
Les Tensor Cores accélèrent l'entraînement de vos réseaux de neurones
Les réseaux de neurones profonds alimentent une multitude d'applications passionnantes : voitures autonomes, transcription d'appels téléphoniques, etc. Ces dernières années, ils ont permis de concevoir des applications toujours plus sophistiquées en s'appuyant sur des architectures plus larges et plus profondes. Mais si ces réseaux affichent des résultats records, leur entraînement demande davantage de temps, ce qui freine la recherche et le développement dans ce domaine. Aujourd'hui, grâce à une nouvelle technique d'entraînement baptisée Mixed Precision, présentée par Sharan Narang et al. 2018, et au matériel Tensor-Cores de Nvidia, l'entraînement des réseaux de neurones profonds n'a jamais été aussi rapide. Dans cet article, nous passons en revue les modifications de code à apporter pour mettre en œuvre la précision mixte avec Tensorflow. Dans un prochain article, nous étudierons l'apport des Tensor Cores pour l'entraînement des GAN.
NVIDIA V100
Combien de temps faut-il pour entraîner un réseau profond ? Le Progressive GAN de Nvidia, par exemple, a nécessité 20 jours d'entraînement sur plusieurs GPU haut de gamme pour générer des images de fausses célébrités d'un réalisme bluffant. Autre exemple : l'AutoML de Google reposant sur NAS, qui mobilise plus de 800 (!) GPU pendant plusieurs heures pour identifier l'architecture optimale de reconnaissance d'image.

Pour répondre à ces temps d'entraînement à rallonge, des fabricants comme Nvidia et Google développent des architectures de processeurs dédiées qui accélèrent l'entraînement, à l'image des TPU et des Tensor Cores.
Entraîner des réseaux de neurones peut être long et coûteux.
Pourquoi l'entraînement prend-il autant de temps ?
Un réseau de neurones se compose d'un ensemble de couches, de nœuds et d'arêtes représentés en mémoire sous forme de matrices. Pendant l'entraînement, le processeur effectue des milliards de multiplications matricielles afin de minimiser un scalaire appelé loss. De manière générale, les programmes s'exécutent sur des CPU reposant sur l'architecture de Von Neumann. Si cette architecture rend les CPU suffisamment polyvalents pour exécuter des instructions très variées, ils ne sont pas optimaux pour la multiplication matricielle. Google propose une bonne explication sur la façon dont les CPU multiplient les lectures et écritures en mémoire et sur les raisons pour lesquelles cela ralentit l'entraînement.
GPU — plus on en a, mieux c'est ?
Les GPU sont une extension du CPU : l'idée consiste à disposer de davantage de sous-unités de calcul (ALU) afin d'exécuter des opérations en parallèle. Chaque cœur abrite un petit cœur CPU doté de moins de cache et d'une fréquence d'horloge plus basse. Les GPU peuvent ainsi réaliser un grand volume de calculs en peu de temps et réduire d'autant le temps d'entraînement des réseaux de neurones. Cependant, comme le GPU n'est qu'une extension du CPU, il doit lui aussi accéder à la mémoire en lecture et en écriture pour traiter une variété d'instructions.
La solution : une architecture pensée pour l'entraînement de l'IA.
