
Training di GAN: mixed precision a confronto con la single precision
Nel post precedente abbiamo descritto come modificare il codice Tensorflow per eseguire il training in mixed precision sui Tensor Cores. Per valutare i vantaggi di questo approccio, abbiamo addestrato una Generative Adversarial Network (GAN) sulle Deep Learning VM di Google Cloud, su hardware diversi. Il risultato: con la mixed precision si può risparmiare fino al 25% dei costi di training sul cloud.
immagine da https://bit-media.org/tag/tensorflow-lite-machine-learning-models/
Qualche cenno sulle GAN
Le GAN sono reti complesse formate da due sotto-reti: un generatore, che riceve in input del rumore e produce in output un dato (ad esempio un'immagine), e un discriminatore, che riceve dati in input e restituisce la probabilità che siano generati o campionati dal dataset. In questo esempio abbiamo utilizzato un'estensione del classico modello GAN, l'AC-GAN, che svolge l'ulteriore compito di classificare l'output generato.
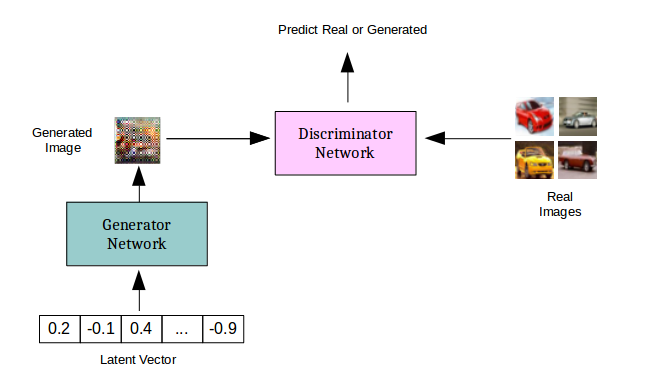
Abbiamo esteso il codice di Nvidia partendo dai principi del Mixed precision training.
Parte 1 — usare la mixed precision nel codice
Step 1 - convertire il modello al tipo di dato float16.
Per sfruttare i tensor-cores durante il training in mixed precision, il codice deve usare FP16 per i calcoli più onerosi. A titolo di esempio, mostriamo le modifiche apportate al codice della rete generatore per passare a FP16. Le modifiche al discriminatore e al classificatore sono analoghe.
Partiamo da un generatore in single precision:
https://gist.github.com/eladshabi/f5abe93ef7dd2e13b3cb2144bb8274a4
Creiamo un layer conv2D personalizzato da usare nel modello generatore:
https://gist.github.com/eladshabi/b9957db1b5d4feff8d6de824af4f7bad
Per addestrare in mixed precision occorre garantire quanto segue:
- Abilitare il percorso Tensor Core nel framework, scegliendo il formato FP16 per i tensori e/o per i layer convoluzionali e fully-connected. Questo tipo di dato sfrutta automaticamente l'hardware Tensor Core ogni volta che è possibile; in altre parole, per massimizzare le probabilità di accelerazione tramite Tensor Core conviene scegliere, dove possibile, dimensioni delle matrici dei layer lineari e numero di canali di convoluzione multipli di otto.
- Salvare i parametri addestrabili in FP32 e usare una funzione getter personalizzata per convertirli in FP16 durante il training.
- Per parti specifiche come i layer softmax e batch normalization, alimentiamo i layer in float32 per preservare le statistiche.
Applicando questi principi, il codice del generatore diventa:
https://gist.github.com/eladshabi/325aa0a4007343776221bb070b4d962f
Step 2 - loss scaling.
Il calcolo dei gradienti in mixed precision può causare il fenomeno dei vanishing gradients; per evitarlo procediamo così:
- Moltiplichiamo la loss per un fattore di scala.
- Calcoliamo il gradiente sulla loss scalata.
- Dividiamo i gradienti per lo stesso fattore di scala.
- Proseguiamo con la fase di ottimizzazione come di consueto.
A questo punto possiamo eseguire il training in mixed precision con:
training_step_op_D/G/Q.Parte 2 — analisi dei risultati
Risultati della GAN
Per valutare i risultati della GAN, l'ho addestrata sul dataset Quick-draw per 7 minuti, su GPU V100 e con batch size di 1024. I risultati parlano da soli: mentre la single precision riusciva a produrre soltanto rumore, la modalità mixed precision ha generato risultati nitidi e di buona qualità.

 Fig. 4: a sinistra — mixed precision, a destra — single precision, dopo 7 minuti di training. Classi da sinistra a destra: Airplane, Apple, Bee, Bird, Book, Clock, Cow, Dog, Eye, Fish.
Fig. 4: a sinistra — mixed precision, a destra — single precision, dopo 7 minuti di training. Classi da sinistra a destra: Airplane, Apple, Bee, Bird, Book, Clock, Cow, Dog, Eye, Fish.
