
Il lungo cammino per far sì che rate() mantenga ciò che promette
Di recente ho tenuto una serie di talk in due parti sul sistema di monitoraggio Prometheus. Nell'ultimo capitolo del secondo intervento ho affrontato un tema piuttosto contorto: quello in cui le variazioni delle metriche rischiano di finire nascoste sotto al tappeto. Questo articolo è il seguito naturale di quei talk e serve ad approfondire ciò che a prima vista può sembrare una piccola controversia.

Interno della grotta di Kumistavi, nota come grotta di Prometeo
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Inizializzate i contatori (di errore)
Quando possibile, inizializzate i contatori a 0, così la metrica inizierà subito a essere riportata, di nuovo, con valore 0. Ecco perché:
 Con i contatori, ci interessano solo le variazioni
Con i contatori, ci interessano solo le variazioni
Sopra abbiamo una metrica che non è stata inizializzata a zero. Quando il primo errore la porterà a riportare "1" da quel momento in poi, Prometheus (d'ora in avanti lo chiameremo "P8s" per brevità) lo memorizzerà senza problemi. Dal suo punto di vista, però, non c'è stata alcuna variazione nella metrica. Quindi, se avete un alert che osserva i cambiamenti su quel contatore, mancherà sicuramente il primo errore e chi è di turno con il pager potrebbe ritrovarsi con una faccina molto triste.
Il concetto può sorprendere chi è alle prime armi con P8s, ma è facile da assimilare. Ed è in realtà l'unico problema sollevato in questo post che lascerei risolvere allo sviluppatore dell'applicazione.
Passiamo ora alle sottigliezze più avanzate.
rate() non mostra alcuna variazione
Mi è capitato spesso di avere un contatore in lenta crescita, magari un contatore di errori, sul quale eseguendo rate() ottenevo solo zeri nonostante avessi impostato il range come da manuale. "Beh, magari il mio contatore non sta davvero crescendo", mi sono detto in un esercizio di auto-consolazione, ma non era così:
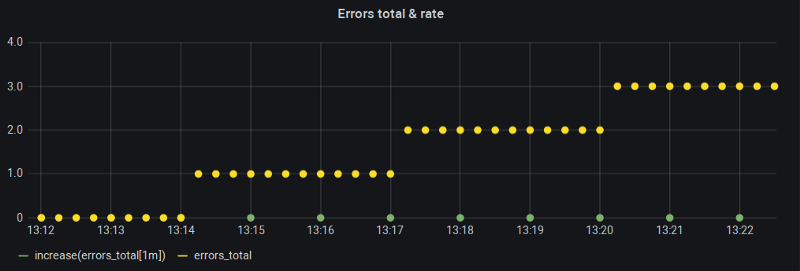 Il contatore cresce, ma il suo rate() no
Il contatore cresce, ma il suo rate() no
Il "Min step" di Grafana (e quindi $__interval) era fissato a un minuto e con un intervallo di scrape di 15s coincideva esattamente con la finestra di look-back consigliata per la funzione rate(). Allora cosa non quadra?
Per capirlo dobbiamo tornare alla lavagna:
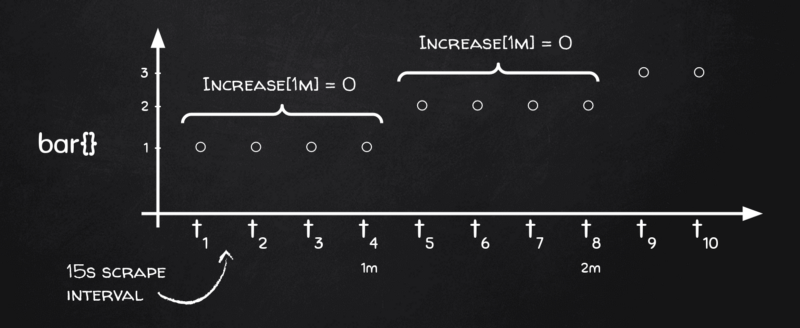
Vedete, a seconda di come si allineano gli astri, se i nostri bucket di range da 1 minuto cadono proprio sui confini in cui la metrica varia, all'interno di quel bucket non risulta alcuna variazione: ed è esattamente per questo che rate(), insieme alla sorella increase(), restituisce zero.
Perché capita così spesso e con tanta regolarità? Per due fattori:
- Se nel codice avete qualcosa che riporta variazioni in corrispondenza del minuto pieno (pensate ai cronjob), è probabile che, durante lo scraping, la variazione venga attribuita proprio al confine del minuto.
