
GAN-Training mit Mixed Precision im Vergleich zu Single Precision
Im vorherigen Beitrag haben wir gezeigt, wie sich Tensorflow-Code anpassen lässt, um Mixed-Precision-Training auf Tensor Cores auszuführen. Um die Vorteile dieses Ansatzes zu prüfen, haben wir ein Generative Adversarial Network (GAN) auf Deep Learning VMs von Google Cloud mit unterschiedlicher Hardware trainiert. Das Ergebnis: Mit Mixed Precision lassen sich bis zu 25 % der Trainingskosten in der Cloud einsparen.
Bild von https://bit-media.org/tag/tensorflow-lite-machine-learning-models/
Kurz zu GANs
GANs sind komplexe Netze aus zwei Teilnetzen: einem Generator, der Rauschen als Eingabe erhält und Daten (etwa Bilder) ausgibt, und einem Diskriminator, der Daten als Eingabe bekommt und als Ausgabe eine Wahrscheinlichkeit liefert, ob diese Daten generiert oder dem Datensatz entnommen wurden. In diesem Beispiel haben wir eine Erweiterung des klassischen GAN-Modells namens AC-GAN eingesetzt, die zusätzlich die generierten Ausgaben klassifiziert.
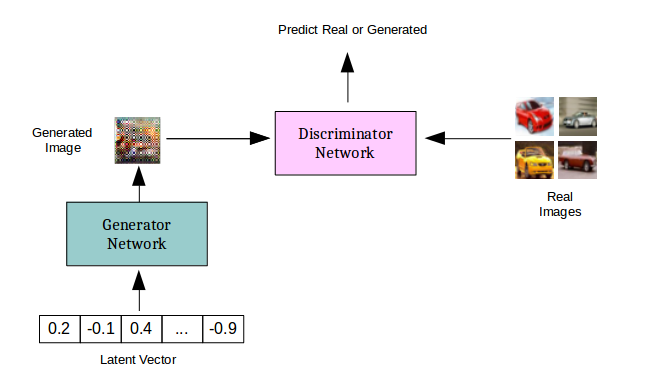
Wir haben den Code von Nvidia erweitert und uns dabei an den Prinzipien aus Mixed precision training orientiert.
Teil 1 — Mixed Precision im Code einsetzen
Schritt 1 – Modell auf den Datentyp float16 umstellen.
Damit Tensor Cores beim Mixed-Precision-Training überhaupt greifen, muss der Code FP16 für die rechenintensiven Operationen verwenden. Als Beispiel zeigen wir die Codeanpassungen am Generator-Netz für FP16. Beim Diskriminator und Klassifikator sind die Änderungen analog.
Wir starten mit einem Generator, der Single Precision nutzt:
https://gist.github.com/eladshabi/f5abe93ef7dd2e13b3cb2144bb8274a4
Anschließend bauen wir einen eigenen conv2D-Layer für das Generator-Modell:
https://gist.github.com/eladshabi/b9957db1b5d4feff8d6de824af4f7bad
Für das Training mit Mixed Precision sind folgende Punkte entscheidend:
- Den Tensor-Core-Pfad im Framework aktivieren – also FP16 für Tensoren und/oder Convolution-/Fully-Connected-Layer wählen. Dieser Datentyp nutzt die Tensor-Core-Hardware automatisch, sobald es möglich ist. Um die Chancen auf Tensor-Core-Beschleunigung zu maximieren, sollten Matrixdimensionen linearer Layer und die Anzahl der Convolution-Kanäle nach Möglichkeit Vielfache von acht sein.
- Trainierbare Parameter in FP32 ablegen und über eine eigene Getter-Funktion fürs Training nach FP16 konvertieren.
- Bei bestimmten Komponenten wie Softmax- und Batch-Normalization-Layern verwenden wir float32 als Eingabe, damit die Statistiken erhalten bleiben.
Mit diesen Anpassungen sieht der Generator-Code so aus:
https://gist.github.com/eladshabi/325aa0a4007343776221bb070b4d962f
Schritt 2 – Loss Scaling.
Die Gradientenberechnung in Mixed Precision kann zu verschwindenden Gradienten führen. Um das zu verhindern, gehen wir wie folgt vor:
- Den Loss mit einem Skalierungsfaktor multiplizieren.
- Den Gradienten anhand des skalierten Loss berechnen.
- Die Gradienten durch den Skalierungsfaktor teilen.
- Die Optimierung wie gewohnt fortsetzen.
Jetzt lässt sich das Mixed-Precision-Training starten mit:
training_step_op_D/G/Q.Teil 2 — Ergebnisse im Detail
GAN-Ergebnisse
Um die GAN-Ergebnisse zu prüfen, habe ich das GAN sieben Minuten lang auf dem Quick-Draw-Datensatz trainiert – mit V100-GPU und Batchgröße 1024. Der Unterschied war eindeutig: Während Single Precision nur Rauschen produzierte, lieferte der Mixed-Precision-Modus klare, überzeugende Ergebnisse.

 Abb. 4: links — Mixed Precision, rechts — Single Precision, nach sieben Minuten Training. Klassen von links nach rechts: Flugzeug, Apfel, Biene, Vogel, Buch, Uhr, Kuh, Hund, Auge, Fisch.
Abb. 4: links — Mixed Precision, rechts — Single Precision, nach sieben Minuten Training. Klassen von links nach rechts: Flugzeug, Apfel, Biene, Vogel, Buch, Uhr, Kuh, Hund, Auge, Fisch.