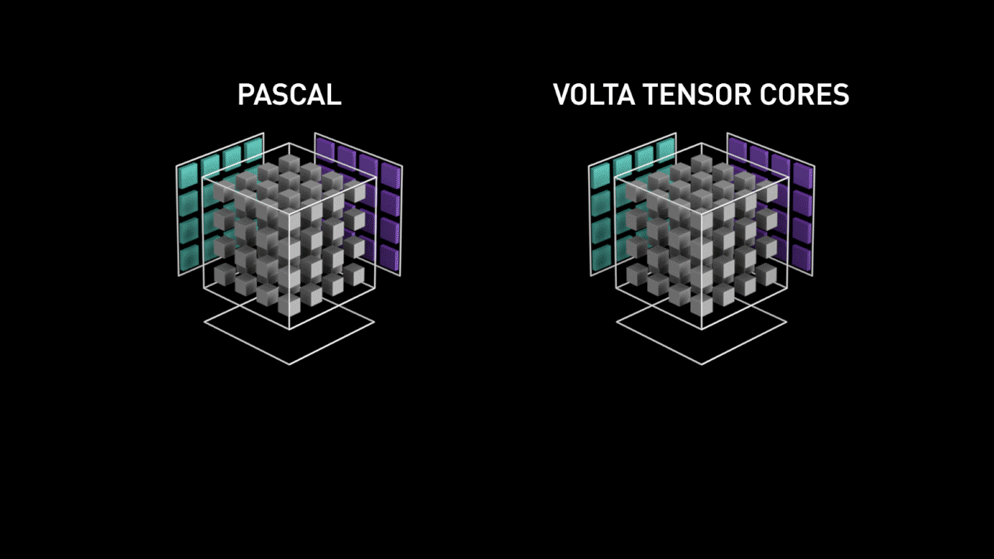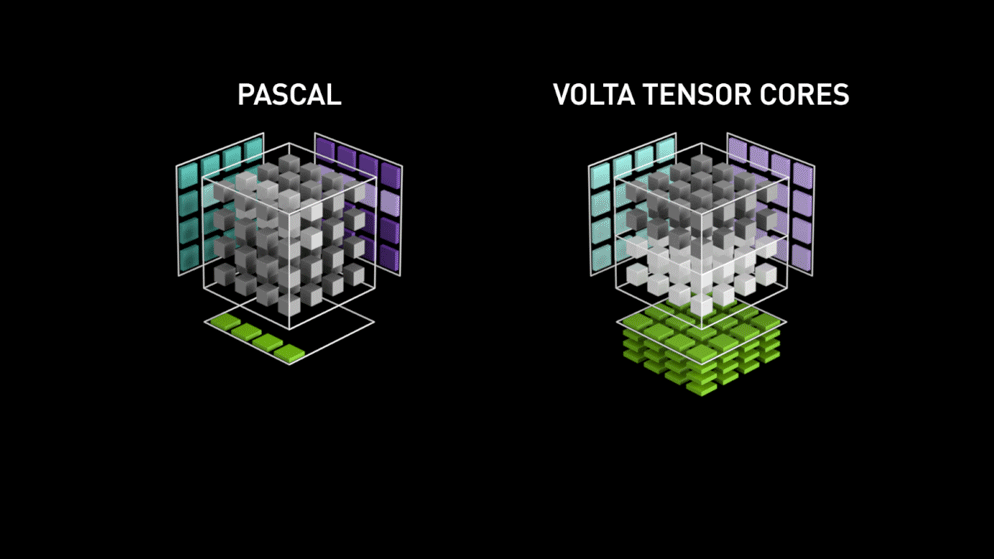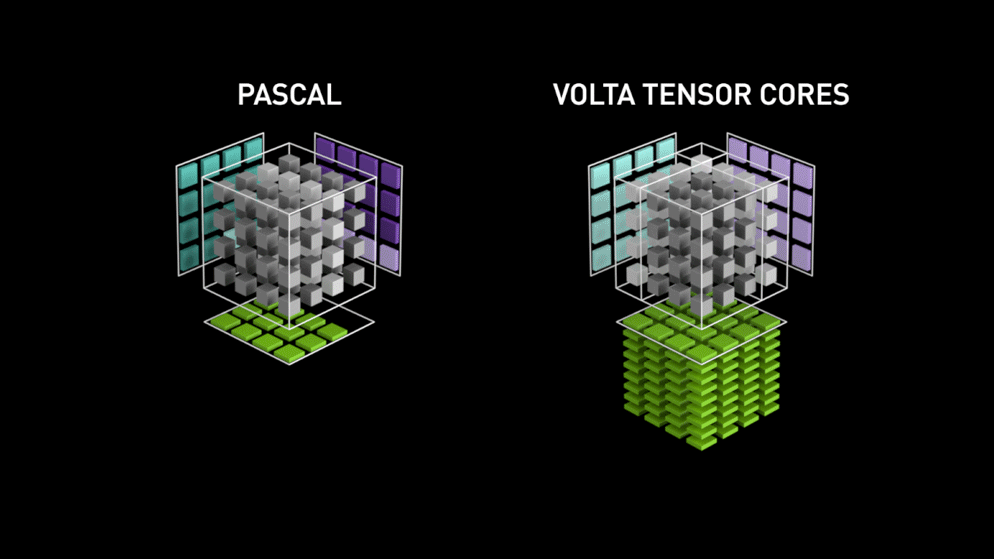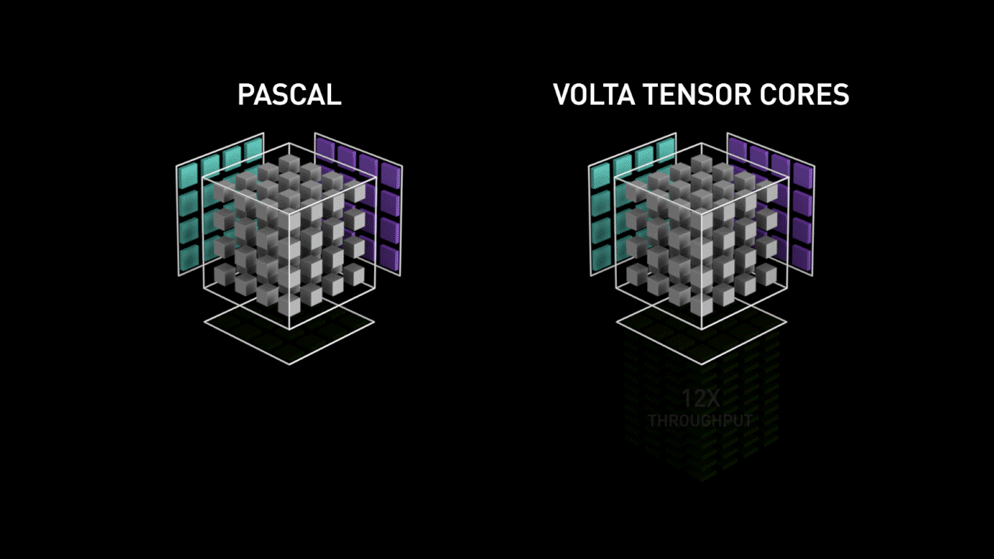
Place à la nouvelle architecture de cœurs GPU : les Tensor-cores.
Extrait du blog de Nvidia : " Chaque Tensor Core fournit un tableau de traitement matriciel 4x4x4 qui exécute l'opération D = A * B + C, où A, B, C et D sont des matrices 4×4, comme l'illustre la figure 1. Les entrées de la multiplication matricielle A et B sont des matrices FP16, tandis que les matrices d'accumulation C et D peuvent être en FP16 ou en FP32. " Cette architecture spécifique ne nécessite aucun accès mémoire pendant le calcul. Mieux encore, chaque Tensor Core est connecté à un autre, et la sortie du premier devient l'entrée du suivant.
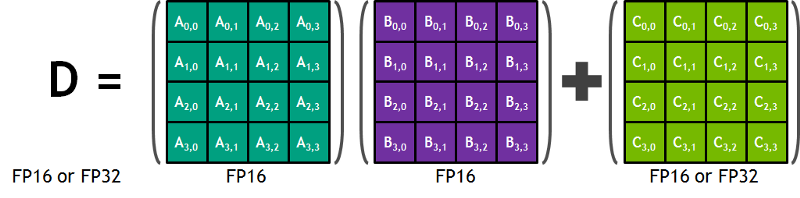
Précision Float 16 ?