- Da due anni a questa parte, Grafana si preoccupa (giustamente) di allineare l'inizio del range del grafico a un multiplo dello step: quindi se in Grafana lo step è di un minuto, i confini dei bucket cadranno sempre sul minuto pieno, ad esempio [ [18:06:00, 18:07:00], [18:07:00, 18:08:00], …].
Combinati, questi fattori creano una tempesta perfetta (o forse una calma perfetta?) in cui i tassi risultano tutti pari a zero per i contatori che variano in corrispondenza del minuto pieno.
Ma non fidatevi sulla parola: cambiamo lo step da 1 minuto a 15 secondi e vediamo cosa succede (in pratica calcoliamo rate() a ogni scrape sugli ultimi 4 campioni).
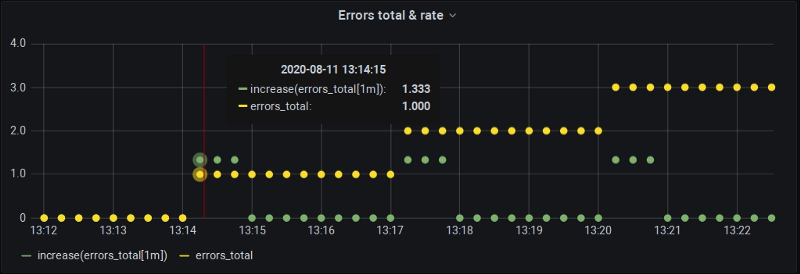 increase(errors_total[1m]) ogni 15s
increase(errors_total[1m]) ogni 15s
Aha! Ci sono due cose interessanti da osservare:
- Il disegno alla lavagna è confermato: la metrica varia alle 13:14:15, ma
increase()alle 13:15:00 vale zero perché, ancora una volta, abbiamo un allineamento "perfetto" dei bucket, con le variazioni che cadono tutte sui confini. - Alle 13:14:15
increase()riporta sì una variazione, ma… più grande di quella reale! Per la precisione, 1,33 invece di 1,0.
Perché? Torniamo alla lavagna:
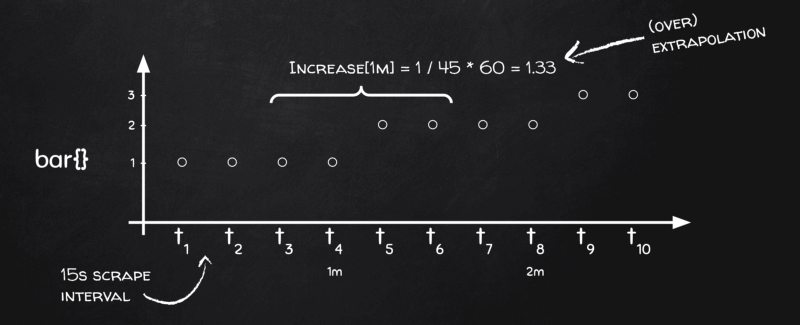 L'estrapolazione di Prometheus all'opera
L'estrapolazione di Prometheus all'opera
Vedete, abbiamo quattro punti dati in ogni bucket, ma ci serve il delta nel tempo, ricordate, e dal punto di vista temporale i nostri quattro punti coprono solo 45 secondi invece di 60! — 15s per [t₃, t₄], altri 15s per [t₄, t₅] e gli ultimi 15s per [t₅, t₆]. Il bucket successivo sarà [t₇, t₈], [t₈, t₉] e [t₉, t₁₀], ma nessun bucket conterrà l'intervallo [t₆, t₇]! Questo perché Prometheus applica lo stesso algoritmo di bucketing sia ai calcoli di primo ordine (es. medie sui gauge) sia a quelli di secondo ordine (es. tassi sui contatori).
In sostanza, Prometheus sa che il range effettivo in ogni bucket è di uno scrape in meno, cioè 45 secondi invece di 60 nel nostro caso, perciò quando vede la metrica cambiare di 1 in un bucket, in realtà si tratta di "1 in 45 secondi", non di "1 in 60 secondi": estrapola allora il risultato come 1 / 45 * 60 = 1,33, ed è così che ci ritroviamo con valori di increase() superiori alla variazione effettiva.
A questo punto, se non siete ancora convinti che Prometheus sia adatto al monitoraggio ma non a dati esatti come quelli di fatturazione, preferirei non avere conti correnti in comune con voi :)
Se solo potessimo dire a Prometheus di includere quello scrape extra che cade tra le s̶e̶d̶i̶e̶ buckets…
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
La lunga strada verso la pace
Come si risolve, ammesso che si possa?
