
Um caminho longo até o rate() fazer jus ao nome
Recentemente apresentei uma série de palestras em duas partes sobre o sistema de monitoramento Prometheus. No último capítulo da segunda palestra, toquei em um tema bem espinhoso, em que mudanças nas suas métricas podem acabar varridas para debaixo do tapete. Este post é uma continuação da série, para detalhar o que pode soar como uma controvérsia.

Interior da caverna Kumistavi, conhecida como caverna de Prometeu
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Inicialize seus contadores (de erro)
Sempre que possível, inicialize seus contadores com 0, para que a métrica já comece a ser reportada de cara, com 0 como valor. E o motivo é o seguinte:
 Em contadores, o que importa são as mudanças
Em contadores, o que importa são as mudanças
Acima, temos uma métrica que não foi inicializada com zero. Quando o primeiro erro fizer com que ela passe a reportar "1" dali em diante, o Prometheus (vamos chamá-lo de "P8s" daqui pra frente, por brevidade) vai armazenar o valor numa boa. Mas, do ponto de vista dele, não houve mudança nenhuma na métrica. Ou seja, se você tem um alerta monitorando mudanças nesse contador, ele com certeza vai deixar passar o primeiro erro — e quem estiver de plantão pode acabar com uma carinha bem triste no pager.
Esse comportamento pode pegar de surpresa quem é novo no P8s, mas é tranquilo de entender. E, na verdade, é o único problema apontado neste post que eu deixaria para o desenvolvedor da aplicação resolver.
Vamos seguir para sutilezas mais avançadas.
rate() não mostra mudança nenhuma
Várias vezes me deparei com um contador que crescia devagar, possivelmente um contador de erros, em que rodar rate() retornava só zeros, mesmo com o range configurado à risca. Bem, talvez meu contador realmente não esteja crescendo, pensei comigo mesmo num exercício de autoconsolo — mas não era o caso:
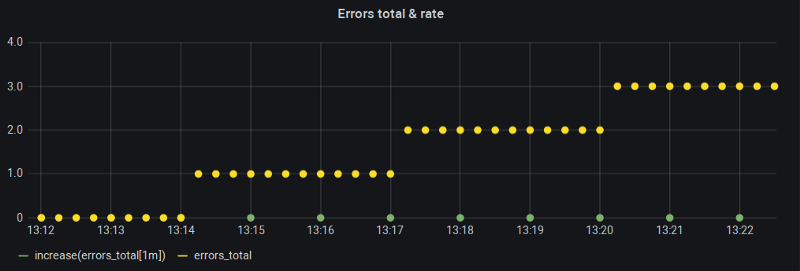 O contador sobe, mas o rate() dele não
O contador sobe, mas o rate() dele não
O "Min step" do meu Grafana (e, portanto, o $__interval) estava travado em um minuto e, com intervalo de scrape de 15s, essa é exatamente a janela de look-back recomendada para a função rate(). Então, qual é o problema?
Pra entender, precisamos voltar ao quadro-negro:
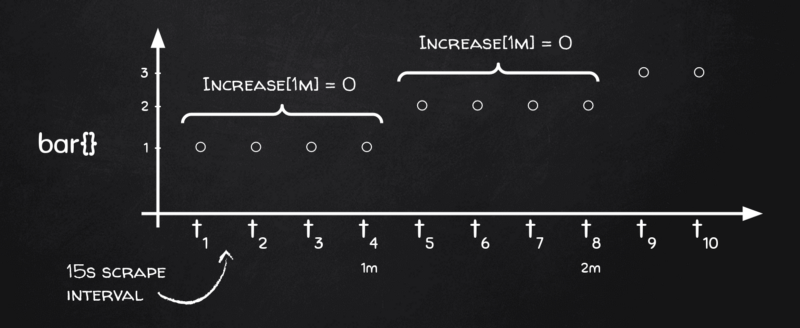
Olha só: dependendo de como os astros se alinham, se nossos buckets de range de 1 minuto caírem justamente nos limites das mudanças da métrica, não há mudança nenhuma da métrica dentro daquele bucket — e é exatamente por isso que rate(), junto com sua irmã increase(), retorna zeros.
Por que isso se repete com tanta frequência e consistência? Dois fatores:
- Se você tem algo no seu código que reporta mudanças por volta de minutos cheios (pense em cronjobs), é provável que a mudança seja atribuída ao limite do minuto cheio na hora do scrape.
