
Tensor Coresでニューラルネットワークの学習を加速
ディープニューラルネットワークは、自動運転や通話の文字起こしなど、さまざまな先進的アプリケーションで活用されています。ここ数年は、より大規模で深いネットワークが登場し、これまで以上に高度なアプリケーションが実現してきました。一方で、ネットワークが大規模化・深層化するほど目覚ましい成果が出る反面、学習に時間がかかり、開発や研究のボトルネックにもなっています。そこで登場したのが、Sharan Narang et al. 2018で提案された混合精度(Mixed Precision)と呼ばれる新しい学習手法と、Nvidiaが開発したTensor-Coresというハードウェアです。これらにより、ディープニューラルネットワークの学習はかつてないほど高速になりました。本記事では、Tensorflowで混合精度学習を実装するために必要なコードの変更点を見ていきます。続編では、GANの学習にtensor coresを用いた場合の効果を検証します。
NVIDIA V100
ディープネットワークの学習にはどれくらい時間がかかるのでしょうか。 例えばNvidiaのProgressive GANは、複数のハイエンドGPUを使って20日間学習させ、フェイクのセレブ画像生成で目覚ましい成果を上げました。また、GoogleのNASベースのAutoMLは、画像認識に最適なアーキテクチャを探索するために、800台以上(!)のGPUを数時間にわたって稼働させています。

こうした膨大な学習時間の課題に対応するため、NvidiaやGoogleといったハードウェアメーカーは、TPUやTensor Coresのように学習速度を高めるための専用プロセッサアーキテクチャを開発しています。
ニューラルネットワークの学習は、時間もコストもかかる
なぜ学習に時間がかかるのか
ニューラルネットワークは、ノードとエッジから成る複数の層で構成され、メモリ上では行列として表現されます。学習中、プロセッサは「損失(loss)」と呼ばれるスカラー値を最小化するために、何十億回もの行列乗算を実行します。一般的にソフトウェアは、フォン・ノイマン・アーキテクチャをベースにしたCPU上で動作します。このアーキテクチャはさまざまな命令を柔軟に実行できる一方で、行列乗算には最適化されていません。CPUがメモリの読み書きを繰り返すために学習が遅くなる理由については、Googleのこちらの解説がわかりやすいです。
