
I Tensor Core danno una marcia in più all'addestramento delle reti neurali
Le reti neurali profonde sono alla base di applicazioni affascinanti, dalle auto a guida autonoma alla trascrizione delle telefonate. Negli ultimi anni hanno reso possibili soluzioni sempre più sofisticate grazie ad architetture più estese e profonde. Reti più grandi e profonde raggiungono però risultati da record al prezzo di tempi di addestramento più lunghi, che frenano sviluppo e ricerca nel settore. Oggi, con una nuova tecnica di addestramento chiamata Mixed Precision, presentata da Sharan Narang et al 2018, e con l'hardware Tensor-Cores di Nvidia, addestrare una rete neurale profonda è più rapido che mai. In questo articolo vedremo le modifiche al codice necessarie per implementare il mixed precision con Tensorflow. In un articolo successivo analizzeremo l'impatto dei tensor core nell'addestramento delle GAN.
NVIDIA V100
Quanto tempo serve per addestrare una rete profonda? La Progressive GAN di Nvidia, ad esempio, è stata addestrata per 20 giorni con più GPU di alto livello per generare immagini fake di celebrità di qualità sorprendente. Un altro caso è AutoML di Google basato su NAS, che impiega oltre 800(!) GPU per diverse ore al fine di individuare l'architettura ottimale per il riconoscimento delle immagini.

Per ridurre i tempi di addestramento, produttori di hardware come Nvidia e Google sviluppano architetture di processori dedicate, come TPU e Tensor Core, capaci di accelerarne notevolmente la velocità.
Addestrare le reti neurali può richiedere molto tempo ed essere costoso.
Perché l'addestramento richiede così tanto tempo?
Le reti neurali sono strutturate come un insieme di livelli, nodi e archi rappresentati in memoria sotto forma di matrici. Durante l'addestramento, il processore esegue miliardi di moltiplicazioni tra matrici per minimizzare uno scalare chiamato "loss". In genere, i programmi software vengono eseguiti su CPU basate sull'architettura di Von Neumann. Questa architettura rende le CPU sufficientemente flessibili da eseguire un'ampia varietà di istruzioni, ma non è ottimale per le moltiplicazioni tra matrici. Google fornisce qui una buona spiegazione di come le CPU eseguano numerose letture e scritture in memoria e del perché ciò rallenti il processo di addestramento.
GPU: più ce ne sono, meglio è?
Le GPU sono un'estensione della CPU: l'idea di fondo è disporre di più sotto-unità di elaborazione (ALU) per eseguire calcoli in parallelo. Ogni core ospita un piccolo core di CPU con meno cache e una frequenza di clock più bassa. Questo permette alle GPU di eseguire grandi quantità di calcoli in tempi brevi, riducendo i tempi di addestramento delle reti neurali. Tuttavia, essendo la GPU semplicemente un'estensione della CPU, per gestire al meglio una varietà di istruzioni deve comunque leggere e scrivere in memoria.
La soluzione: un'architettura specifica per l'AI training.
Ecco la nuova architettura di GPU-core: i Tensor-core.
Dal blog di Nvidia: "Ogni Tensor Core mette a disposizione un array di elaborazione matriciale 4x4x4 che esegue l'operazione D = A * B + C, dove A, B, C e D sono matrici 4×4, come illustrato nella Figura 1. Gli input della moltiplicazione matriciale A e B sono matrici FP16, mentre le matrici di accumulazione C e D possono essere FP16 o FP32." Questa specifica architettura non richiede alcun accesso alla memoria durante il calcolo. Inoltre, ogni tensor core è collegato a un altro tensor core e l'output del primo diventa l'input del successivo."