- Desde dois anos atrás, o Grafana faz questão (e com razão) de alinhar o início do range do gráfico para ser múltiplo do step. Logo, se seu step no Grafana for de um minuto, os limites dos buckets sempre vão cair em um minuto cheio, ex.: [ [18:06:00, 18:07:00], [18:07:00, 18:08:00], …].
Combinados, esses fatores criam a tempestade perfeita (ou melhor, a calmaria perfeita?) em que as taxas viram tudo zero para contadores que mudam de valor exatamente em um minuto cheio.
Mas não acredite só na minha palavra — vamos mudar o step de 1 minuto para 15 segundos e ver o que acontece (basicamente calculando rate() a cada scrape sobre as últimas 4 amostras).
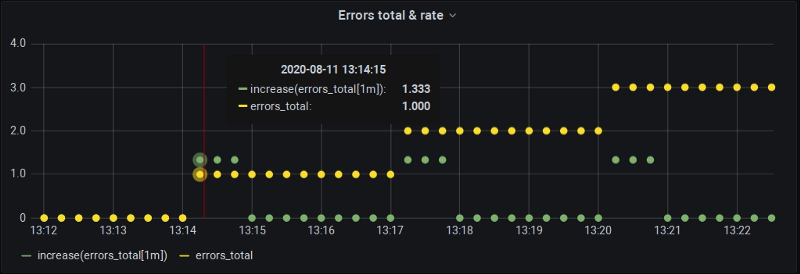 increase(errors_total[1m]) a cada 15s
increase(errors_total[1m]) a cada 15s
Olha só! Duas coisas interessantes para observar aqui:
- De fato o desenho do quadro-negro se confirma — nossa métrica muda às 13:14:15, mas o
increase()às 13:15:00 dá zero porque, de novo, temos um alinhamento "perfeito" de buckets em que as mudanças caem exatamente nos limites. - Às 13:14:15 o
increase()de fato reporta uma mudança, mas… ela é maior do que a real! A saber, 1,33 em vez de 1,0.
Por quê? De volta ao quadro-negro:
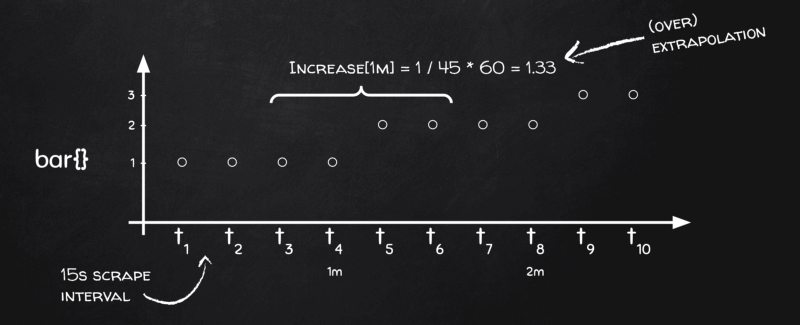 A extrapolação do Prometheus em ação
A extrapolação do Prometheus em ação
Veja só: temos quatro pontos de dados em cada bucket, mas precisamos do delta no tempo, lembra? E, em termos de tempo, nossos quatro pontos cobrem só 45 segundos, em vez de 60! — 15s para [t₃, t₄], outros 15s para [t₄, t₅] e os 15s finais para [t₅, t₆]. O próximo bucket será [t₇, t₈], [t₈, t₉] e [t₉, t₁₀], mas nenhum bucket vai conter o intervalo [t₆, t₇]! E isso porque o Prometheus aplica o mesmo algoritmo de bucketização tanto para cálculos de primeira ordem (ex.: médias em gauges) quanto para cálculos de segunda ordem (ex.: taxas em contadores).
Então, basicamente, o Prometheus entende que o range real em cada bucket é um scrape a menos, ou seja, 45 segundos em vez de 60 no nosso caso. Logo, quando ele vê a métrica mudar em 1 dentro de um bucket, na verdade é "1 em 45 segundos", e não "1 em 60 segundos". Aí ele extrapola o resultado como 1 / 45 * 60 = 1,33 — e é assim que acabamos com valores de increase() maiores do que a mudança real.
A esta altura, se você ainda não se convenceu de que o Prometheus é bom para monitoramento, mas não para dados exatos como cobrança/billing, prefiro não abrir conta no mesmo banco que você :)
Se ao menos pudéssemos dizer ao Prometheus pra incluir aquele scrape extra que cai entre as c̶a̶d̶e̶i̶r̶a̶s̶ buckets…
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
O longo caminho até a paz
Como corrigir isso, se é que dá pra corrigir?