Analisi di velocità di training e costi
I risultati seguenti sono stati ottenuti su GPU V100, T4 e P100 per generare immagini dal dataset CIFAR-10.
- Mixed precision con batch size ridotta: la differenza tra training in mixed precision e single precision è risultata trascurabile. Anzi, l'overhead del cast delle variabili ha addirittura rallentato leggermente il training.
- Mixed precision con batch size più ampia: sulle GPU dotate di tensor cores, aumentare la batch size riduce il tempo medio per completare il batch del 15-40%. Il guadagno maggiore si è registrato sulla T4: la single precision impiegava circa 700 ms per un batch da 2048 campioni, mentre con la mixed precision il tempo è sceso a circa 410 ms.
Il vantaggio dei tensor cores nasce dalla capacità di eseguire calcoli massicci in modo sequenziale (caricamento ed elaborazione). Con una batch size ridotta la fase di caricamento è più frequente e quella di elaborazione più breve; con batch size ampie accade il contrario. La fig. 1 lo mostra chiaramente. Sulla P100, che non dispone di tensor cores, non si è osservata alcuna riduzione del tempo di training (a conferma del fatto che stiamo davvero sfruttando i Tensor Cores).
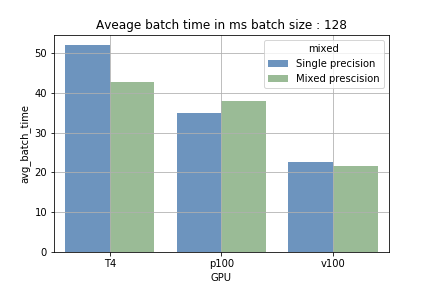
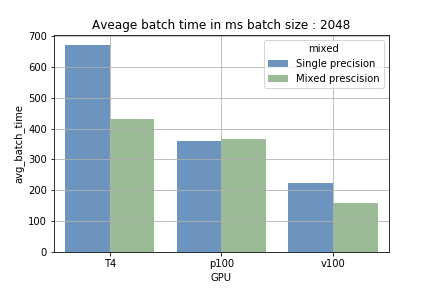 Fig. 1: confronto del tempo medio per eseguire un batch.
Fig. 1: confronto del tempo medio per eseguire un batch.
I tensor cores fanno risparmiare
Questi risultati si traducono direttamente in costi di training. Ad esempio, eseguire 1000 campioni con diverse batch size usando il modello in mixed precision richiede meno tempo rispetto alla single precision (fig. 2). Calcolando il prezzo del training per 1 milione di batch, si vede ad esempio che la mixed precision con batch size di 2048 su GPU T4 abbatte il costo da 178$ a 118$ (60$ risparmiati per 1M di campioni) (fig. 3).
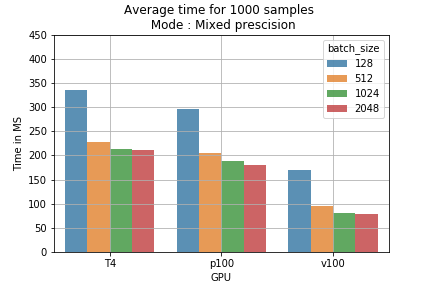
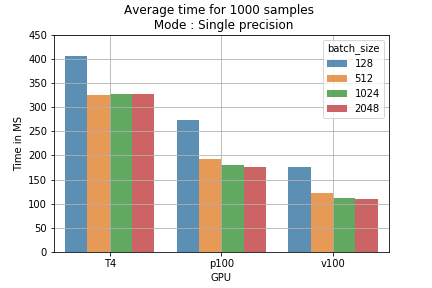 Fig. 2: tempo medio di training per 1000 campioni, per batch size e modalità di training.
Fig. 2: tempo medio di training per 1000 campioni, per batch size e modalità di training.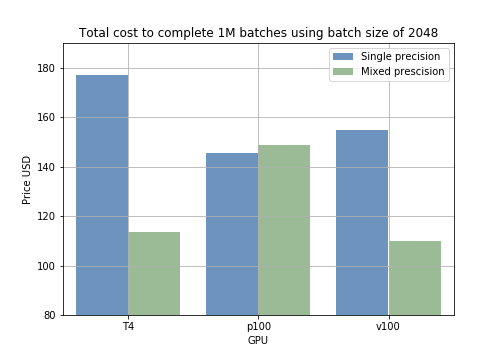 Fig. 3: confronto dei prezzi delle modalità di training su 1M di batch.
Fig. 3: confronto dei prezzi delle modalità di training su 1M di batch.
Conclusioni
Con modelli AI sempre più complessi e applicazioni sempre più sofisticate, la mente umana dovrà lavorare sodo per rendere il training sostenibile. La tecnologia dei Tensor Cores rappresenta senza dubbio una svolta nel training AI. Tuttavia, i Tensor Cores danno il massimo quando si utilizza la mixed precision su reti di grandi dimensioni e con batch size ampie.