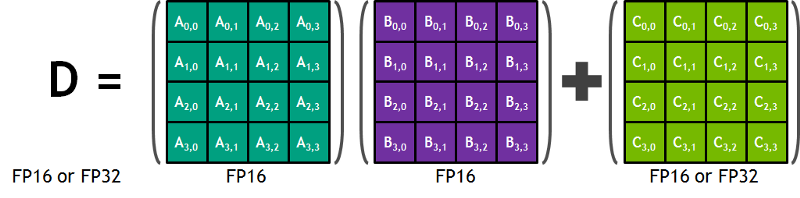
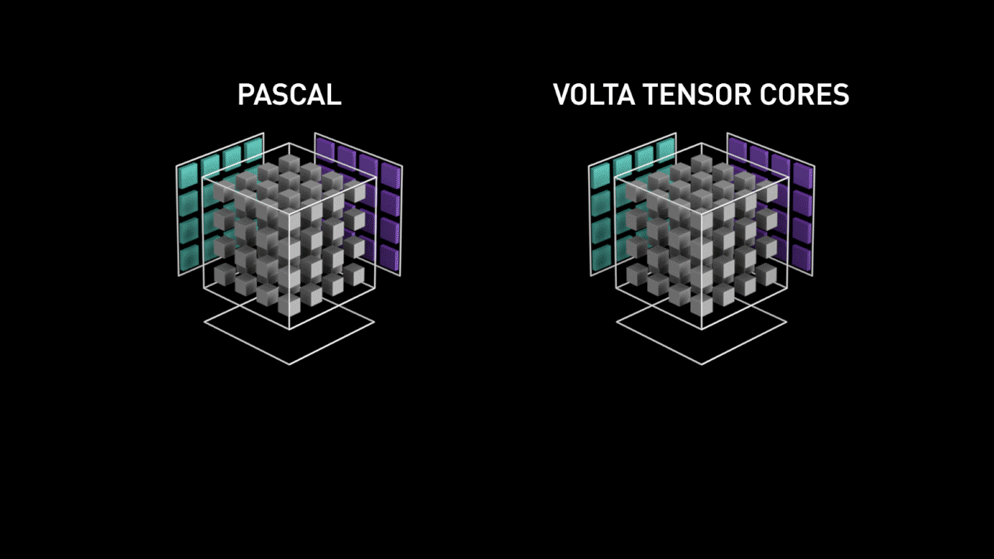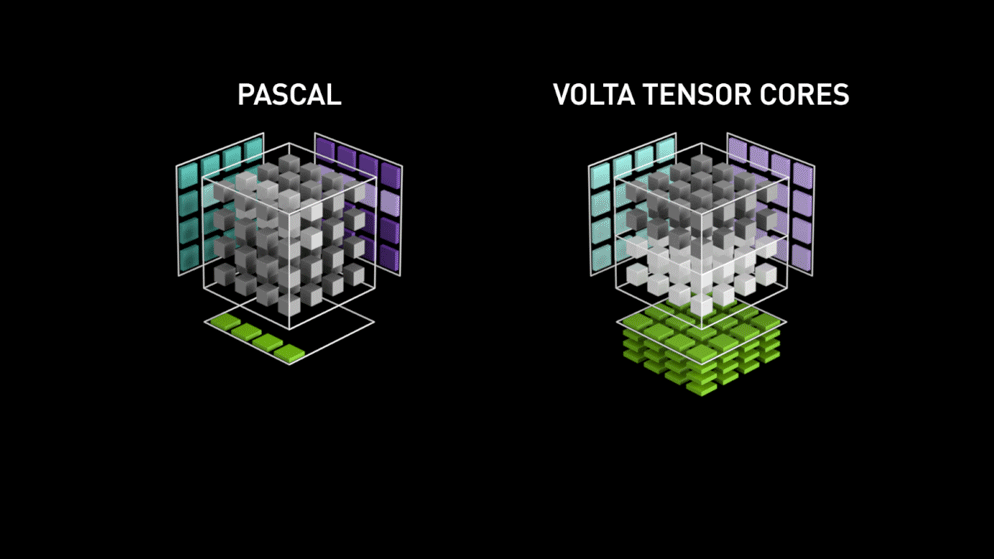