Per cominciare, possiamo gestire range e step manualmente:
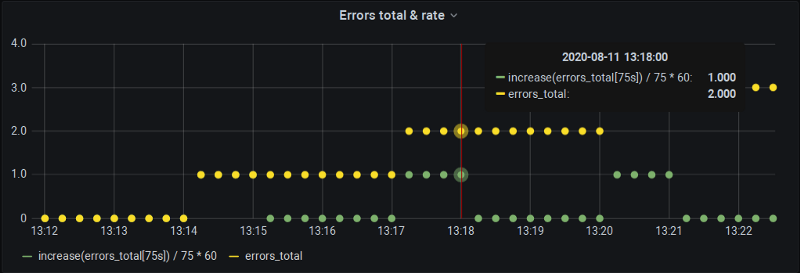 Colmare il vuoto
Colmare il vuoto
Per ottenere l'incremento sui 60 secondi, chiediamo a P8s di calcolarlo su 75 secondi (con quel campione extra che di solito cade tra i bucket). Ovviamente Prometheus lo estrapolerà a 75 secondi, ma noi de-estrapoliamo manualmente a 60: ora i grafici sono precisi e ci forniscono anche i dati sui confini del minuto pieno.
Lo svantaggio, ovviamente, è che non possiamo più usare i meccanismi automatici di step e $__interval di Grafana. Ma almeno siamo coperti per le definizioni degli alert in Grafana, dove gli intervalli vengono comunque inseriti a mano.
E adesso?
Niente di troppo ufficiale, purtroppo. È in corso un lavoro in Grafana per introdurre $__rate_interval. Usare questa variabile al posto del semplice $__interval includerà davvero quello scrape extra dietro lo step e ci garantirà di ottenere dati, ad esempio, sui punti del minuto pieno come nella nostra dimostrazione. L'interpolazione, però, resterà invariata:
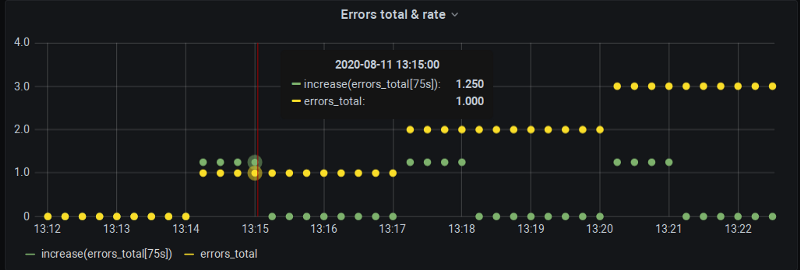 $__rate_interval simulato — il valore al minuto pieno c'è, ma rimane un errore di estrapolazione, anche se più contenuto.
$__rate_interval simulato — il valore al minuto pieno c'è, ma rimane un errore di estrapolazione, anche se più contenuto.
Ultimamente la questione sta guadagnando un po' di attenzione, quindi si spera che la novità arrivi nella prossima release di Grafana, facendo sparire i valori zero di rate().
Se invece vogliamo correggere la "correzione" da estrapolazione, le opzioni che conosco sono due.
xrate
Si tratta di un fork di Prometheus che aggiunge le funzioni **x**`rate()`, xincrease(), ecc., le quali aggiungono uno scrape extra (in modo simile a quanto farà $__rate_interval) e applicano anche la de-estrapolazione, come abbiamo fatto nell'esempio del capitolo precedente:
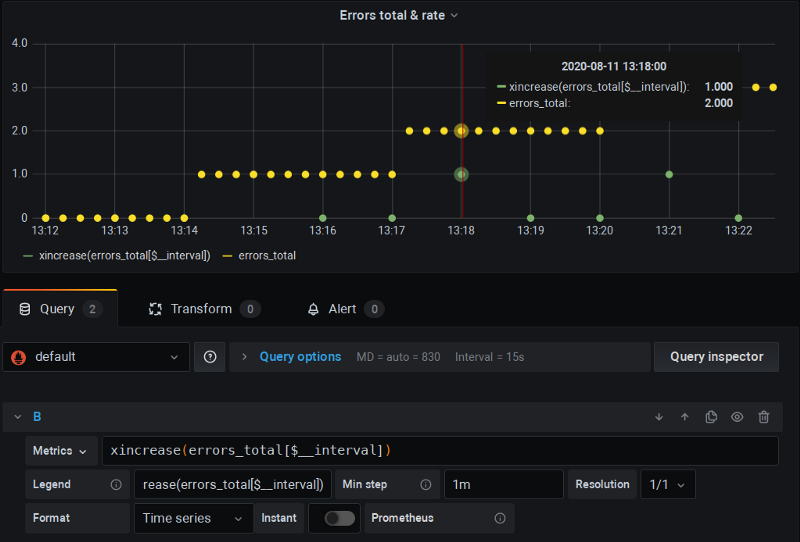 Il fork xrate di P8s all'opera: notate la "x" nei nomi delle funzioni
Il fork xrate di P8s all'opera: notate la "x" nei nomi delle funzioni
Qui potete vedere che sto usando questa versione fork di P8s con il consueto $__interval e con il clamping sul "Min step"; tutto fila liscio: niente più zeri ovunque e i calcoli sono corretti.
