
Los Tensor Cores le dan un empujón al entrenamiento de tus redes neuronales
Las redes neuronales profundas están detrás de un montón de aplicaciones interesantes, como los autos autónomos o la transcripción de llamadas. En los últimos años se han logrado aplicaciones cada vez más sofisticadas gracias a redes más grandes y profundas. Y aunque esas redes consiguen resultados que rompen récords, su entrenamiento toma más tiempo y termina entorpeciendo el desarrollo y la investigación en este campo. Hoy, con una nueva técnica de entrenamiento llamada Mixed Precision, presentada por Sharan Narang et al 2018, y con el hardware Tensor-Cores de Nvidia, entrenar redes neuronales profundas es más rápido que nunca. En este post repasamos los cambios de código necesarios para aplicar mixed precision con Tensorflow. En un próximo post analizamos el efecto de usar tensor cores para entrenar GANs.
NVIDIA V100
¿Cuánto tarda entrenar una red profunda? La Progressive GAN de Nvidia, por ejemplo, se entrenó durante 20 días con varias GPUs potentes para conseguir resultados sobresalientes generando imágenes falsas de celebridades. Otro caso es AutoML de Google, basado en NAS, que aprovecha más de 800(!) GPUs durante varias horas para encontrar una arquitectura óptima de reconocimiento de imágenes.

Para atacar el problema de los tiempos de entrenamiento tan largos, fabricantes de hardware como Nvidia y Google están desarrollando arquitecturas de procesador dedicadas que aceleran el entrenamiento, como las TPUs y los Tensor Cores.
Entrenar redes neuronales puede tomar mucho tiempo y salir caro.
¿Por qué el entrenamiento toma tanto tiempo?
Una red neuronal se estructura como un conjunto de capas con nodos y aristas que se representan en memoria como matrices. Durante el entrenamiento, el procesador realiza miles de millones de multiplicaciones de matrices para minimizar un escalar llamado "loss". En general, los programas se ejecutan en CPUs basadas en la arquitectura de Von Neumann. Si bien esa arquitectura les da a las CPUs la flexibilidad necesaria para ejecutar todo tipo de instrucciones, no son óptimas para multiplicar matrices. Google tiene una buena explicación acá sobre cómo las CPUs realizan múltiples lecturas y escrituras a memoria y por qué eso ralentiza el entrenamiento.
GPUs: ¿mientras más, mejor?
Las GPUs son una extensión de la CPU; la idea es contar con más subunidades de procesador (ALUs) para hacer cálculos en paralelo. Cada núcleo es como un núcleo de CPU diminuto, con menos caché y menor frecuencia de reloj. Gracias a eso, las GPUs pueden hacer grandes volúmenes de cálculos en poco tiempo y reducir el tiempo de entrenamiento. Sin embargo, como la GPU sigue siendo una extensión de la CPU, para rendir bien con distintos tipos de instrucciones todavía necesita leer y escribir en memoria.
La solución: una arquitectura específica para entrenar IA.