GPU — 多ければ多いほど良い?
GPUはCPUを拡張したもので、並列計算を行うためにプロセッササブユニット(ALU)の数を増やすという発想に立っています。各コアは、キャッシュもクロックレートも控えめな小型CPUコアといった構成です。これにより、GPUは短時間で大量の演算を処理でき、ニューラルネットワークの学習時間を短縮できます。ただし、GPUはあくまでCPUの拡張にすぎないため、多様なプログラム命令でパフォーマンスを発揮するには、依然としてメモリへの読み書きが必要です。
解決策:AI学習に特化したアーキテクチャ
ここで登場するのが、新世代のGPUコアアーキテクチャ Tensor-cores です。
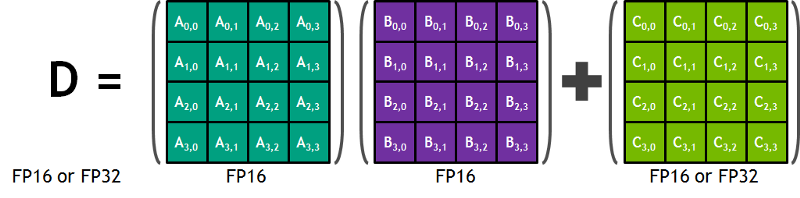
Nvidiaのブログより:「各Tensor Coreは4x4x4の行列処理アレイを備え、D = A * B + C という演算を実行します。ここで A、B、C、D は図1に示すとおり4×4の行列です。行列乗算の入力 A と B はFP16の行列、累算用の行列 C と D はFP16またはFP32の行列です。」このアーキテクチャでは、計算中にメモリアクセスが発生しません。さらに、各tensor coreは別のtensorと接続されており、前段の出力がそのまま次段の入力になる仕組みです。
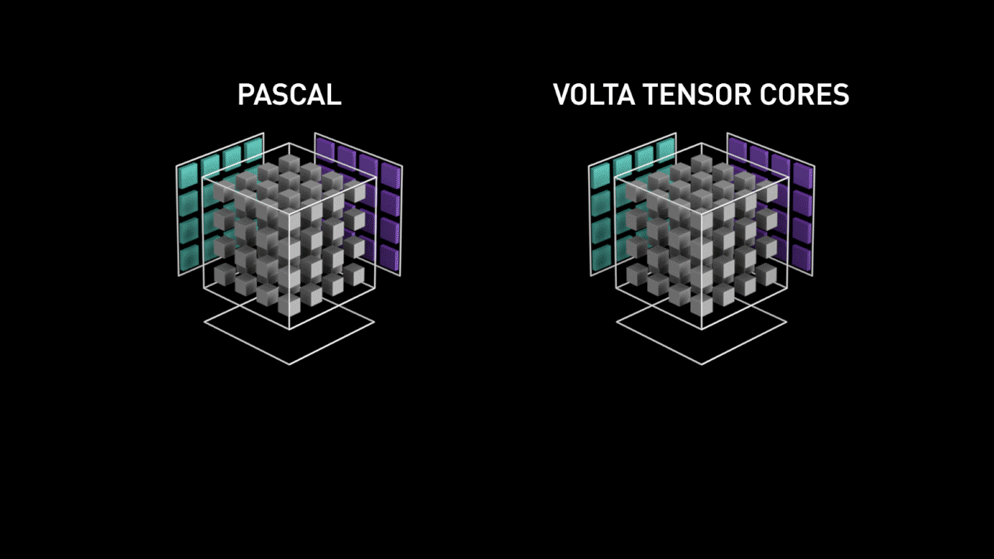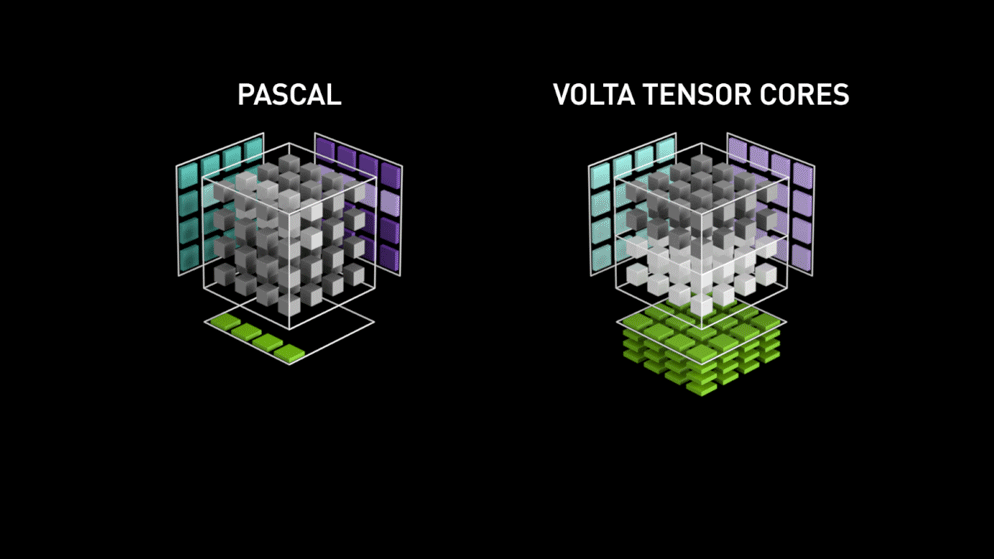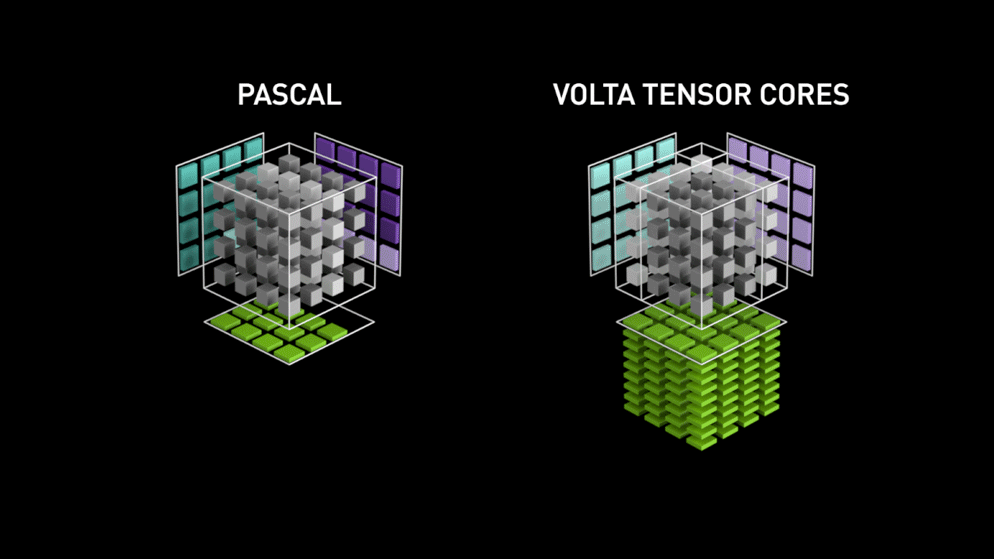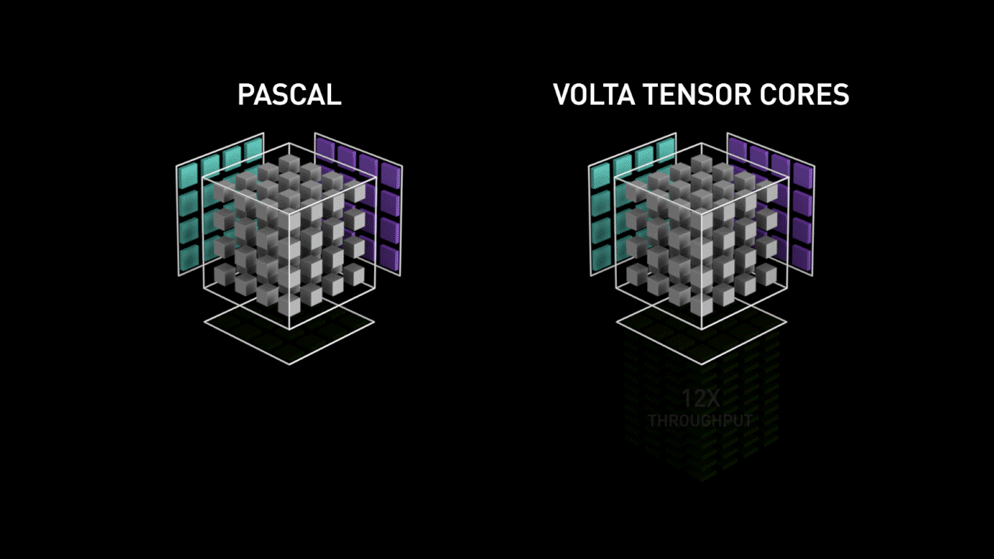
Float 16精度とは
ニューラルネットワークの学習は通常、FP32(単精度)の行列で表現して行います。しかしFP16(半精度)を使うと、計算速度に影響する2つの制約を緩和できます。同じ数の値を表現するのに必要なビット数が減るためメモリ帯域への負荷が下がり、演算時間も短くなります。では、なぜプログラム全体でFP16を使わないのでしょうか。 半精度では、誤差逆伝播の計算でオーバーフローやアンダーフローといったエラーが発生する可能性があります。FP16の表現可能範囲がFP32より狭いためです。例えば誤差逆伝播では、重みの勾配と学習率を乗算しますが、その積が1/²¹⁴を下回ると、次の図のようにゼロに丸められてしまいます。