Trainingsgeschwindigkeit und Kosten im Vergleich
Die folgenden Ergebnisse stammen aus Läufen mit V100-, T4- und P100-GPUs, bei denen Bilder aus dem CIFAR-10-Datensatz generiert wurden.
- Mixed Precision mit kleiner Batchgröße: Der Unterschied zwischen Mixed Precision und Single Precision fiel kaum ins Gewicht. Der Overhead durch das Casten der Variablen bremste das Training sogar leicht aus.
- Mixed Precision mit größerer Batchgröße: Bei GPUs mit Tensor Cores senkt eine größere Batchgröße die durchschnittliche Zeit pro Batch um 15–40 %. Den größten Sprung brachte die T4: Single Precision benötigte rund 700 ms pro Batch mit 2048 Samples – mit Mixed Precision waren es nur noch etwa 410 ms.
Der Vorteil der Tensor Cores beruht darauf, dass sie umfangreiche Berechnungen sequenziell ausführen (Laden und Verarbeiten). Bei kleiner Batchgröße fällt der Ladeanteil häufiger an, die Verarbeitungszeit ist kürzer – bei größerer Batchgröße ist es umgekehrt. Abb. 1 macht den Unterschied sichtbar. Beim Training auf der P100, die keine Tensor Cores besitzt, war keine Verkürzung der Trainingszeit messbar – ein Beleg dafür, dass tatsächlich die Tensor Cores zum Einsatz kommen.
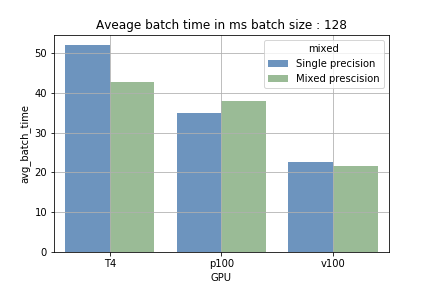
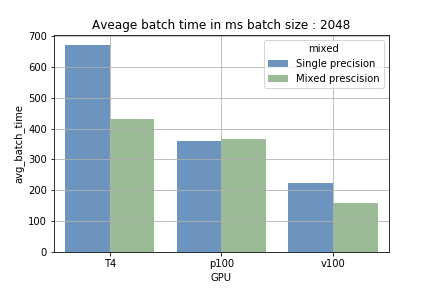 Abb. 1: Vergleich der durchschnittlichen Zeit pro Batch.
Abb. 1: Vergleich der durchschnittlichen Zeit pro Batch.
Tensor Cores sparen bares Geld
Die Ergebnisse lassen sich direkt in Trainingskosten umrechnen. Das Training von 1000 Samples mit unterschiedlichen Batchgrößen läuft im Mixed-Precision-Modell schneller als mit Single Precision (Abb. 2). Rechnet man den Preis für das Training von einer Million Batches durch, zeigt sich beispielsweise: Mit Batchgröße 2048 auf einer T4-GPU senkt Mixed Precision die Kosten von 178 $ auf 118 $ – also 60 $ Ersparnis pro 1 Mio. Samples (Abb. 3).
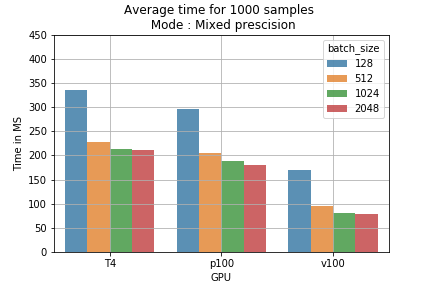
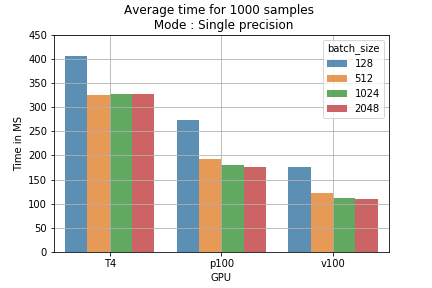 Abb. 2: Durchschnittliche Trainingszeit für 1000 Samples je Batchgröße und Trainingsmodus.
Abb. 2: Durchschnittliche Trainingszeit für 1000 Samples je Batchgröße und Trainingsmodus.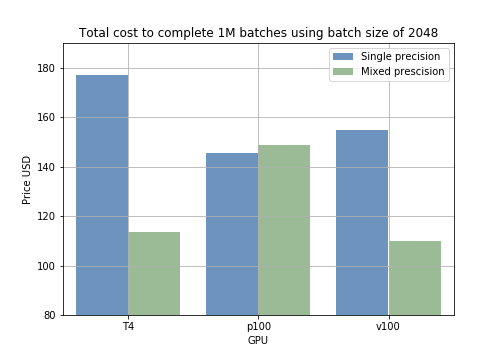 Abb. 3: Vergleich der Trainingskosten je Modus für 1 Mio. Batches.
Abb. 3: Vergleich der Trainingskosten je Modus für 1 Mio. Batches.
Fazit
Je komplexer KI-Modelle und je smarter die darauf aufbauenden Anwendungen werden, desto mehr Hirnschmalz fließt in die Frage, wie sich das Training überhaupt noch praktikabel halten lässt. Die Tensor-Core-Technologie ist im KI-Training zweifellos ein Gamechanger. Ihren vollen Vorteil spielt sie aber erst aus, wenn Mixed Precision auf großen Netzen mit großen Batchgrößen läuft.