
Tensor Cores beschleunigen das Training Ihrer neuronalen Netze
Tiefe neuronale Netze stecken in zahlreichen spannenden Anwendungen — von selbstfahrenden Autos bis zur Transkription von Telefonaten. In den letzten Jahren wurden die Netze immer größer und tiefer und damit auch die Anwendungen immer anspruchsvoller. Doch je tiefer und größer das Netz, desto länger dauert das Training — ein echter Bremsklotz für Entwicklung und Forschung. Mit einer neuen Trainingstechnik namens Mixed Precision, vorgestellt von Sharan Narang et al. 2018, und Nvidias Tensor-Cores-Hardware läuft das Training tiefer neuronaler Netze nun so schnell wie nie zuvor. In diesem Blogbeitrag sehen wir uns an, welche Codeänderungen für Mixed Precision mit Tensorflow nötig sind. Im Folgebeitrag untersuchen wir, wie sich Tensor Cores beim Training von GANs auswirken.
NVIDIA V100
Wie lange dauert es, ein tiefes Netz zu trainieren? Nvidias Progressive GAN beispielsweise wurde 20 Tage lang auf mehreren leistungsstarken GPUs trainiert, um beim Generieren täuschend echter Promi-Bilder herausragende Ergebnisse zu erzielen. Ein weiteres Beispiel ist Googles NAS-basiertes AutoML, das über 800 (!) GPUs für mehrere Stunden auslastet, um eine optimale Architektur für die Bilderkennung zu finden.

Um das Problem der langen Trainingszeiten zu lösen, entwickeln Hardware-Hersteller wie Nvidia und Google dedizierte Prozessorarchitekturen, die das Training spürbar beschleunigen — etwa TPUs und Tensor Cores.
Das Training neuronaler Netze ist zeit- und kostenintensiv.
Warum dauert das Training so lange?
Neuronale Netze sind als Schichten aus Knoten und Kanten aufgebaut, die im Speicher als Matrizen abgelegt werden. Während des Trainings führt der Prozessor Milliarden von Matrixmultiplikationen aus, um einen Skalar namens "Loss" zu minimieren. Üblicherweise laufen Programme auf CPUs, die auf der Von-Neumann-Architektur basieren. Diese Architektur macht CPUs flexibel genug für die unterschiedlichsten Befehle — für Matrixmultiplikationen sind sie jedoch nicht optimal. Google liefert hier eine gute Erklärung dazu, warum die vielen Lese- und Schreibzugriffe auf den Speicher das Training ausbremsen.
GPUs — viel hilft viel?
GPUs sind eine Erweiterung der CPU. Die Grundidee: deutlich mehr Recheneinheiten (ALUs) für parallele Berechnungen. Jeder Kern entspricht einem winzigen CPU-Kern mit weniger Cache und niedrigerer Taktrate. Dadurch können GPUs in kurzer Zeit enorme Rechenmengen bewältigen und die Trainingszeit neuronaler Netze deutlich verkürzen. Da die GPU jedoch lediglich eine Erweiterung der CPU ist, muss sie für die unterschiedlichsten Programmbefehle nach wie vor auf den Speicher zugreifen.
Die Lösung: eine eigene Architektur für KI-Training.
