
Os Tensor Cores turbinam o treinamento da sua rede neural
Redes neurais profundas estão por trás de aplicações incríveis, como carros autônomos e a transcrição de chamadas telefônicas. Nos últimos anos, redes maiores e mais profundas viabilizaram aplicações cada vez mais sofisticadas. Mas, embora entreguem resultados que batem recordes, o treinamento dessas redes consome muito tempo e acaba travando o desenvolvimento e a pesquisa na área. Agora, com uma nova técnica de treinamento chamada Mixed Precision, apresentada por Sharan Narang et al 2018, e com um hardware da Nvidia chamado Tensor-Cores, treinar redes neurais profundas ficou mais rápido do que nunca. Neste post, vamos ver as mudanças de código necessárias para aplicar precisão mista no TensorFlow. No próximo post, analisamos o efeito do uso de tensor cores no treinamento de GANs.
NVIDIA V100
Quanto tempo leva para treinar uma rede profunda? A Progressive GAN, da Nvidia, por exemplo, foi treinada por 20 dias em várias GPUs potentes para chegar a resultados impressionantes na geração de imagens falsas de celebridades. Outro exemplo é o AutoML do Google, baseado em NAS, que usa mais de 800(!) GPUs por várias horas para encontrar uma arquitetura ideal de reconhecimento de imagens.

Para enfrentar esse problema do tempo extenso de treinamento, fabricantes de hardware como Nvidia e Google vêm desenvolvendo arquiteturas de processador dedicadas que aceleram o treinamento, como TPUs e Tensor Cores.
Treinar redes neurais pode demorar bastante e sair caro.
Por que o treinamento demora tanto?
As redes neurais são estruturadas como um conjunto de camadas, nós e arestas, representados na memória em forma de matrizes. Durante o treinamento, o processador executa bilhões de multiplicações de matrizes para minimizar um escalar chamado "loss". Em geral, programas de software rodam em CPUs baseadas na arquitetura de Von Neumann. Embora essa arquitetura deixe as CPUs flexíveis o bastante para executar uma variedade de instruções, elas não são ideais para multiplicações de matrizes. O Google tem uma boa explicação aqui sobre como as CPUs fazem várias leituras e escritas na memória e por que isso atrasa o treinamento.
GPUs — quanto mais, melhor?
As GPUs são uma extensão da CPU; a ideia é ter mais subunidades de processamento (ALUs) para executar cálculos em paralelo. Cada núcleo funciona como um pequeno núcleo de CPU, com menos cache e clock mais baixo. Por isso, as GPUs conseguem processar grandes volumes de cálculo em pouco tempo, reduzindo o tempo de treinamento das redes neurais. Mesmo assim, como a GPU é só uma extensão da CPU, para ter um bom desempenho em diferentes instruções de programa ela ainda precisa ler e escrever na memória.
A solução: uma arquitetura específica para treinamento de IA.
É aí que entra a nova arquitetura de núcleo de GPU — os Tensor-cores.
do blog da Nvidia: "Cada Tensor Core fornece um array de processamento de matriz 4x4x4 que executa a operação D = A * B + C, em que A, B, C e D são matrizes 4×4, como mostra a Figura 1. As matrizes de entrada da multiplicação A e B são matrizes FP16, enquanto as matrizes de acumulação C e D podem ser FP16 ou FP32." Essa arquitetura dispensa o acesso à memória durante o cálculo. Além disso, cada tensor core é conectado a outro, e a saída do primeiro vira a entrada do seguinte."
