
Treinando GANs com precisão mista vs. precisão simples
No post anterior, mostramos como adaptar o código em Tensorflow para fazer treinamento com precisão mista nos Tensor Cores. Para avaliar os ganhos desse método, treinamos uma Generative Adversarial Network (GAN) nas Deep Learning VMs do Google Cloud em diferentes hardwares. Descobrimos que a precisão mista pode economizar até 25% do custo de treinamento na nuvem.
imagem de https://bit-media.org/tag/tensorflow-lite-machine-learning-models/
Um pouco sobre GANs
GANs são redes complexas formadas por duas sub-redes: um gerador, que recebe ruído como entrada e devolve dados (como imagens), e um discriminador, que recebe os dados como entrada e calcula a probabilidade de eles terem sido gerados ou amostrados do dataset. Neste exemplo, usamos uma extensão do modelo GAN clássico chamada AC-GAN, que cumpre a tarefa adicional de classificar a saída gerada.
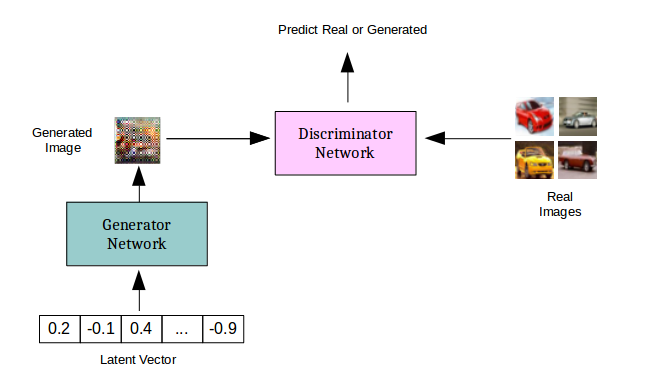
Estendemos o código da Nvidia com base nos princípios do Mixed precision training.
Parte 1 — usando precisão mista no código
Passo 1 - converter o modelo para usar o tipo de dado float16.
Para aproveitar os tensor-cores no treinamento com precisão mista, o código precisa usar FP16 nos cálculos pesados. Como exemplo, mostramos as alterações feitas na rede geradora para usar FP16. As mudanças no código do discriminador e do classificador seguem a mesma linha do gerador.
Começamos com um gerador em precisão simples:
https://gist.github.com/eladshabi/f5abe93ef7dd2e13b3cb2144bb8274a4
Criamos uma camada conv2D customizada usada no modelo gerador:
https://gist.github.com/eladshabi/b9957db1b5d4feff8d6de824af4f7bad
Para treinar com precisão mista, é preciso garantir o seguinte:
- Habilitar o caminho dos Tensor Cores no framework — escolha o formato FP16 para tensores e/ou camadas convolucionais/totalmente conectadas. Esse tipo de dado aproveita automaticamente o hardware dos Tensor Cores sempre que possível. Em outras palavras, para aumentar as chances de aceleração via Tensor Cores, prefira, sempre que der, dimensões de matriz das camadas lineares e contagens de canais convolucionais que sejam múltiplas de oito.
- Salvar os parâmetros treináveis em FP32 e usar uma função getter customizada para convertê-los para FP16 no treinamento.
- Em partes específicas, como camadas de softmax e batch normalization, alimentamos as camadas em float32 para preservar as estatísticas.
Aplicando esses princípios, o código do gerador fica assim:
https://gist.github.com/eladshabi/325aa0a4007343776221bb070b4d962f
Passo 2 - Loss scaling.
O cálculo de gradientes em precisão mista pode levar ao desaparecimento dos gradientes (vanishing gradients). Para evitar esse problema, fazemos o seguinte:
- Multiplicar a loss por um fator de escala.
- Calcular o gradiente a partir da loss escalada.
- Dividir os gradientes pelo fator de escala.
- Seguir com a etapa de otimização normalmente.
Pronto: agora dá para rodar o treinamento com precisão mista usando:
training_step_op_D/G/Q.Parte 2 — analisando os resultados
Resultados da GAN
Para avaliar os resultados da GAN, treinei a rede no dataset Quick-draw por 7 minutos, em uma GPU V100 e com batch size de 1024. Os resultados foram bem nítidos: enquanto a precisão simples só conseguiu gerar ruído, o modo de precisão mista produziu saídas claras e bem definidas.

 Fig 4: lado esquerdo — precisão mista; lado direito — precisão simples, após 7 minutos de treinamento. Classes da esquerda para a direita: Avião, Maçã, Abelha, Pássaro, Livro, Relógio, Vaca, Cachorro, Olho, Peixe.
Fig 4: lado esquerdo — precisão mista; lado direito — precisão simples, após 7 minutos de treinamento. Classes da esquerda para a direita: Avião, Maçã, Abelha, Pássaro, Livro, Relógio, Vaca, Cachorro, Olho, Peixe.