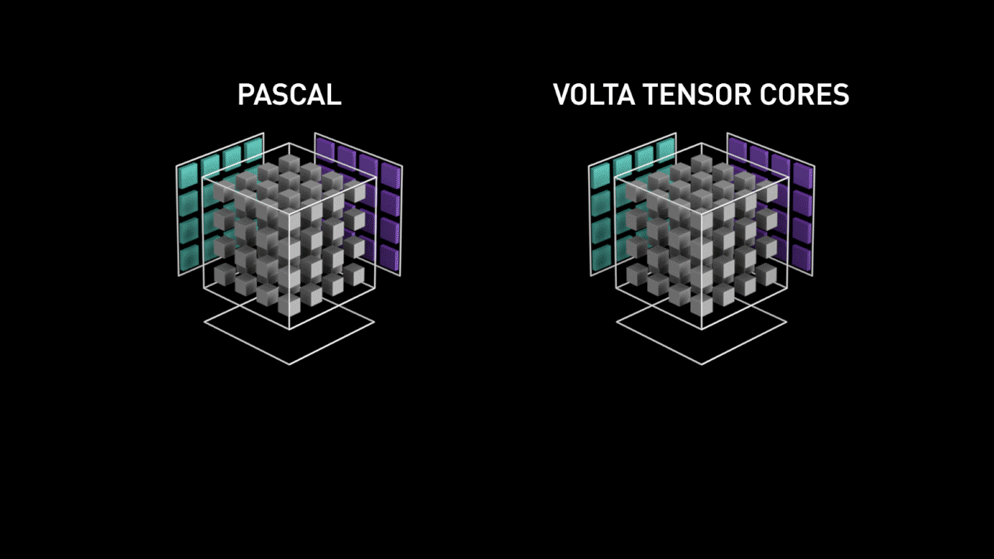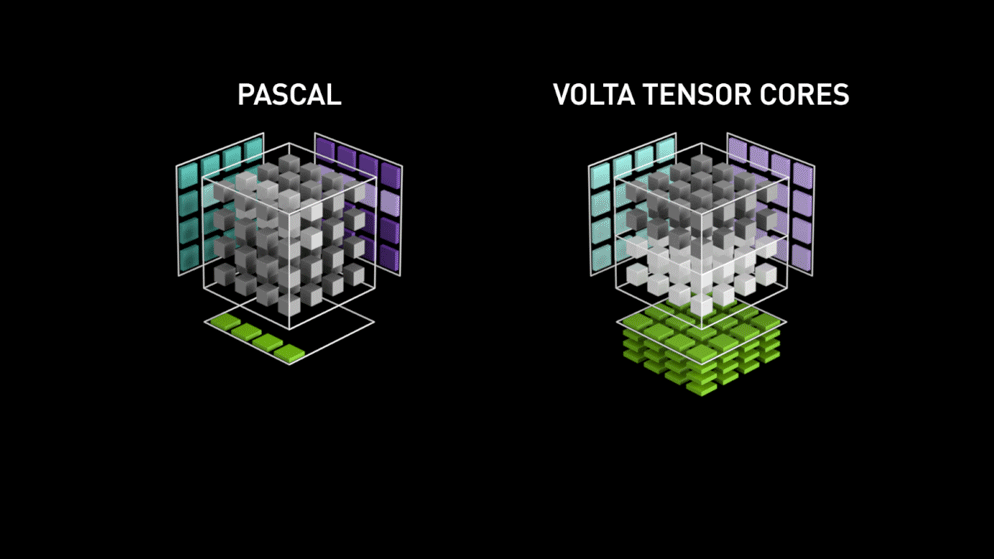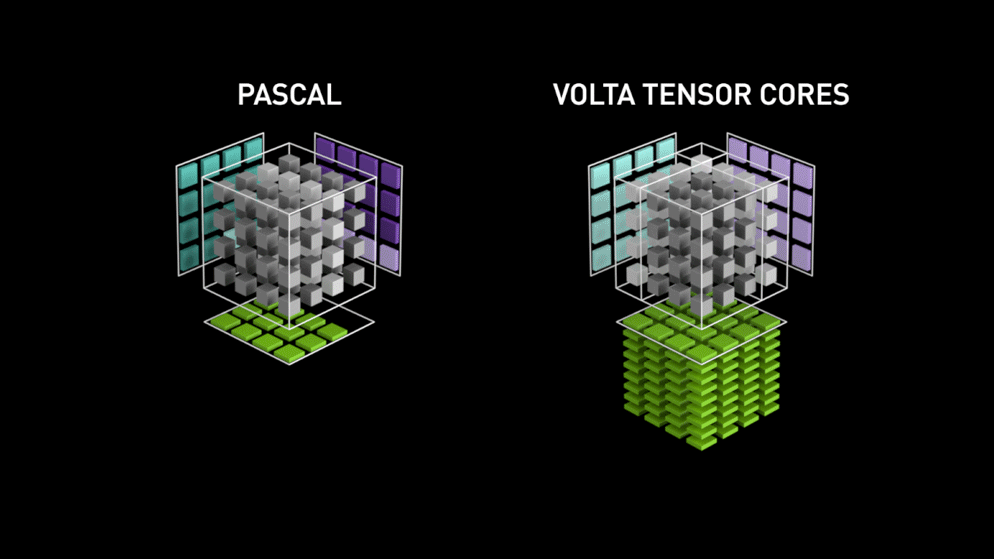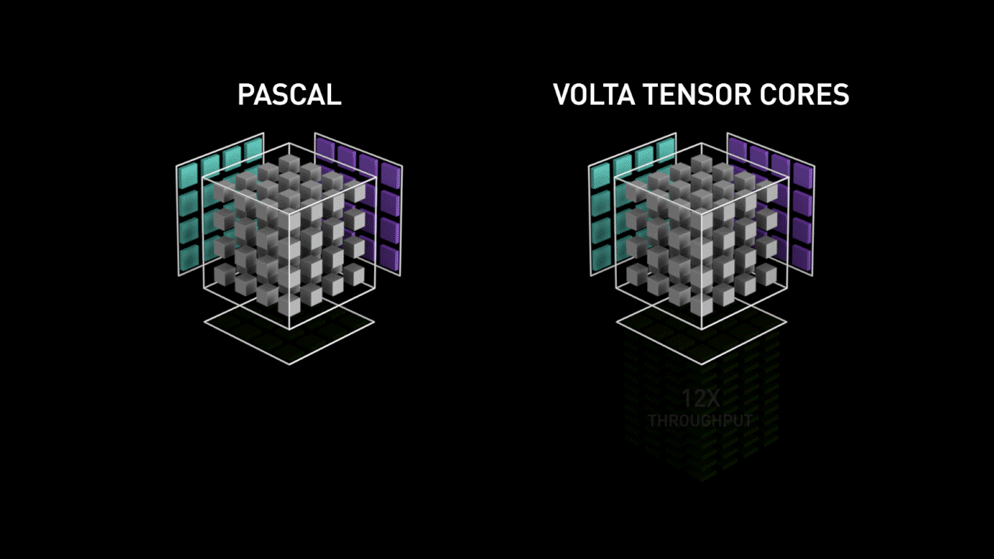
Auftritt der neuen GPU-Kernarchitektur — Tensor Cores.
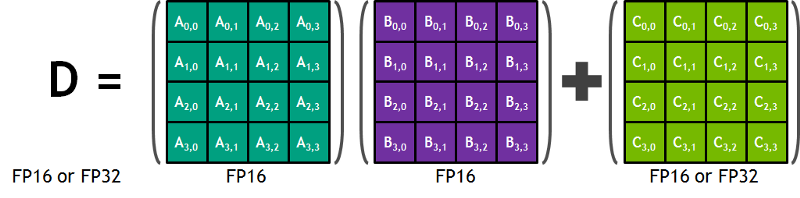
Aus dem Nvidia-Blog: "Jeder Tensor Core stellt ein 4x4x4-Matrix-Verarbeitungs-Array bereit, das die Operation D = A * B + C ausführt, wobei A, B, C und D 4×4-Matrizen sind, wie Abbildung 1 zeigt. Die Eingabematrizen A und B der Matrixmultiplikation sind FP16-Matrizen, während die Akkumulationsmatrizen C und D entweder FP16- oder FP32-Matrizen sein können." Diese Architektur kommt während der Berechnung ohne Speicherzugriffe aus. Zudem ist jeder Tensor Core mit einem weiteren verbunden, sodass die Ausgabe des einen direkt als Eingabe des nächsten dient.
Float-16-Präzision?
Beim Training neuronaler Netze werden diese üblicherweise als Matrizen in FP32 (Single Precision) dargestellt. Der Einsatz von FP16 (Half Precision) lockert jedoch zwei Engpässe, die die Rechengeschwindigkeit ausbremsen: Die Speicherbandbreite wird entlastet, weil weniger Bits zur Darstellung derselben Werte nötig sind, und auch die Rechenzeit der Arithmetik sinkt. Warum dann nicht durchgehend FP16 nutzen? Half Precision kann bei der Backpropagation zu Overflow- und Underflow-Fehlern führen, da der darstellbare Wertebereich von FP16 kleiner ist als der von FP32. Bei der Backpropagation werden zum Beispiel die Gewichts-Gradienten mit der Lernrate multipliziert — liegt das Produkt unter 1/²¹⁴, wird es zu Null, wie die folgende Abbildung zeigt.
