
Entraîner des GAN en précision mixte plutôt qu'en précision simple
Dans l'article précédent, nous avons expliqué comment adapter du code Tensorflow pour réaliser un entraînement en précision mixte sur Tensor Cores. Pour mesurer les bénéfices de cette approche, nous avons entraîné un Generative Adversarial Network (GAN) sur les Deep Learning VMs de Google Cloud avec différentes configurations matérielles. Résultat : la précision mixte permet de réduire jusqu'à 25 % le coût d'entraînement dans le cloud.
image issue de https://bit-media.org/tag/tensorflow-lite-machine-learning-models/
Quelques mots sur les GAN
Les GAN sont des réseaux complexes constitués de deux sous-réseaux : un générateur, qui reçoit en entrée un bruit et produit une donnée (par exemple une image), et un discriminateur, qui reçoit une donnée en entrée et renvoie une probabilité indiquant si elle a été générée ou échantillonnée depuis le jeu de données. Dans cet exemple, nous avons utilisé une extension du modèle GAN classique appelée AC-GAN, qui ajoute une tâche de classification de la sortie générée.
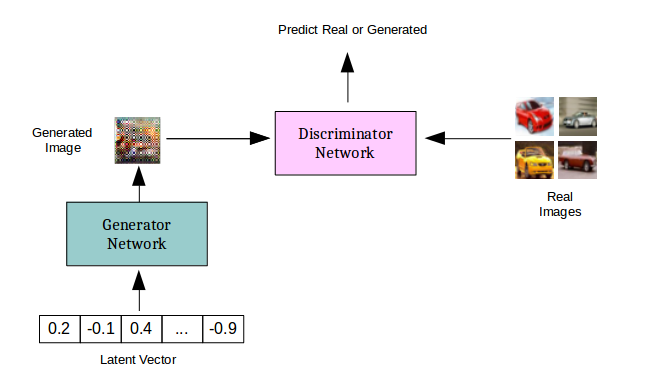
Nous avons étendu le code de Nvidia en nous appuyant sur les principes du Mixed precision training.
Partie 1 — utiliser la précision mixte dans le code
Étape 1 — convertir le modèle pour utiliser le type de données float16.
Pour exploiter les Tensor Cores pendant l'entraînement en précision mixte, le code doit recourir au format FP16 pour les calculs lourds. Nous présentons ici les modifications apportées au réseau générateur pour passer en FP16. Celles du discriminateur et du classifieur sont similaires.
Nous partons d'un générateur en précision simple :
https://gist.github.com/eladshabi/f5abe93ef7dd2e13b3cb2144bb8274a4
Nous créons une couche conv2D personnalisée utilisée dans le modèle générateur :
https://gist.github.com/eladshabi/b9957db1b5d4feff8d6de824af4f7bad
Pour entraîner en précision mixte, il faut respecter les points suivants :
- Activer le chemin Tensor Core dans le framework — choisir le format FP16 pour les tenseurs et/ou les couches de convolution / entièrement connectées. Ce type de données tire automatiquement parti du matériel Tensor Core dès que possible. Pour maximiser les chances d'accélération via Tensor Core, privilégiez des dimensions de matrices de couches linéaires et un nombre de canaux de convolution multiples de huit.
- Conserver les paramètres entraînables en FP32, et utiliser une fonction getter personnalisée pour les convertir en FP16 lors de l'entraînement.
- Pour certaines parties spécifiques comme les couches softmax et batch normalization, on alimente les couches en float32 afin de préserver les statistiques.
Une fois ces principes appliqués, le code du générateur ressemble à ceci :
https://gist.github.com/eladshabi/325aa0a4007343776221bb070b4d962f
Étape 2 — Mise à l'échelle de la perte (loss scaling).
Le calcul du gradient en précision mixte peut produire des gradients qui s'évanouissent. Pour éviter ce problème, on procède ainsi :
- Multiplier la perte par un facteur d'échelle.
- Calculer le gradient à partir de la perte mise à l'échelle.
- Diviser les gradients par ce même facteur d'échelle.
- Poursuivre la phase d'optimisation comme d'habitude.
Il ne reste plus qu'à lancer l'entraînement en précision mixte avec :
training_step_op_D/G/Q.Partie 2 — analyse des résultats
Résultats du GAN
Pour évaluer les résultats du GAN, je l'ai entraîné sur le jeu de données Quick-draw pendant 7 minutes, sur GPU V100, avec une taille de batch de 1024. Le verdict est sans appel : la précision simple ne produit que du bruit, tandis que le mode précision mixte génère des résultats nets et de bonne qualité.

 Fig 4 : à gauche — précision mixte, à droite — précision simple, après 7 minutes d'entraînement. Classes de gauche à droite : avion, pomme, abeille, oiseau, livre, horloge, vache, chien, œil, poisson.
Fig 4 : à gauche — précision mixte, à droite — précision simple, après 7 minutes d'entraînement. Classes de gauche à droite : avion, pomme, abeille, oiseau, livre, horloge, vache, chien, œil, poisson.