Para começar, podemos controlar o range e o step manualmente:
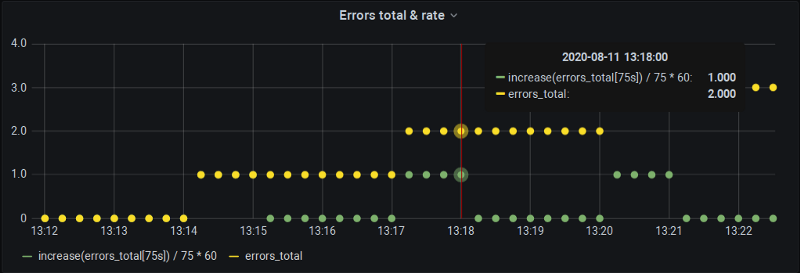 Preenchendo a lacuna
Preenchendo a lacuna
Para obter o increase em 60 segundos, pedimos ao P8s para calculá-lo em 75 segundos (incluindo aquela amostra extra que normalmente cai entre os buckets). Claro que o Prometheus vai extrapolar para 75 segundos, mas nós desfazemos a extrapolação manualmente de volta para 60 — e agora nossos gráficos ficam precisos e ainda nos entregam dados nos limites de minuto cheio.
A desvantagem, claro, é que não dá pra usar os mecanismos automáticos de step e $__interval do Grafana. Mas, pelo menos, ficamos cobertos para definições de alerta no Grafana, em que os intervalos são informados manualmente de qualquer jeito.
E agora?
Nada muito oficial ainda, infelizmente. Há um trabalho em andamento no Grafana para introduzir o $__rate_interval. Usar essa variável em vez do $__interval simples vai, sim, incluir aquele scrape extra antes do step, garantindo que tenhamos dados nos pontos de minuto cheio, conforme nossa demonstração. Só que a interpolação continua intacta:
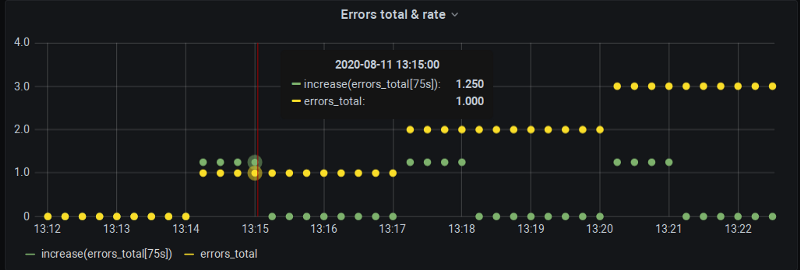 $__rate_interval simulado — o valor no minuto cheio aparece, mas ainda existe erro de extrapolação, embora menor.
$__rate_interval simulado — o valor no minuto cheio aparece, mas ainda existe erro de extrapolação, embora menor.
A questão tem ganhado tração ultimamente, então tomara que esteja disponível na próxima versão do Grafana e faça os valores zero do rate() sumirem.
Se quisermos corrigir a "correção" da extrapolação, há duas opções que conheço.
xrate
É um fork do Prometheus que adiciona as funções **x**`rate()`, xincrease() etc., que tanto incluem o scrape extra (parecido com o que o $__rate_interval vai fazer) quanto aplicam a desextrapolação como fizemos no exemplo do capítulo anterior:
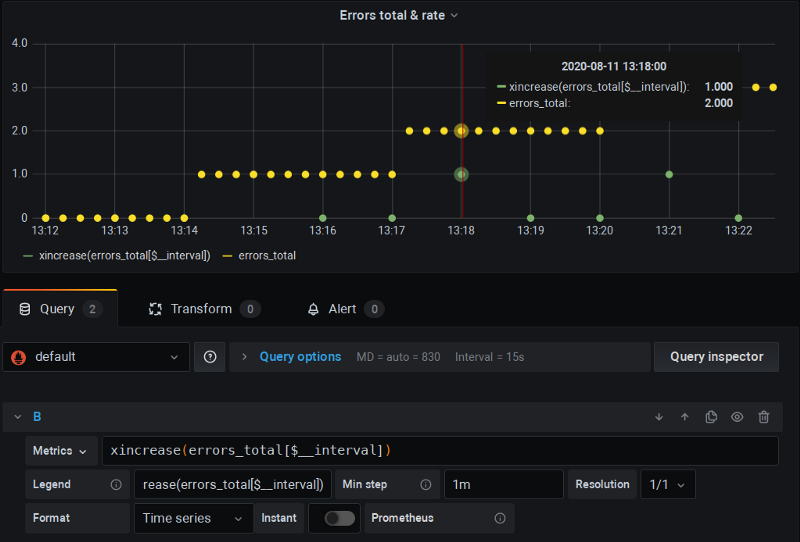 Fork xrate do P8s em ação — repare no "x" nos nomes das funções
Fork xrate do P8s em ação — repare no "x" nos nomes das funções
Aqui dá pra ver que estou rodando essa versão forkada do P8s e usando o $__interval padrão e o limite do "Min step"; e tudo simplesmente funciona — não há valores zerados, e os cálculos estão corretos.
