
rate()に本来の仕事をさせるまでの長い道のり
先日、Prometheus監視システムについて2回シリーズの講演を行いました。2回目の講演の最後では、メトリクスの変化がいつの間にか闇に葬られてしまうという、やや込み入ったテーマに触れました。本記事はその講演のフォローアップとして、一見すると矛盾に思える挙動について詳しく掘り下げるものです。

「Prometheus洞窟」として知られるクミスタヴィ洞窟の内部
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
(エラー)カウンタは初期化しよう
可能であれば、カウンタは0で初期化しておきましょう。そうすればメトリクスは即座に値0として報告され始めます。理由は次のとおりです。
 カウンタで重要なのは変化だけ
カウンタで重要なのは変化だけ
上の図は、ゼロで初期化されていないメトリクスの例です。最初のエラーが発生して「1」が報告されると、Prometheus(以降は簡潔さのため「P8s」と呼びます)はそれを問題なく保存します。しかしP8sから見れば、_メトリクスには変化がなかった_ことになります。そのため、このカウンタの変化を監視するアラートを設定していても最初のエラーは確実に取りこぼされ、ポケベルを持たされた誰かが悲しい顔をすることになるでしょう。
これはP8s初心者には意外に思えるかもしれませんが、理屈は単純です。そして本記事で取り上げる問題のうち、アプリ開発者側で対処すべきものはこれだけです。
では、もっと込み入った話に進みましょう。
rate()が変化をまったく示さない
緩やかに増加するカウンタ(エラーカウンタなど)に対してrate()を実行すると、レンジをセオリーどおりに設定しているのにすべてゼロが返ってくる――そんな現象によく遭遇しました。「もしかして本当にカウンタが増えていないだけかも」と自分に言い聞かせてみたものの、そうではありませんでした。
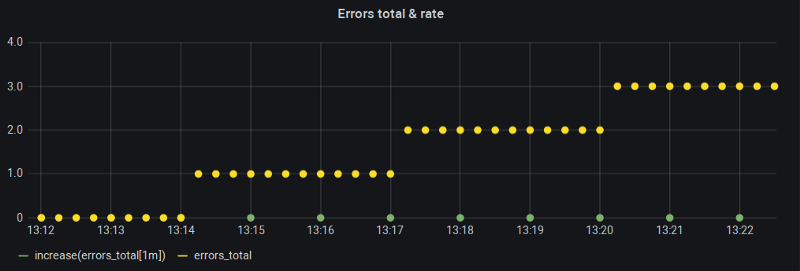 カウンタは増えているのにrate()は動かない
カウンタは増えているのにrate()は動かない
Grafanaの「Min step」(つまり$__interval)は1分に固定し、スクレイプ間隔は15秒。これはrate()関数の推奨ルックバック幅にぴったり合致します。では何が問題なのでしょうか。
これを理解するには、もう一度黒板に立ち戻る必要があります。
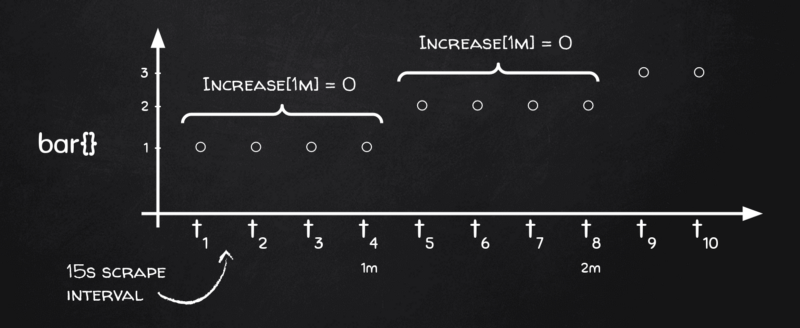
つまり、巡り合わせ次第で1分のレンジバケットがメトリクスの変化境界とちょうど重なってしまうと、そのバケット内ではメトリクスに一切変化がないことになり、これこそがrate()とその姉妹関数increase()がゼロを返す理由なのです。
なぜこれほど頻繁に、しかも安定して再現するのでしょうか。要因は2つあります。