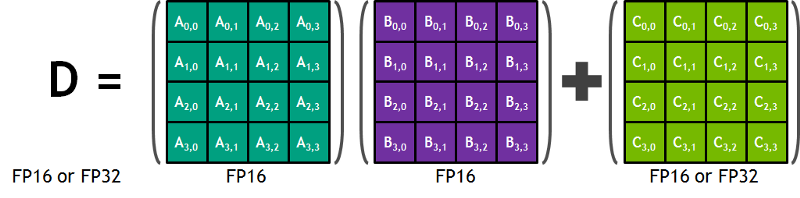
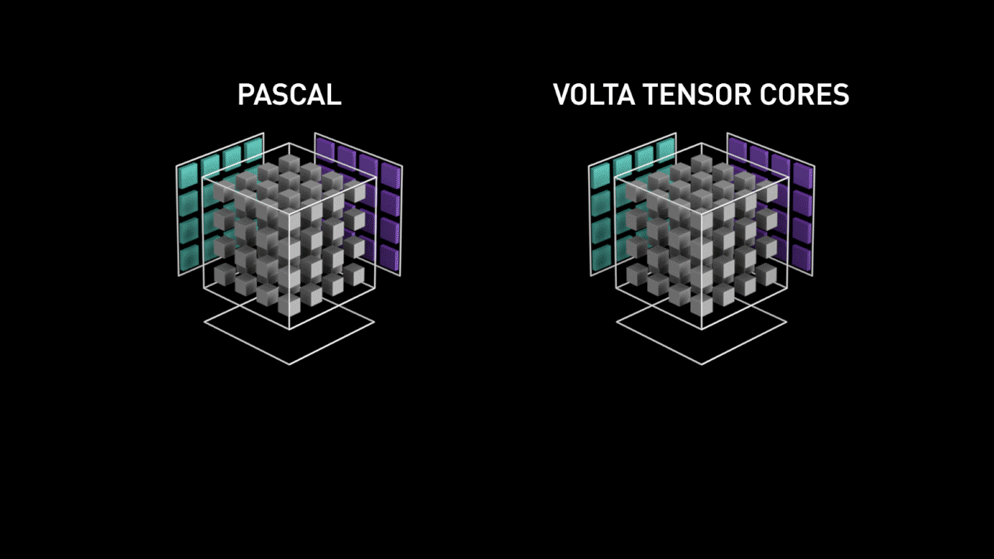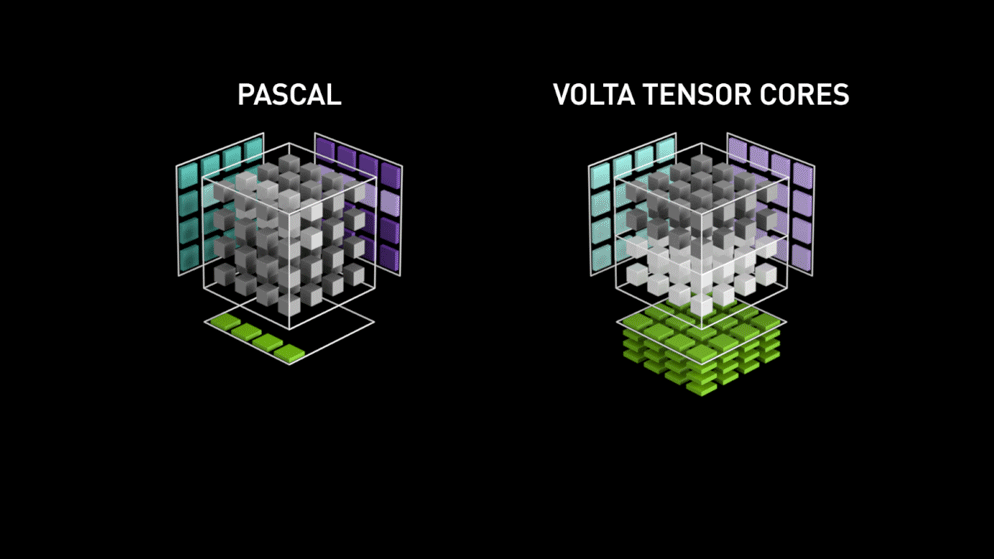