Pur essendo un fork, segue da vicino le release ufficiali di Prometheus e
Alin Sinpalean (il maintainer) lo tiene a galla da un paio d'anni. Non l'ho usato in produzione, ma di sicuro lo proverò sul prossimo progetto.
VictoriaMetrics
Si tratta di un progetto di remote-storage* per Prometheus che a sua volta implementa una versione "corretta" delle funzioni rate, gestendo sia lo scrape extra sia l'assenza di interpolazione.
\* Cioè configurate, eventualmente, più istanze di Prometheus per inviare dati a VictoriaMetrics e poi lanciate le vostre query PromQL su quest'ultimo.
Anche qui sto usando Grafana come al solito, e le cose funzionano e basta:
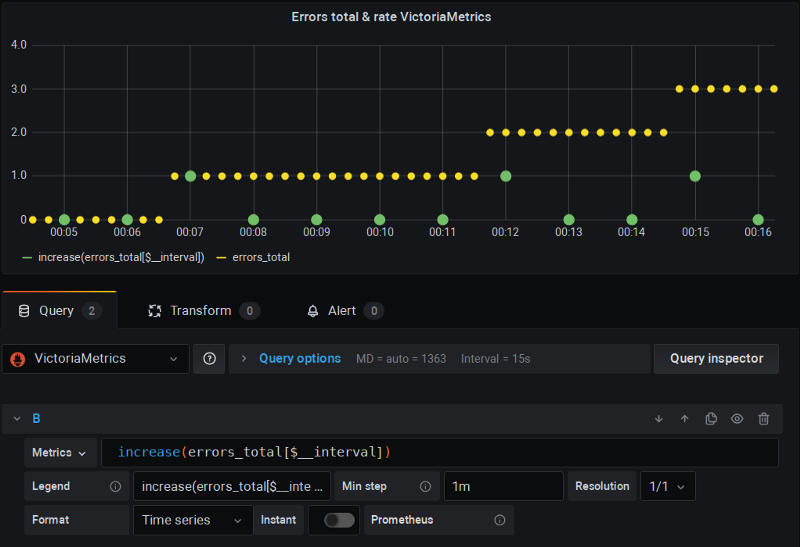 VictoriaMetrics all'opera
VictoriaMetrics all'opera
Epilogo
Spero che questo post vi aiuti a dare un senso ai vostri grafici Grafana e a fare pace con il modo in cui le cose funzionano qui dentro. Personalmente, la prossima volta che dovrò mettere in piedi un sistema di monitoraggio darei una chance seria sia al fork xrate sia a VictoriaMetrics.
Se vi interessano i dettagli sul perché questo problema esista, ecco alcune discussioni piuttosto lunghe sull'argomento:
- Un ottimo blog che spiega questo tipo di problemi e la loro evoluzione: link
- Il mio post originale "Ma cosa…?" nel gruppo utenti P8s: link
- L'estrapolazione di rate()/increase() considerata dannosa: link
- Proposta di miglioramento per rate/increase: link
Per chiudere, lasciatemi aggiungere che la questione divide le persone in due fazioni: "sviluppatori core di P8s contro tutti gli altri". E benché gli sviluppatori di P8s possano avere le loro buone ragioni per dirsi nel giusto, il problema si presenta nella vita reale e con una certa frequenza. Ignorando questo fatto, ottengono solo, per citare Alin Sinpalean, di "costringere tutti tranne Prometheus a diventare dolorosamente consapevoli della differenza tra un counter e un gauge: "devi usare $__interval con i gauge e $__fancy_interval con i counter, buona fortuna"".
Sì, sto prendendo posizione qui... Lasciamo parlare i fork. Pace sui vostri dati.