- コードの中に「ちょうど何分」のタイミングで変化を報告する仕組み(cronジョブなど)があると、スクレイプ時にその変化が分単位の境界に紐づきやすくなります。
- 2年ほど前から、Grafanaはチャートレンジの開始位置を_step_の倍数に揃えるようにしています(これ自体は妥当な挙動です)。そのためGrafanaのstepが1分なら、バケット境界は常に分単位の境界に揃います(例:[ [18:06:00, 18:07:00], [18:07:00, 18:08:00], …])。
この2つが重なると、ちょうど分単位で値が変化するカウンタに対してrateがすべてゼロになるという、まさに「パーフェクトストーム」(いや、むしろ「パーフェクトカーム」?)状態が生まれるのです。
ただ、私の話を鵜呑みにする必要はありません。stepを1分から15秒に変えて何が起きるか確かめてみましょう(実質的に、毎スクレイプごとに直近4サンプルでrate()を計算することになります)。
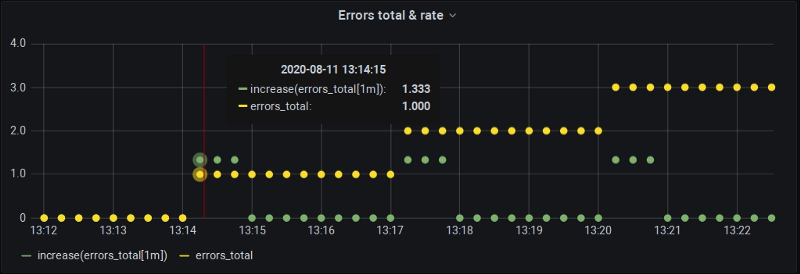 15秒ごとのincrease(errors_total[1m])
15秒ごとのincrease(errors_total[1m])
おお!ここから興味深いことが2つ読み取れます。
- 確かに黒板の図のとおりです。メトリクスは13:14:15に変化しているのに、13:15:00時点の
increase()はゼロ。これも変化が境界にぴったり乗る「完璧な」バケット整列が起きているからです。 - 13:14:15では
increase()が変化を報告しているものの……実際の値より大きいのです!具体的には1.0ではなく1.33になっています。
なぜか。もう一度黒板に戻りましょう。
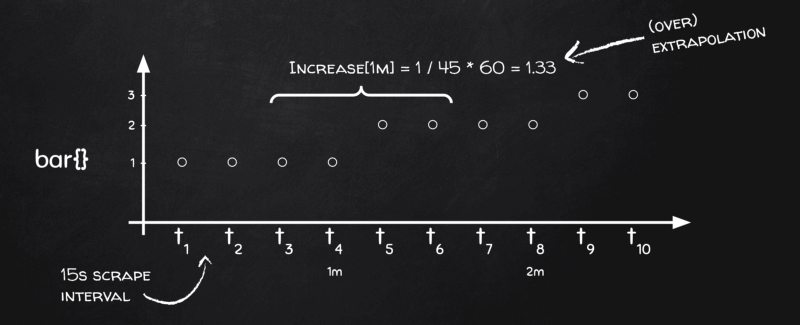 Prometheusの外挿の実演
Prometheusの外挿の実演
各バケットには4つのデータポイントがありますが、ここで必要なのは時間あたりの差分です。時間軸で見ると、4つのデータポイントは60秒ではなく45秒分しかカバーしていません!――[t₃, t₄]で15秒、[t₄, t₅]でさらに15秒、[t₅, t₆]で最後の15秒。次のバケットは[t₇, t₈]、[t₈, t₉]、[t₉, t₁₀]となり、**区間[t₆, t₇]を含むバケットはどこにも存在しないのです!**これは、Prometheusが一次計算(ゲージの平均など)と二次計算(カウンタのrateなど)の両方に同じバケット化アルゴリズムを使っているためです。
つまりPrometheusは、各バケットの実際の範囲が1スクレイプ分短い(本ケースでは60秒ではなく45秒)ことを承知しています。バケット内でメトリクスが1だけ変化したのを見ると、それは「60秒で1」ではなく「45秒で1」と解釈し、結果を1 / 45 * 60 = 1.33と外挿します。これが、increase()の値が実際の変化より大きくなる理由です。