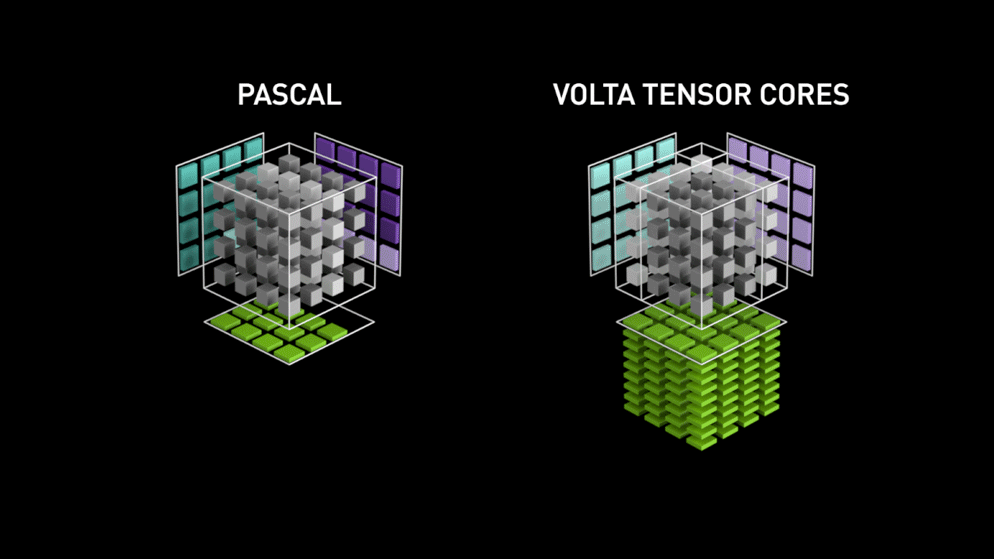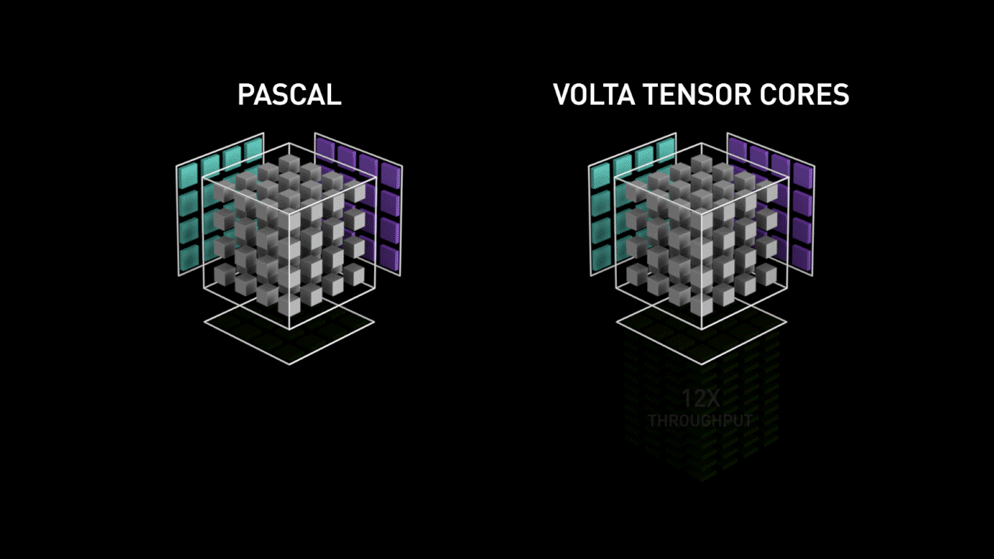
Precisão Float 16?