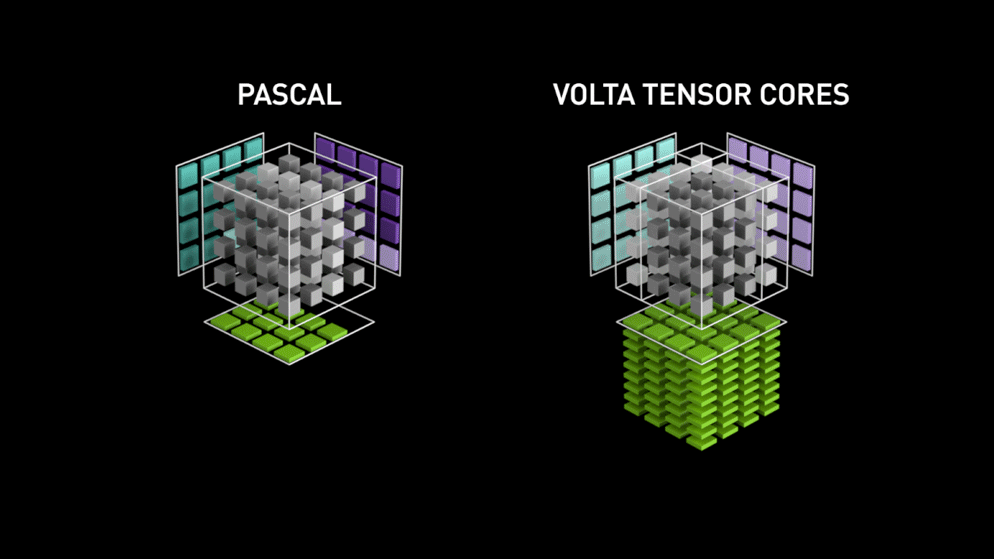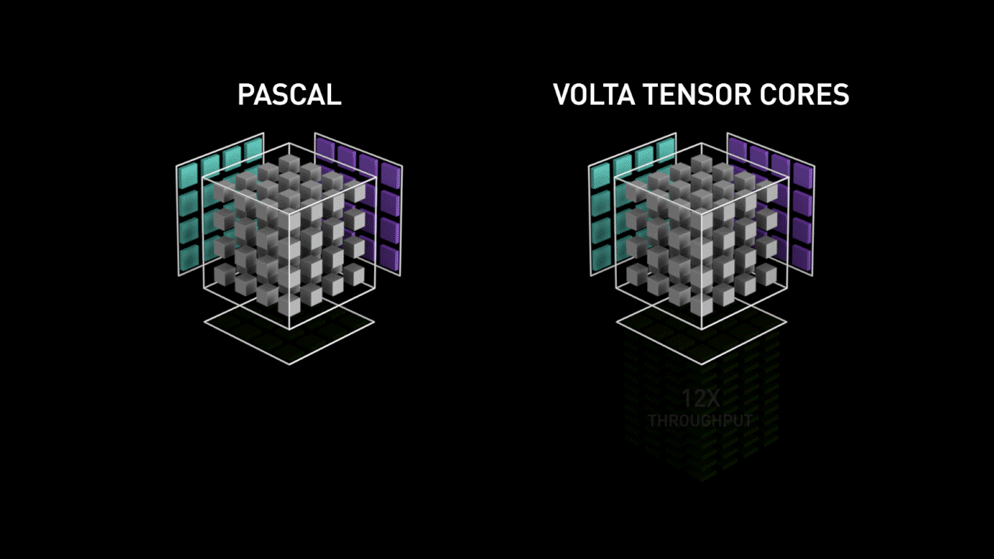
Precisione Float 16?