Análise de velocidade e custo de treinamento
Os resultados a seguir foram obtidos com GPUs V100, T4 e P100 para gerar imagens a partir do dataset CIFAR-10.
- Precisão mista com batch size pequeno — A diferença entre treinar em precisão mista e em precisão simples foi insignificante. Além disso, o overhead do casting das variáveis chegou a deixar o treinamento um pouco mais lento.
- Precisão mista com batch size maior — Em GPUs com tensor cores, aumentar o batch size reduziu o tempo médio para concluir um batch em 15%-40%. O maior ganho foi na T4: enquanto a precisão simples levava cerca de 700 ms por batch de 2048 amostras, a precisão mista reduziu esse tempo para aproximadamente 410 ms.
A vantagem dos tensor cores vem da capacidade de fazer cálculos massivos de forma sequencial (carregamento e processamento). Com batch size pequeno, o carregamento acontece com mais frequência e o processamento é mais curto; com batch size maior, é o contrário. Na fig 1 dá para ver a diferença. No treinamento com a P100, que não tem tensor cores, não houve redução no tempo de treinamento (o que confirma que estamos de fato usando os Tensor Cores).
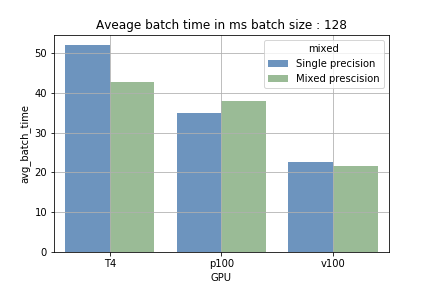
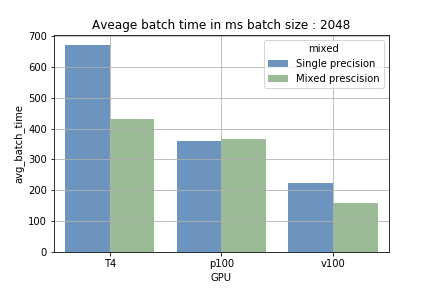 Fig 1: Comparação do tempo médio para rodar um batch.
Fig 1: Comparação do tempo médio para rodar um batch.
Tensor cores podem economizar dinheiro
Os resultados podem ser convertidos em custo de treinamento. Por exemplo, rodar 1000 amostras com diferentes batch sizes no modelo de precisão mista leva menos tempo do que em precisão simples (fig 2). Calculando o preço do treinamento de 1 milhão de batches, dá para ver que usar precisão mista com batch size de 2048 na GPU T4 reduz o custo de US$ 178 para US$ 118 (uma economia de US$ 60 a cada 1 milhão de amostras) (fig 3).
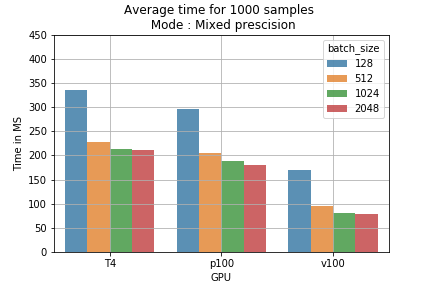
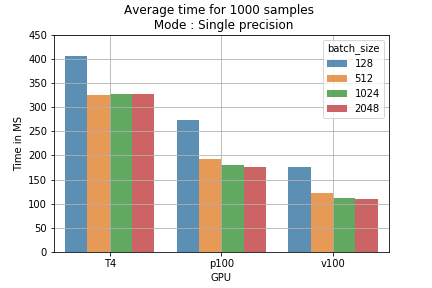 Fig 2: Tempo médio de treinamento para 1000 amostras por batch size e modo de treinamento.
Fig 2: Tempo médio de treinamento para 1000 amostras por batch size e modo de treinamento.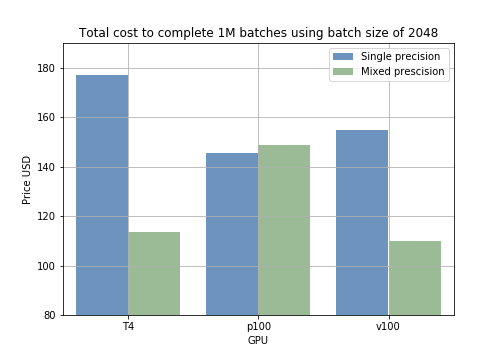 Fig 3: comparação de preços entre modos de treinamento para 1M de batches.
Fig 3: comparação de preços entre modos de treinamento para 1M de batches.
Conclusões
Conforme os modelos de IA ficam mais complexos e aplicações mais inteligentes entram em cena, o cérebro humano vai precisar se desdobrar para viabilizar o treinamento. A tecnologia dos Tensor Cores é, sem dúvida, um divisor de águas no treinamento de IA. Ainda assim, os Tensor Cores rendem mais quando se combinam precisão mista, redes grandes e batch size grande.