Em geral, o treinamento de redes neurais é feito representando-as como matrizes em FP32 (Single Precision). Mas usar FP16 (Half Precision) reduz duas restrições que impactam a velocidade de cálculo: a pressão sobre a largura de banda da memória cai, porque são usados menos bits para representar a mesma quantidade de valores, e o tempo aritmético também diminui. Então por que não usar FP16 no programa inteiro? A meia precisão pode gerar erros como overflow e underflow no cálculo de retropropagação, já que o intervalo de representação do FP16 é menor que o do FP32. No processo de retropropagação, por exemplo, os gradientes dos pesos são multiplicados pela taxa de aprendizado, e se o resultado for menor que 1/²¹⁴, ele vira zero, como dá para ver na próxima figura.
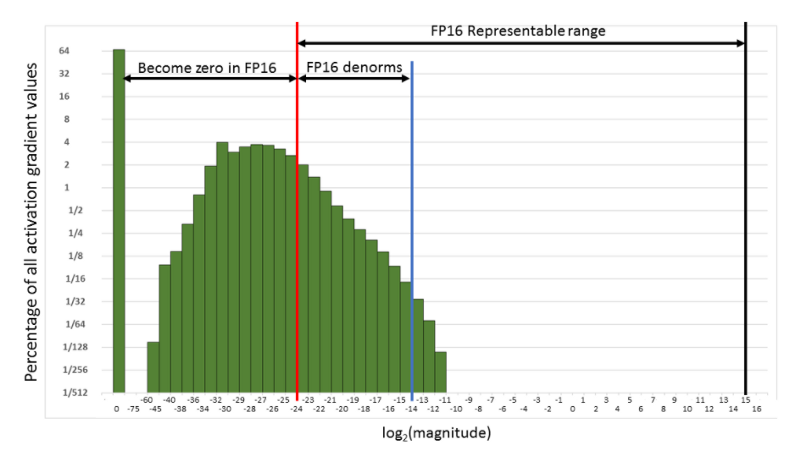 Intervalo de representação do FP16
Intervalo de representação do FP16
Para contornar esse problema, pesquisadores da Baidu e da Nvidia criaram o treinamento Mixed Precision, em que partes específicas do programa usam float 16 e outras seguem em float 32.
Programando Mixed Precision no TensorFlow
Beleza, mas como eu uso esses tensor cores no código? No próximo exemplo, vou partir do código de exemplo da Nvidia e fazer alguns ajustes para treinar redes neurais profundas com TensorFlow. O código completo está no GitHub.
Etapas da precisão mista:
- Crie um modelo usando o tipo de dado FP16.
https://gist.github.com/eladshabi/13da6314e5e54c795aea4dfd45002fb7
2. Use um getter de variável customizado que obrigue as variáveis treináveis a serem armazenadas em
precisão float32 e, depois, faça o cast para a precisão de treinamento.
https://gist.github.com/eladshabi/ea3ffda2df47b9e37f8d5b3ee14d66b9
3. Use a biblioteca de otimização de precisão mista do TensorFlow.
https://gist.github.com/eladshabi/205787e471d5ef162630a2766202abc6
4. Use o training_opt no processo de treinamento.
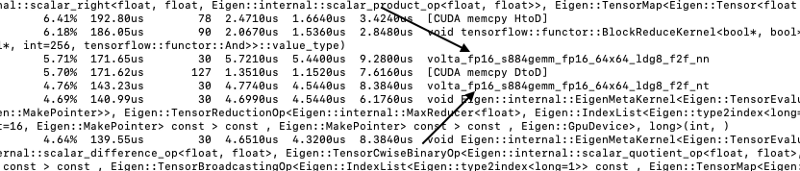
Para confirmar se os tensor cores estão funcionando, use o comando ‘nvprof’ para rodar o script — por exemplo, executando o script ‘main.py’:
nvprof python main.pyisso vai imprimir no console um arquivo de log indicando qual núcleo foi ativado durante o treinamento. O volta_fp16_s884 sinaliza o uso dos tensor cores.
Na próxima parte, vou aplicar o processo de precisão mista em GANs e comparar os resultados em T4, P100 e V100.