Di norma, le reti neurali si addestrano rappresentandole come matrici in FP32 (Single Precision). L'utilizzo di FP16 (Half Precision) allenta però due vincoli che incidono sulla velocità di calcolo: la pressione sulla larghezza di banda della memoria diminuisce perché si usano meno bit per rappresentare lo stesso numero di valori e si riduce anche il tempo di esecuzione delle operazioni aritmetiche. Perché allora non usare FP16 per l'intero programma? La half precision può generare errori come overflow e underflow nel calcolo della backpropagation, perché l'intervallo di rappresentazione di FP16 è inferiore a quello di FP32. Nella backpropagation, ad esempio, i gradienti dei pesi vengono moltiplicati per il learning rate e, se il prodotto è inferiore a 1/²¹⁴, viene azzerato, come si vede nella figura seguente.
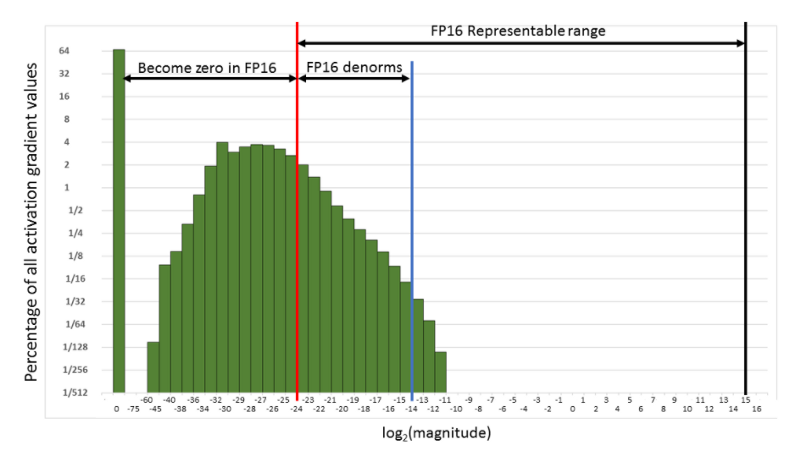 Intervallo di rappresentazione di FP16
Intervallo di rappresentazione di FP16
Per risolvere il problema, i ricercatori di Baidu e Nvidia hanno introdotto il Mixed Precision training: parti specifiche del programma utilizzano float 16, mentre altre rimangono in float 32.
Implementare il Mixed Precision in Tensorflow
Bene, ma come si usano in pratica i tensor core nel codice? Nel prossimo esempio partirò dal codice di esempio di Nvidia e lo adatterò per addestrare reti neurali profonde con Tensorflow. Codice completo su GitHub.
Fasi del mixed precision:
- Creare un modello usando il tipo di dato FP16.
https://gist.github.com/eladshabi/13da6314e5e54c795aea4dfd45002fb7
2. Usare un variable getter personalizzato che imponga la memorizzazione delle variabili addestrabili in
precisione float32, convertendole poi nella precisione di addestramento.
https://gist.github.com/eladshabi/ea3ffda2df47b9e37f8d5b3ee14d66b9
3. Usare la libreria di ottimizzazione mixed precision di Tensorflow.
https://gist.github.com/eladshabi/205787e471d5ef162630a2766202abc6
4. Usare training_opt per il processo di addestramento.
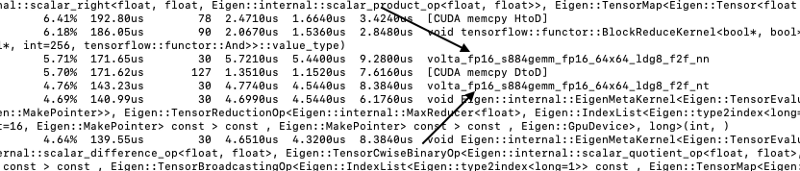
Per verificare che i tensor core siano effettivamente attivi, eseguire lo script con il comando 'nvprof'; ad esempio, per lo script 'main.py':
nvprof python main.pyVerrà stampato in console un file di log con i core attivati durante l'addestramento. La voce volta_fp16_s884 segnala l'utilizzo dei tensor core.
Nella prossima parte applicherò il mixed precision alle GAN e confronterò i risultati su T4, P100 e V100.