ここまで読んで、それでも「Prometheusは監視には向いているが、課金のような厳密な数値には向かない」と納得していただけないなら、私はあなたとは銀行取引はしたくありません :)
あぁ、Prometheusに、c̶h̶a̶i̶r̶s̶バケットの隙間に落ちてしまうあの追加スクレイプも含めるよう指示できれば……。
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
平和への長い道のり
そもそもこれを直すことはできるのでしょうか。
まず手始めに、レンジとstepを自分で制御するという手があります。
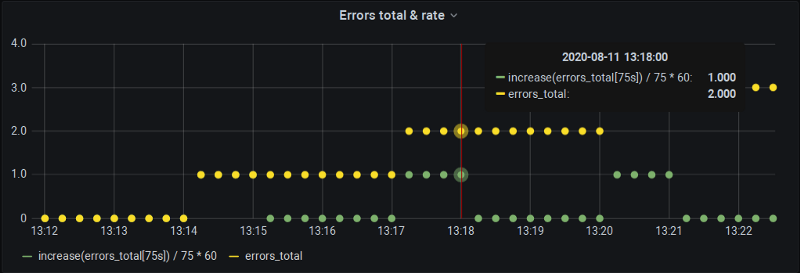 隙間を埋める
隙間を埋める
60秒間のincreaseを得るために、P8sには75秒間のincreaseを計算してもらいます(通常はバケットの間に落ちてしまうあの追加サンプルを取り込むためです)。もちろんPrometheusは結果を75秒に外挿しますが、こちらで手動で60秒に「逆外挿」してやれば、チャートは正確になり、しかも分単位の境界でデータも得られるようになります。
もちろん欠点もあります。Grafanaの自動stepと$__intervalの仕組みが使えなくなることです。ただ、少なくともGrafanaのアラート定義(どのみちintervalを手動で指定する場面)はこの方法でカバーできます。
この先の展開は?
残念ながら、まだ正式な解決策はありません。Grafanaでは$__rate_intervalを導入する作業が進行中です。素の$__intervalの代わりにこの変数を使えば、_step_の手前にあの追加スクレイプが含まれるようになり、デモで示したような分単位の境界でもデータが確実に得られるようになります。ただし、補間自体はそのまま残ります。
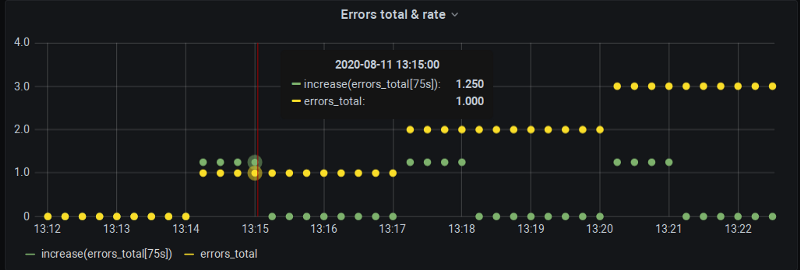 $__rate_intervalをシミュレート――分単位の値は得られているものの、外挿による誤差は依然残っている(ただし以前より小さい)。
$__rate_intervalをシミュレート――分単位の値は得られているものの、外挿による誤差は依然残っている(ただし以前より小さい)。
最近この問題には少し勢いがついてきているので、次のGrafanaリリースで利用できるようになり、ゼロばかりのrate()から解放されることを期待しましょう。
外挿の「補正」まで直したいのであれば、私の知る限り選択肢は2つあります。
xrate
これはPrometheusのフォークで、**x**`rate()`, xincrease()などの関数を追加しています。これらは($__rate_intervalと同様に)追加スクレイプを取り込んだうえで、前章の例のように逆外挿も適用してくれます。