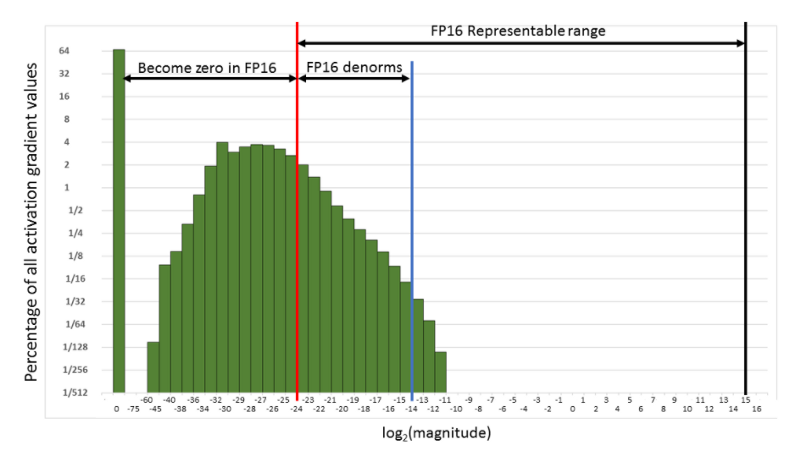 FP16-Wertebereich
FP16-Wertebereich
Zur Lösung dieses Problems haben Forscher von Baidu und Nvidia das Mixed-Precision-Training eingeführt: Bestimmte Teile des Programms arbeiten dabei mit Float 16, während andere Teile in Float 32 verbleiben.
Mixed Precision in Tensorflow umsetzen
Klingt gut — aber wie nutze ich diese Tensor Cores im Code? Für das folgende Beispiel greife ich auf Nvidias Codebeispiel zurück und passe es so an, dass sich damit tiefe neuronale Netze in Tensorflow trainieren lassen. Den vollständigen Code finden Sie auf GitHub.
Die Schritte für Mixed Precision:
- Erstellen Sie ein Modell mit dem Datentyp FP16.
https://gist.github.com/eladshabi/13da6314e5e54c795aea4dfd45002fb7
2. Setzen Sie einen benutzerdefinierten Variable-Getter ein, der trainierbare Variablen in
float32-Präzision speichert und sie anschließend in die Trainingspräzision umwandelt.
https://gist.github.com/eladshabi/ea3ffda2df47b9e37f8d5b3ee14d66b9
3. Nutzen Sie die Mixed-Precision-Optimierungsbibliothek von Tensorflow.
https://gist.github.com/eladshabi/205787e471d5ef162630a2766202abc6
4. Verwenden Sie training_opt für den Trainingsprozess.
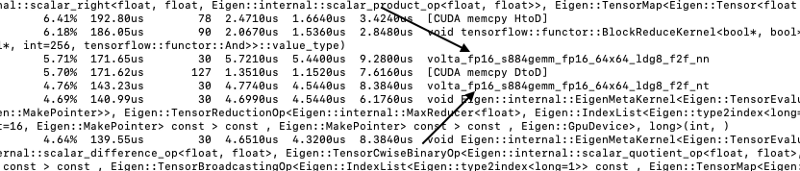
Um zu prüfen, ob die Tensor Cores tatsächlich arbeiten, führen Sie das Skript mit dem Befehl "nvprof" aus — etwa für das Skript "main.py":
nvprof python main.pyIn der Konsole erscheint daraufhin eine Logdatei, die zeigt, welcher Kern während des Trainings aktiv war. Der Eintrag volta_fp16_s884 weist darauf hin, dass die Tensor Cores zum Einsatz kommen.
Im nächsten Teil wende ich Mixed Precision auf GANs an und vergleiche die Ergebnisse auf T4, P100 und V100.