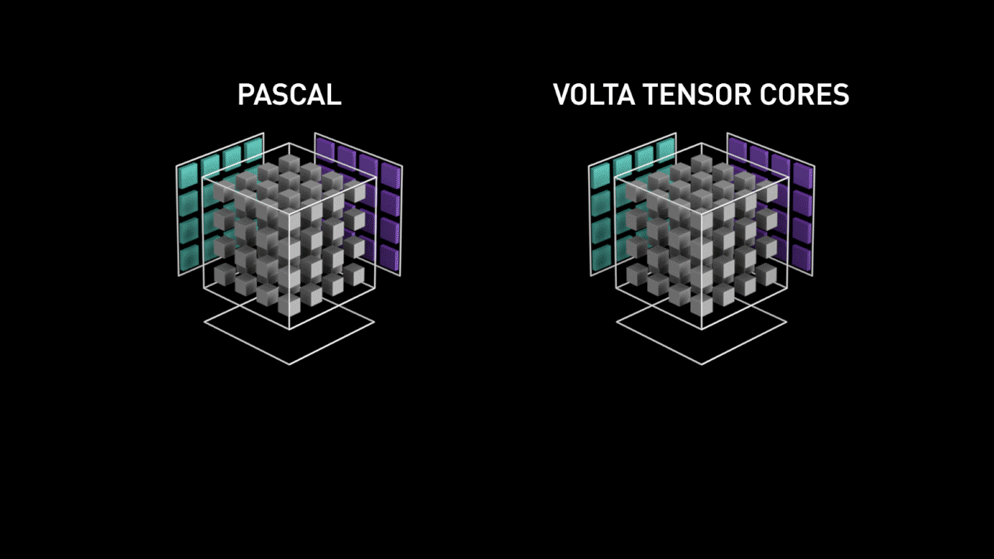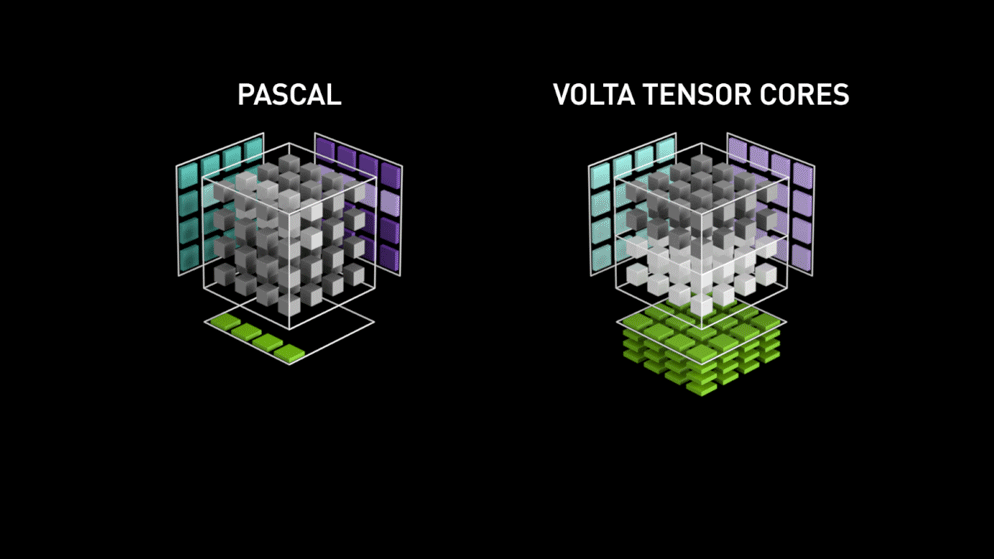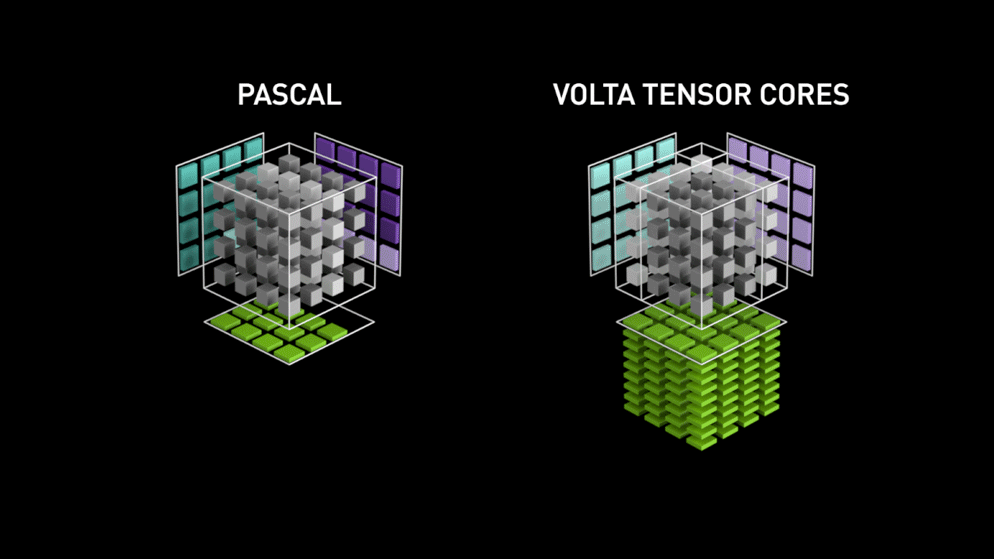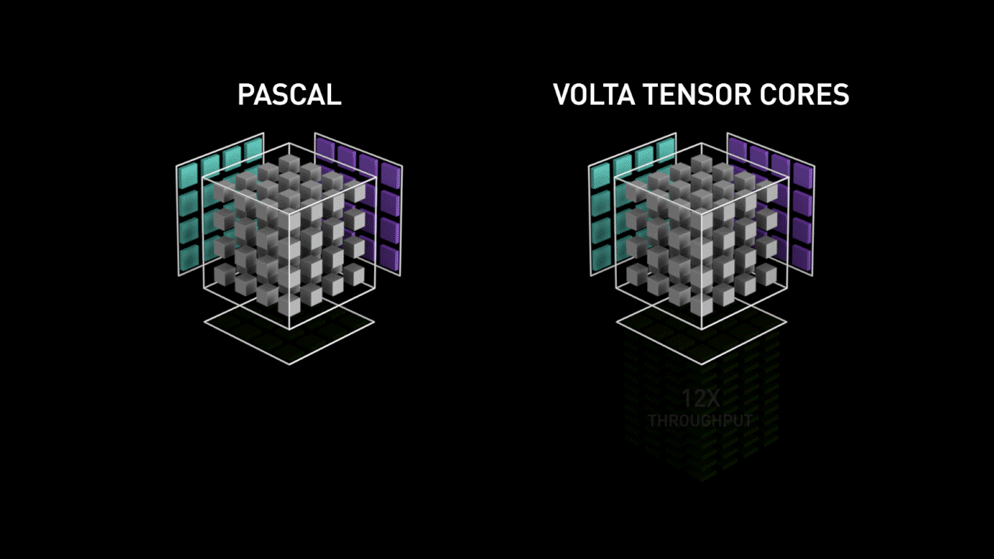
Acá entra la nueva arquitectura de núcleo de GPU: los Tensor-cores.
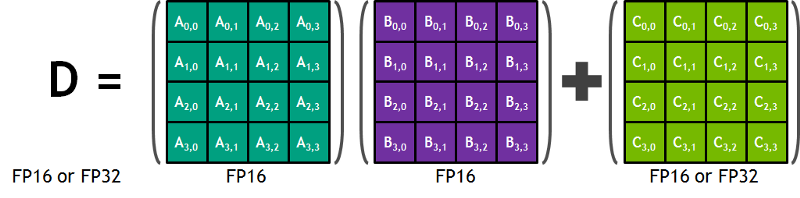
Del blog de Nvidia: "Cada Tensor Core ofrece un arreglo de procesamiento de matrices 4x4x4 que ejecuta la operación D = A * B + C, donde A, B, C y D son matrices de 4×4, como muestra la Figura 1. Las entradas de la multiplicación matricial A y B son matrices FP16, mientras que las matrices de acumulación C y D pueden ser FP16 o FP32." Esta arquitectura no requiere accesos a memoria durante el cálculo. Además, cada tensor core está conectado al siguiente, y la salida del primero se convierte en la entrada del próximo."
¿Precisión Float 16?