Apesar de ser um fork, ele acompanha de perto os releases oficiais do Prometheus e
Alin Sinpalean (o mantenedor) tem mantido o projeto vivo nos últimos anos. Não usei em produção, mas com certeza vou dar uma chance no meu próximo projeto.
VictoriaMetrics
É um projeto de remote-storage* para o Prometheus que, por sua vez, implementa uma versão "corrigida" das funções de rate, que tanto acomoda o scrape extra quanto dispensa a interpolação.
\* Ou seja, você configura uma ou várias instâncias do Prometheus para enviar dados ao VictoriaMetrics e roda seu PromQL contra ele.
De novo, estou usando o Grafana como sempre, e as coisas simplesmente funcionam:
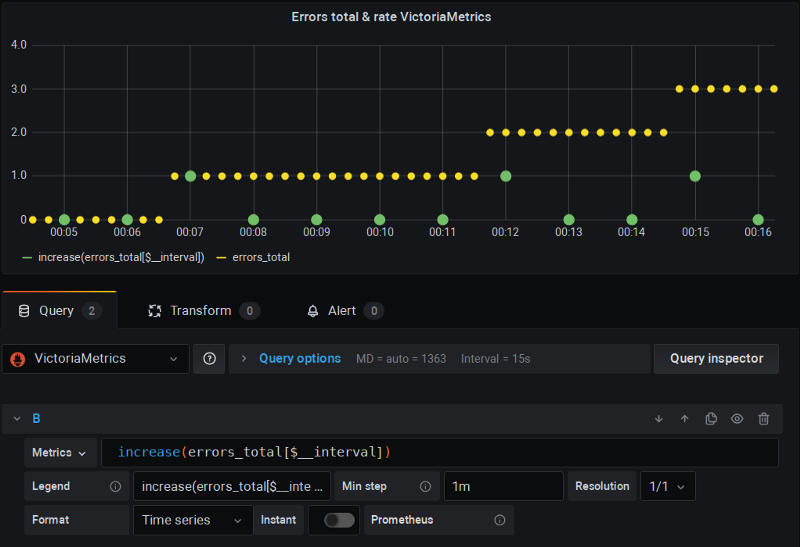 VictoriaMetrics em ação
VictoriaMetrics em ação
Epílogo
Espero que este post ajude você a entender seus gráficos no Grafana e a fazer as pazes com o jeito que as coisas funcionam por aqui. Pessoalmente, eu daria uma chance séria tanto ao fork xrate quanto ao VictoriaMetrics na próxima vez que for subir um sistema de monitoramento.
Se você quiser entender em detalhes por que esse problema existe, aqui vão algumas discussões bem longas sobre o assunto:
- Um excelente blog que explica esse tipo de problema e sua evolução: link
- Meu post original "Mas o que…?" no grupo de usuários do P8s: link
- Extrapolação de rate()/increase() considerada nociva: link
- Proposta para melhorar rate/increase: link
Para fechar, deixa eu acrescentar que essa questão divide as pessoas em dois campos: "desenvolvedores core do P8s vs. o resto". E, embora os desenvolvedores do P8s possam ter razões para dizer que estão certos nessa, o problema acontece na vida real e com bastante frequência. Ao ignorar esse fato, eles só conseguem, citando Alin Sinpalean, "fazer todo mundo, exceto o Prometheus, ficar dolorosamente ciente da diferença entre um counter e um gauge: "você precisa usar $__interval com gauges e $__fancy_interval com counters, boa sorte"".
Eu estou tomando partido aqui... Que os forks falem por mim. Paz nos seus dados.