
Entrenamiento de GANs con precisión mixta vs. precisión simple
En el post anterior explicamos cómo modificar código de Tensorflow para entrenar con precisión mixta sobre Tensor Cores. Para medir los beneficios de este enfoque, entrenamos una Red Generativa Adversaria (GAN) en las Deep Learning VMs de Google Cloud sobre distintos tipos de hardware. Comprobamos que con precisión mixta se ahorra hasta un 25 % del costo de entrenamiento en la nube.
imagen tomada de https://bit-media.org/tag/tensorflow-lite-machine-learning-models/
Un poco sobre las GANs
Las GANs son redes complejas formadas por dos sub-redes: un generador, que recibe ruido como entrada y produce datos (por ejemplo, imágenes), y un discriminador, que recibe esos datos y devuelve la probabilidad de que provengan del generador o del dataset. En este ejemplo usamos una extensión del modelo clásico, llamada AC-GAN, que además clasifica la salida generada.
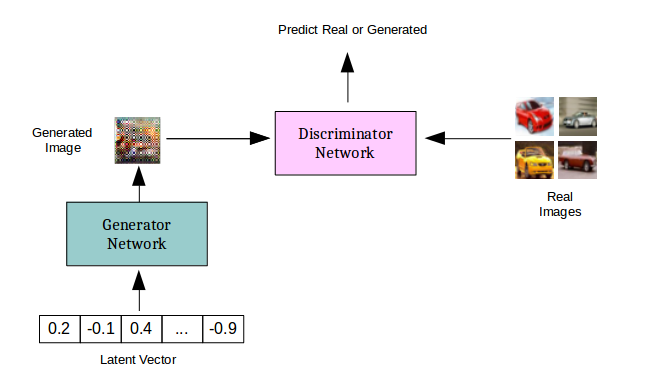
Extendimos el código de Nvidia apoyándonos en los principios de Mixed precision training.
Parte 1 — uso de precisión mixta en el código
Paso 1: convertir el modelo para que use el tipo de dato float16.
Para aprovechar los tensor-cores durante el entrenamiento con precisión mixta, el código debe usar FP16 en los cálculos pesados. A modo de ejemplo, mostramos los cambios aplicados a la red generadora para usar FP16. Los cambios en el discriminador y en el clasificador son similares a los del generador.
Partimos de un generador con precisión simple:
https://gist.github.com/eladshabi/f5abe93ef7dd2e13b3cb2144bb8274a4
Creamos una capa conv2D personalizada para el modelo del generador:
https://gist.github.com/eladshabi/b9957db1b5d4feff8d6de824af4f7bad
Para entrenar con precisión mixta hay que asegurar lo siguiente:
- Habilitar la ruta de Tensor Core en el framework: elegir el formato FP16 para los tensores y/o las capas convolucionales/fully-connected. Este tipo de dato aprovecha automáticamente el hardware de Tensor Core siempre que es posible. Dicho de otra forma, para maximizar las posibilidades de aceleración por Tensor Core, conviene elegir, cuando se pueda, dimensiones de matrices de capas lineales y conteos de canales convolucionales que sean múltiplos de ocho.
- Guardar los parámetros entrenables en FP32 y usar una función getter personalizada que los convierta a FP16 durante el entrenamiento.
- En partes específicas como las capas softmax y batch normalization, alimentamos las capas con float32 para preservar las estadísticas.
Tras aplicar estos principios, el código del generador queda así:
https://gist.github.com/eladshabi/325aa0a4007343776221bb070b4d962f
Paso 2: escalado de la pérdida (loss scaling).
El cálculo del gradiente en precisión mixta puede dar lugar a gradientes que se desvanecen. Para evitarlo, hacemos lo siguiente:
- Multiplicar la pérdida por un factor de escala.
- Calcular el gradiente con la pérdida escalada.
- Dividir los gradientes por el factor de escala.
- Continuar con la etapa de optimización de manera habitual.
Ya podemos ejecutar el entrenamiento con precisión mixta usando:
training_step_op_D/G/Q.Parte 2 — análisis de los resultados
Resultados de la GAN
Para evaluar los resultados de la GAN, la entrené con el dataset Quick-draw durante 7 minutos en una GPU V100 con un batch size de 1024. Los resultados son contundentes: mientras que con precisión simple solo se generaba ruido, el modo de precisión mixta produjo imágenes nítidas y bien definidas.

 Fig 4: a la izquierda, precisión mixta; a la derecha, precisión simple, tras 7 minutos de entrenamiento. Clases de izquierda a derecha: avión, manzana, abeja, pájaro, libro, reloj, vaca, perro, ojo, pez.
Fig 4: a la izquierda, precisión mixta; a la derecha, precisión simple, tras 7 minutos de entrenamiento. Clases de izquierda a derecha: avión, manzana, abeja, pájaro, libro, reloj, vaca, perro, ojo, pez.