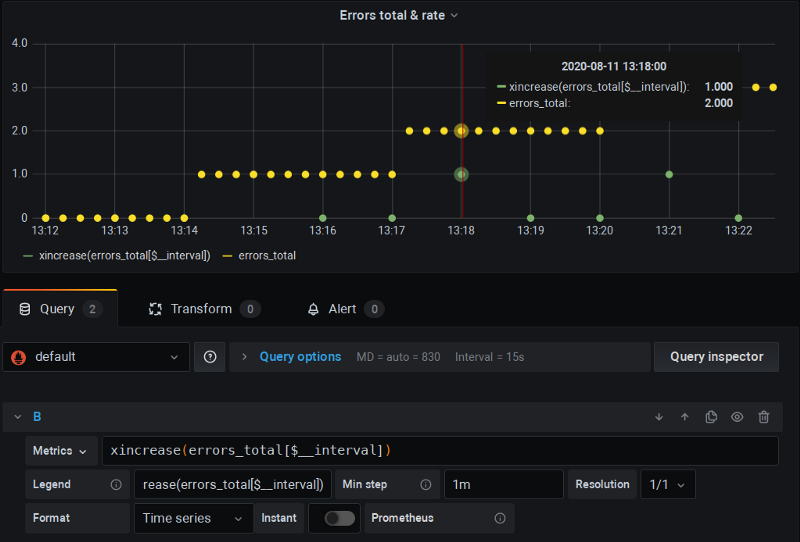 xrate P8sフォークの実演――関数名の「x」に注目
xrate P8sフォークの実演――関数名の「x」に注目
ここではこのフォーク版P8sを実行し、標準の$__intervalと「Min step」の固定をそのまま使っていますが、すべて問題なく動作しています。ゼロが並ぶこともなく、計算も正確です。
フォークではあるものの、公式のPrometheusリリースに密接に追従しており、
メンテナーのAlin Sinpalean氏がこの数年にわたって維持してくれています。本番環境で使ったことはまだありませんが、次のプロジェクトでは間違いなく試してみるつもりです。
VictoriaMetrics
こちらはPrometheus向けのリモートストレージ*プロジェクトで、追加スクレイプを取り込みつつ補間を行わない「修正版」のrate関数を実装しています。
\* つまり、複数のPrometheusインスタンスからVictoriaMetricsにデータを送信するように構成し、PromQLは後者に対して実行する形です。
こちらも普段どおりGrafanaを使っていますが、問題なく動作します。
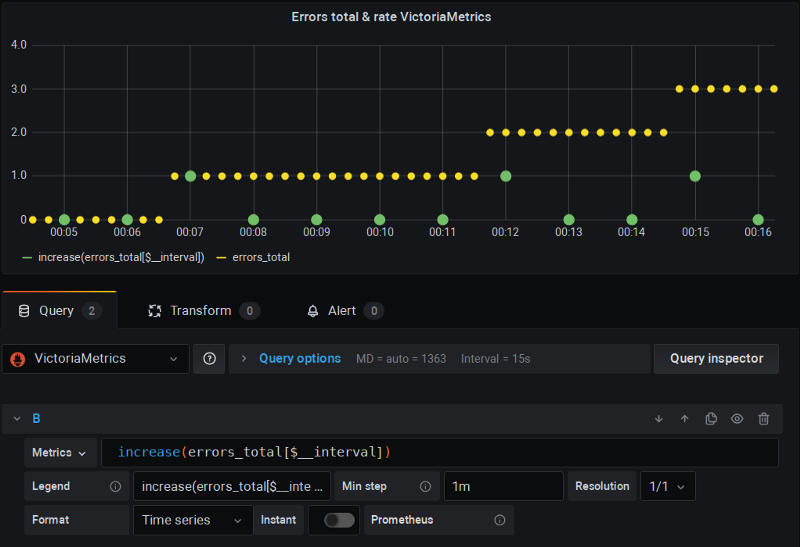 VictoriaMetricsの実演
VictoriaMetricsの実演
エピローグ
本記事が、Grafanaのチャートを正しく読み解き、その挙動と折り合いをつけるうえで役立てば幸いです。私自身、次に監視システムを構築する際は、xrateフォークとVictoriaMetricsの両方を本気で試してみるつもりです。
そもそもなぜこの問題が存在するのか、その背景に興味のある方は、本テーマに関する以下の長めの議論を参照してください。
- この種の問題とその経緯を解説した良質なブログ:リンク
- P8sユーザーグループに私が最初に投じた「これは一体……?」投稿:リンク
- rate()/increase()の外挿は有害である:リンク
- rate/increaseの改善提案:リンク
最後に付け加えると、この問題は人々を「P8sのコア開発者 vs それ以外」の陣営に分けています。P8s開発者には自分たちの主張が正しいと考える理由があるのかもしれませんが、現実にこの問題は頻繁に発生します。この事実を無視することで、彼らはAlin Sinpalean氏の言葉を借りれば「Prometheus以外のすべての人にカウンタとゲージの違いを痛感させている。すなわち『ゲージには$__intervalを、カウンタには$__fancy_intervalを使え、頑張って" 』」という状況を生んでいるだけなのです。
私は_はっきりと_立場を明らかにしておきます……あとはフォークたちに語らせましょう。あなたのデータに平和あれ。