ここでは例として、generatorネットワークでFP16を使うために行ったコードの変更を示します。discriminatorとclassifierでも同様の変更を行います。
まずは、単精度を使ったgeneratorから始めます:
https://gist.github.com/eladshabi/f5abe93ef7dd2e13b3cb2144bb8274a4
generatorモデルで使うカスタムconv2Dレイヤーを作成します:
https://gist.github.com/eladshabi/b9957db1b5d4feff8d6de824af4f7bad
混合精度で学習を行うには、次の点を押さえる必要があります:
- フレームワーク内でTensor Coreパスを有効にする — テンソルや畳み込み層/全結合層にFP16フォーマットを指定します。このデータ型は、可能な場面で自動的にTensor Coreハードウェアを活用します。Tensor Coreによる高速化の機会を増やすには、線形レイヤーの行列次元や畳み込みのチャネル数を、可能な限り8の倍数に揃えてください。
- 学習可能なパラメータはFP32で保存し、カスタムgetter関数で学習時にFP16へ変換します。
- softmaxやbatch normalizationのような特定のレイヤーでは、統計量を保つためにfloat32で入力します。
これらを適用すると、generatorのコードは次のようになります:
https://gist.github.com/eladshabi/325aa0a4007343776221bb070b4d962f
ステップ2 — Loss scaling。
混合精度での勾配計算では勾配消失が起こり得ます。これを防ぐため、次の手順を行います:
- 損失にスケール係数を掛ける。
- スケーリングした損失で勾配を計算する。
- 勾配をスケール係数で割る。
- あとは通常どおり最適化を進める。
これで、次のように混合精度学習を実行できます:
training_step_op_D/G/Q.パート2 — 結果の分析
GANの結果
GANの効果を確認するため、V100 GPU・バッチサイズ1024でQuick-drawデータセットを7分間学習させました。結果は明白で、単精度ではノイズしか生成できなかったのに対し、混合精度モードでは鮮明で良好な画像が生成されました。

 図4:7分間学習後の結果。左 — 混合精度、右 — 単精度。クラスは左から順に:Airplane、Apple、Bee、Bird、Book、Clock、Cow、Dog、Eye、Fish。
図4:7分間学習後の結果。左 — 混合精度、右 — 単精度。クラスは左から順に:Airplane、Apple、Bee、Bird、Book、Clock、Cow、Dog、Eye、Fish。
学習速度とコストの分析
以下の結果は、CIFAR-10データセットから画像を生成する際に、V100・T4・P100の各GPUで取得したものです。
- 小さなバッチサイズで混合精度を使った場合 — 混合精度と単精度の差はわずかでした。むしろ変数キャストのオーバーヘッドにより、学習がわずかに遅くなることもありました。
- 大きなバッチサイズで混合精度を使った場合 — tensor core搭載GPUでは、バッチサイズを大きくすることで、1バッチあたりの平均処理時間が15〜40%短縮されました。最大の効果が見られたのはT4で、2048サンプルのバッチで単精度では約700msかかっていた処理が、混合精度では約410msに短縮されました。
tensor coreの強みは、大規模な計算(読み込みと処理)を連続的にこなせる点にあります。バッチサイズが小さいと読み込みの頻度が増えて処理時間は短くなりますが、バッチサイズが大きくなるとその逆になります。図1でその違いが確認できます。tensor coreを搭載しないP100で学習した場合は学習時間に短縮が見られず、Tensor Coreが実際に活用されていることが裏付けられました。
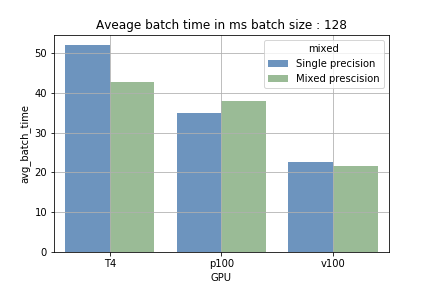
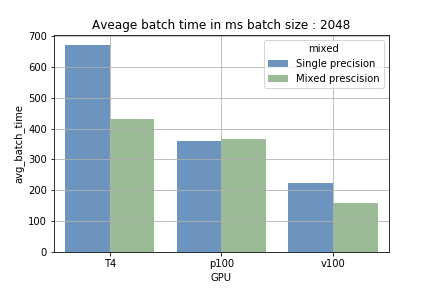 図1:1バッチあたりの平均実行時間の比較。
図1:1バッチあたりの平均実行時間の比較。
tensor coreでコストを削減
これらの結果は学習コストに換算できます。たとえば、混合精度モデルで1000サンプルをさまざまなバッチサイズで実行すると、単精度よりも所要時間が短くなります(図2)。100万バッチを学習させた場合の費用を計算すると、たとえばT4 GPUでバッチサイズ2048の混合精度を使えば、コストは178ドルから118ドルに下がります(100万サンプルあたり60ドルの節約)(図3)。
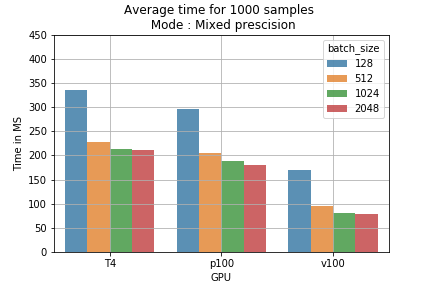
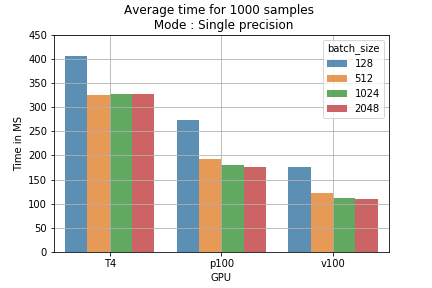 図2:バッチサイズと学習モード別の1000サンプルあたり平均学習時間。
図2:バッチサイズと学習モード別の1000サンプルあたり平均学習時間。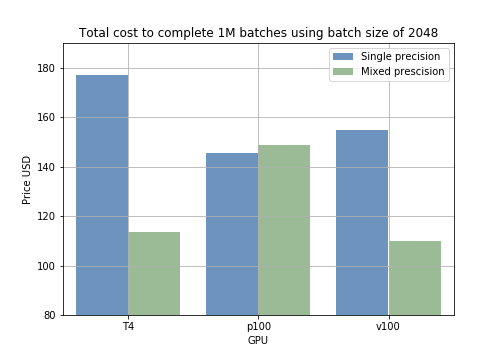 図3:100万バッチ学習時の、学習モード別の費用比較。
図3:100万バッチ学習時の、学習モード別の費用比較。
まとめ
AIモデルが複雑化し、より高度なアプリケーションが普及するにつれて、現実的な学習を実現するための工夫が一層求められます。Tensor Coreの技術は、AI学習において間違いなくゲームチェンジャーです。ただし、その真価が発揮されるのは、大規模ネットワーク・大きなバッチサイズで混合精度を使う場合です。