Análisis de velocidad y costo de entrenamiento
Los siguientes resultados se obtuvieron en GPUs V100, T4 y P100, generando imágenes a partir del dataset CIFAR-10.
- Precisión mixta con batch size pequeño: la diferencia frente a la precisión simple fue insignificante. Es más, la sobrecarga del casteo de variables incluso ralentizó un poco el entrenamiento.
- Precisión mixta con batch size mayor: en GPUs con tensor cores, aumentar el batch size redujo el tiempo promedio por batch entre un 15 % y un 40 %. La mayor ganancia se dio en la T4: con precisión simple tomaba unos 700 ms por batch de 2048 muestras, y con precisión mixta el tiempo bajó a unos 410 ms.
La ventaja de los tensor cores proviene de su capacidad para encadenar cálculos masivos de forma secuencial (carga y procesamiento). Con un batch size pequeño la carga ocurre más a menudo y el procesamiento dura menos; con batch sizes grandes pasa lo contrario. La fig 1 muestra la diferencia. Al entrenar en la P100, que no tiene tensor cores, no se observó ninguna reducción en el tiempo de entrenamiento (lo que confirma que estamos aprovechando los Tensor Cores).
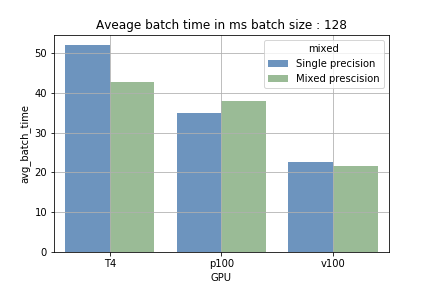
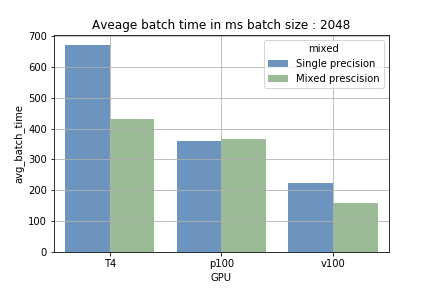 Fig 1: comparación del tiempo promedio para ejecutar un batch.
Fig 1: comparación del tiempo promedio para ejecutar un batch.
Los tensor cores pueden ahorrarte dinero
Los resultados se traducen directamente en costo de entrenamiento. Por ejemplo, ejecutar 1000 muestras con distintos batch sizes en el modelo con precisión mixta toma menos tiempo que con precisión simple (fig 2). Si calculamos el precio de entrenar 1 millón de batches, vemos que usar precisión mixta con un batch size de 2048 en una GPU T4 baja el costo de 178 USD a 118 USD (un ahorro de 60 USD por cada 1 M de muestras) (fig 3).
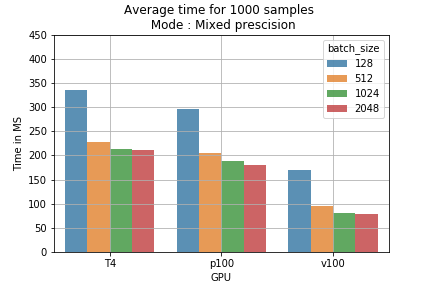
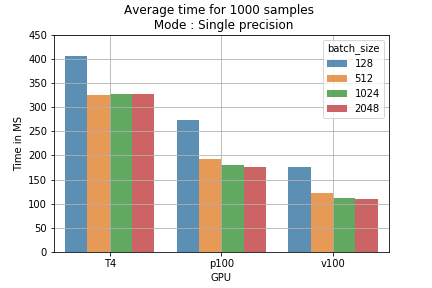 Fig 2: tiempo promedio de entrenamiento para 1000 muestras, según el batch size y el modo de entrenamiento.
Fig 2: tiempo promedio de entrenamiento para 1000 muestras, según el batch size y el modo de entrenamiento.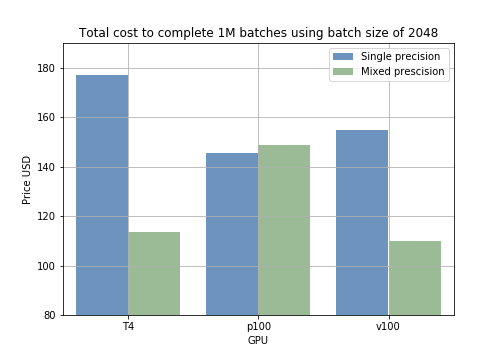 Fig 3: comparación de precios entre modos de entrenamiento para 1 M de batches.
Fig 3: comparación de precios entre modos de entrenamiento para 1 M de batches.
Conclusiones
A medida que los modelos de IA se vuelven más complejos y se despliegan aplicaciones más inteligentes, hará falta mucho ingenio humano para que el entrenamiento siga siendo viable. La tecnología de Tensor Cores marca un antes y un después en el entrenamiento de IA. Eso sí, su mayor beneficio se nota al usar precisión mixta en redes grandes con batch sizes grandes.