L'entraînement des réseaux de neurones se fait habituellement en les représentant sous forme de matrices en FP32 (simple précision). Le passage au FP16 (demi-précision) lève deux contraintes qui pèsent sur la vitesse de calcul : la pression sur la bande passante mémoire diminue, puisqu'il faut moins de bits pour représenter le même nombre de valeurs, et le temps de calcul arithmétique se réduit également. Pourquoi ne pas utiliser le FP16 pour l'ensemble du programme ? La demi-précision peut générer des erreurs de dépassement (overflow) et de sous-dépassement (underflow) lors du calcul de la rétropropagation, car la plage de représentation du FP16 est plus étroite que celle du FP32. Ainsi, lors de la rétropropagation, on multiplie les gradients de poids par le taux d'apprentissage : si le produit est inférieur à 1/²¹⁴, il est ramené à zéro, comme l'illustre la figure suivante.
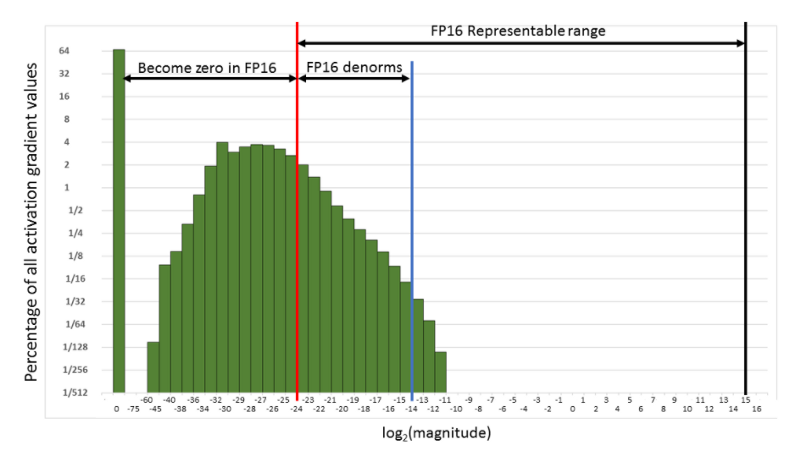 Plage de représentation du FP16
Plage de représentation du FP16
Pour résoudre ce problème, les chercheurs de Baidu et de Nvidia ont introduit l'entraînement en précision mixte (Mixed Precision) : certaines parties du programme utilisent du float 16, tandis que d'autres restent en float 32.
Coder la précision mixte avec Tensorflow
Très bien, mais comment exploiter ces Tensor Cores en pratique ? Pour l'exemple qui suit, je pars du code de Nvidia et je l'adapte pour entraîner des réseaux de neurones profonds avec Tensorflow. Le code complet est disponible sur GitHub.
Étapes de la précision mixte :
- Créer un modèle avec le type de données FP16.
https://gist.github.com/eladshabi/13da6314e5e54c795aea4dfd45002fb7
2. Utiliser un getter de variables personnalisé qui force le stockage des variables entraînables en
précision float32, puis les convertit à la précision d'entraînement.
https://gist.github.com/eladshabi/ea3ffda2df47b9e37f8d5b3ee14d66b9
3. Utiliser la bibliothèque d'optimisation en précision mixte de Tensorflow.
https://gist.github.com/eladshabi/205787e471d5ef162630a2766202abc6
4. Utiliser training_opt pour le processus d'entraînement.
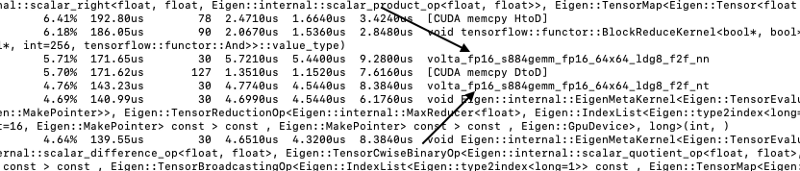
Pour vérifier que les Tensor Cores sont bien sollicités, lancez le script avec la commande nvprof. Par exemple, pour exécuter le script main.py :
nvprof python main.pyCela affiche dans la console un journal indiquant quels cœurs ont été activés pendant l'entraînement. La mention volta_fp16_s884 confirme l'utilisation des Tensor Cores.
Dans la prochaine partie, j'appliquerai la précision mixte aux GAN et comparerai les résultats sur T4, P100 et V100.