Analyse de la vitesse et du coût d'entraînement
Les résultats suivants ont été obtenus avec des GPU V100, T4 et P100, sur la génération d'images à partir du jeu de données CIFAR-10.
- Précision mixte avec un batch de petite taille — l'écart entre précision mixte et précision simple est négligeable. Pire, le surcoût de conversion des variables ralentit même légèrement l'entraînement.
- Précision mixte avec un batch de grande taille — sur les GPU équipés de Tensor Cores, augmenter la taille de batch réduit le temps moyen de traitement d'un batch de 15 à 40 %. Le gain le plus marqué a été obtenu sur T4 : la précision simple prenait environ 700 ms par batch de 2048 échantillons, contre environ 410 ms en précision mixte.
L'atout des Tensor Cores tient à leur capacité d'enchaîner des calculs massifs de manière séquentielle (chargement et traitement). Avec un petit batch, la phase de chargement revient plus souvent et le temps de traitement est plus court ; c'est l'inverse avec un batch plus grand. La figure 1 illustre cet écart. Sur P100, qui ne dispose d'aucun Tensor Core, aucune réduction du temps d'entraînement n'a été constatée — ce qui confirme que les Tensor Cores sont bien sollicités sur les autres GPU.
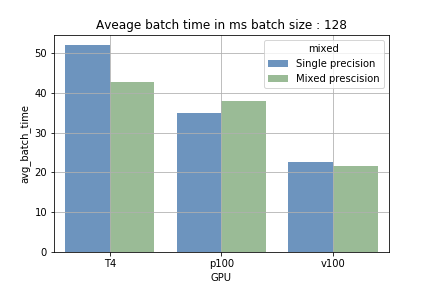
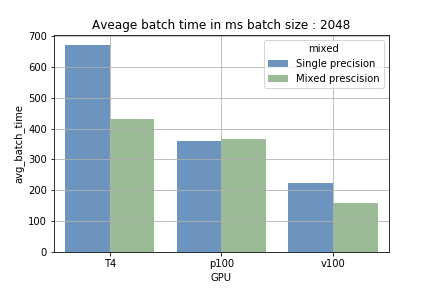 Fig 1 : comparaison du temps moyen d'exécution d'un batch.
Fig 1 : comparaison du temps moyen d'exécution d'un batch.
Les Tensor Cores font baisser la facture
Ces résultats se traduisent directement en coût d'entraînement. Par exemple, traiter 1000 échantillons avec différentes tailles de batch prend moins de temps en précision mixte qu'en précision simple (fig 2). En projetant le prix d'un entraînement sur 1 million de batches, on constate qu'avec une taille de batch de 2048 sur GPU T4, la précision mixte fait passer le coût de 178 $ à 118 $, soit 60 $ d'économie par million d'échantillons (fig 3).
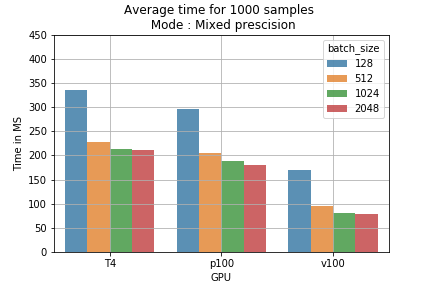
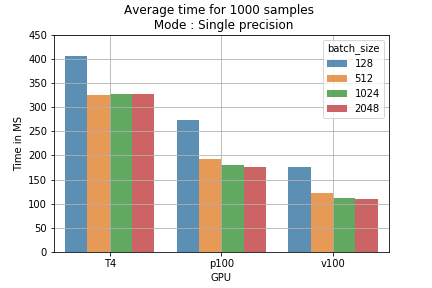 Fig 2 : temps d'entraînement moyen pour 1000 échantillons, selon la taille de batch et le mode d'entraînement.
Fig 2 : temps d'entraînement moyen pour 1000 échantillons, selon la taille de batch et le mode d'entraînement.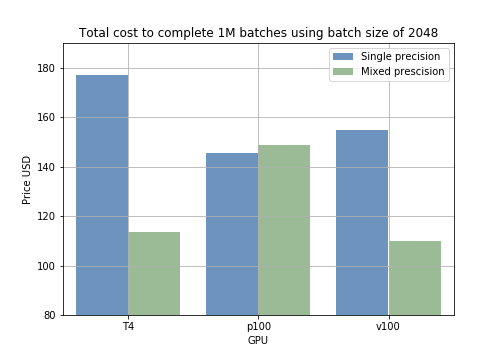 Fig 3 : comparaison des coûts par mode d'entraînement pour 1M de batches.
Fig 3 : comparaison des coûts par mode d'entraînement pour 1M de batches.
Conclusions
À mesure que les modèles d'IA gagnent en complexité et que des applications toujours plus intelligentes voient le jour, l'enjeu sera de rendre leur entraînement réalisable. La technologie Tensor Cores change clairement la donne pour l'entraînement IA. Elle exprime toutefois tout son potentiel en précision mixte, sur de grands réseaux entraînés avec une taille de batch importante.