Por lo general, el entrenamiento de redes neuronales se hace representándolas como matrices FP32 (Single Precision). Sin embargo, usar FP16 (Half Precision) reduce dos limitantes que afectan la velocidad de cálculo: se baja la presión sobre el ancho de banda de memoria al usar menos bits para representar la misma cantidad de valores, y también se reduce el tiempo aritmético. ¿Por qué no usar FP16 en todo el programa? La media precisión puede provocar errores como overflow y underflow en el cálculo de backpropagation, porque el rango de representación de FP16 es menor que el de FP32. Por ejemplo, durante el backpropagation se multiplican los gradientes de los pesos por la tasa de aprendizaje, y si el producto es menor a 1/²¹⁴ se vuelve cero, como se ve en la siguiente figura.
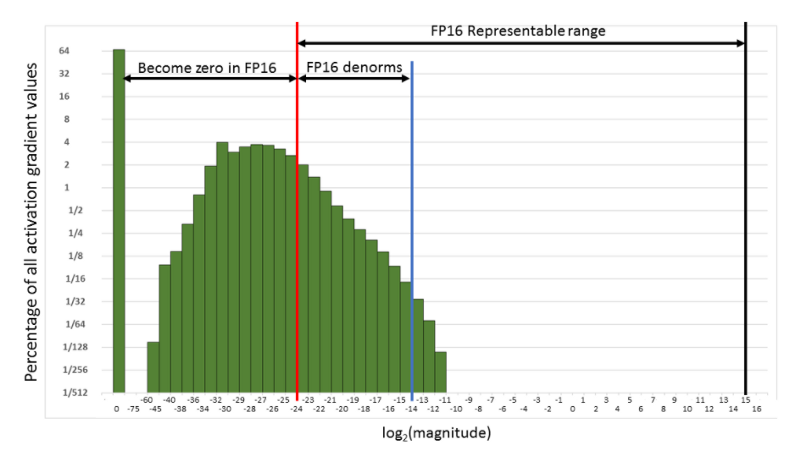 Rango de representación de FP16
Rango de representación de FP16
Para resolver este problema, investigadores de Baidu y Nvidia presentaron el entrenamiento Mixed Precision, en el que ciertas partes del programa usan float 16 mientras que otras se mantienen en float 32.
Cómo programar Mixed Precision en Tensorflow
Listo, ¿pero cómo aprovecho esos tensor cores desde el código? Para el siguiente ejemplo voy a tomar el código de Nvidia y le haré algunos cambios para entrenar redes neuronales profundas con Tensorflow. Encontrarás el código completo en GitHub.
Etapas de mixed precision:
- Crear un modelo usando el tipo de dato FP16.
https://gist.github.com/eladshabi/13da6314e5e54c795aea4dfd45002fb7
2. Usar un getter de variables personalizado que obligue a almacenar las variables entrenables en
precisión float32 y luego las convierta a la precisión de entrenamiento.
https://gist.github.com/eladshabi/ea3ffda2df47b9e37f8d5b3ee14d66b9
3. Usar la librería de optimización de mixed precision de Tensorflow.
https://gist.github.com/eladshabi/205787e471d5ef162630a2766202abc6
4. Usar training_opt en el proceso de entrenamiento.
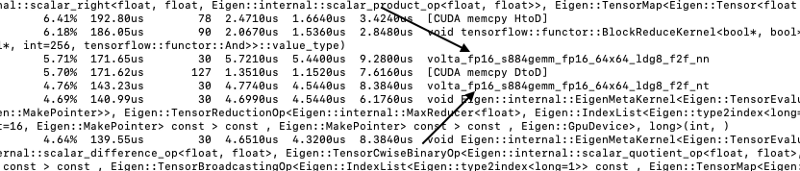
Para confirmar que los tensor cores están funcionando, ejecuta el script con el comando ‘nvprof’; por ejemplo, al correr el script ‘main.py’:
nvprof python main.pyEsto imprimirá en la consola un log que indica qué núcleo se activó durante el entrenamiento. La línea volta_fp16_s884 indica que se están usando los tensor cores.
En la próxima entrega aplicaré el proceso de mixed precision a las GANs y compararé los resultados en T4, P100 y V100.