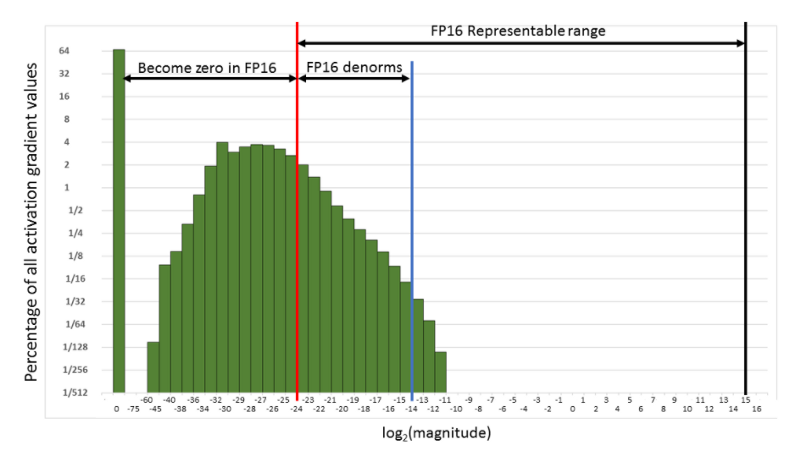 FP16の表現可能範囲
FP16の表現可能範囲
この課題に対処するため、BaiduとNvidiaの研究者は混合精度学習を提案しました。プログラムの特定部分にfloat 16を、それ以外にはfloat 32を引き続き用いるという手法です。
Tensorflowで混合精度を実装する
では、コード上で実際にtensor coresを使うにはどうすればよいのでしょうか。 次の例では、Nvidiaのサンプルコードを少しアレンジして、Tensorflowでディープニューラルネットワークを学習させます。完全なコードはGitHubにあります。
混合精度のステップ:
- FP16データ型でモデルを作成する。
https://gist.github.com/eladshabi/13da6314e5e54c795aea4dfd45002fb7
2. カスタム変数ゲッターを使い、学習対象の変数を
float32で保持してから、学習時の精度にキャストします。
https://gist.github.com/eladshabi/ea3ffda2df47b9e37f8d5b3ee14d66b9
3. Tensorflowの混合精度最適化ライブラリを使う。
https://gist.github.com/eladshabi/205787e471d5ef162630a2766202abc6
4. 学習プロセスで training_opt を使う。
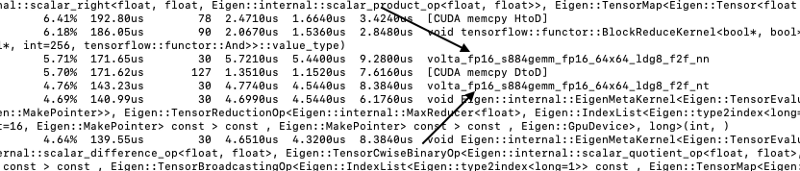
tensor coresが実際に動作していることを確認するには、_「nvprof」_コマンドでスクリプトを実行します。例えば「main.py」を実行する場合は次のとおりです:
nvprof python main.pyすると、学習中にどのコアがアクティブになったかを示すログがコンソールに出力されます。volta_fp16_s884という記述があれば、tensor coresが使われている証拠です。
次回は、混合精度をGANに適用し、T4、P100、V100での結果を比較します。