
Le long chemin pour que rate() tienne enfin ses promesses
J'ai récemment donné une série de conférences en deux parties sur le système de monitoring Prometheus. Dans le dernier chapitre de la seconde partie, j'ai abordé un sujet plutôt épineux : celui où les variations de vos métriques peuvent passer purement et simplement à la trappe. Ce billet prolonge la série pour approfondir ce qui peut sembler relever de la controverse.

Intérieur de la grotte de Kumistavi, dite grotte de Prométhée
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Initialisez vos compteurs (d'erreurs)
Quand c'est possible, initialisez vos compteurs à 0, afin que la métrique soit remontée immédiatement avec, là encore, 0 comme valeur. Voici pourquoi :
 Avec les compteurs, seuls les changements nous intéressent
Avec les compteurs, seuls les changements nous intéressent
Ci-dessus, nous avons une métrique qui n'a pas été initialisée à zéro. Lorsque la première erreur survient et fait remonter 1 à partir de cet instant, Prometheus (que nous appellerons désormais simplement P8s pour faire court) la stockera sans problème. Mais de son point de vue, il n'y a eu aucun changement dans la métrique. Donc si vous avez une alerte qui surveille les variations de ce compteur, elle va forcément manquer la première erreur et la personne d'astreinte risque vite de faire grise mine.
Ce comportement peut surprendre un nouvel utilisateur de P8s, mais il reste facile à appréhender. C'est d'ailleurs le seul problème évoqué dans ce billet que je laisserai au développeur de l'application le soin de régler.
Passons maintenant aux subtilités plus avancées.
rate() ne remonte aucun changement
Il m'est souvent arrivé d'avoir un compteur qui augmentait lentement, parfois un compteur d'erreurs, où l'exécution de rate() ne renvoyait que des zéros, alors même que ma plage était paramétrée selon les règles de l'art. Bon, peut-être que mon compteur n'augmente pas vraiment, me suis-je dit pour me rassurer — mais ce n'était pas le cas :
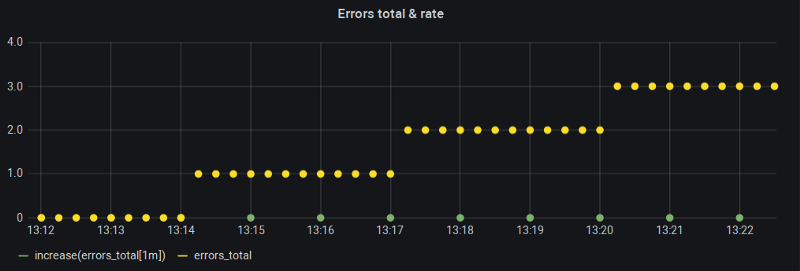 Le compteur augmente, mais pas son rate()
Le compteur augmente, mais pas son rate()
Mon Min step Grafana (et donc $__interval) était fixé à une minute, et avec un intervalle de scrape de 15 s, c'est exactement la fenêtre de rétroaction recommandée pour la fonction rate(). Alors qu'est-ce qui cloche ?
Pour comprendre, il faut revenir au tableau noir :
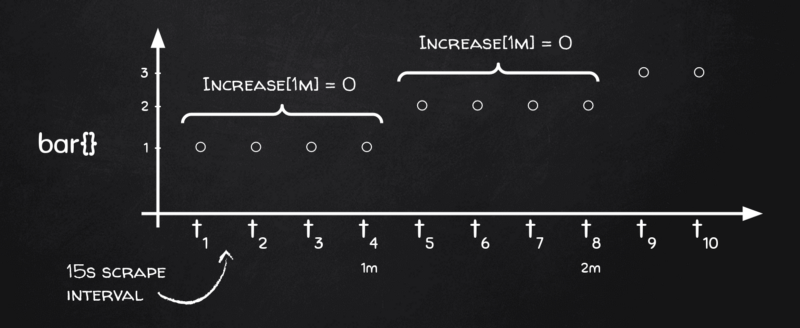
Vous voyez, selon l'alignement des astres, si nos buckets d'une minute tombent pile sur les frontières de changement de la métrique, il n'y a tout simplement aucun changement à l'intérieur du bucket — et c'est précisément pour cela que rate(), ainsi que sa cousine increase(), renvoient des zéros.
Pourquoi cela se reproduit-il aussi souvent et de manière aussi régulière ? Deux facteurs :
- Si quelque chose dans votre code remonte des changements aux alentours de la minute pleine (pensez aux cronjobs), il y a fort à parier que le changement sera attribué à la frontière de la minute pleine lors du scrape.
- Depuis deux ans, Grafana s'assure (à juste titre) d'aligner le début de la plage du graphique sur un multiple du step ; donc si votre step dans Grafana est d'une minute, les frontières de buckets tomberont toujours sur une minute pleine, par exemple [ [18:06:00, 18:07:00], [18:07:00, 18:08:00], …].
Combinés, ces deux éléments créent les conditions d'une tempête parfaite (ou plutôt d'un calme parfait ?) où les rates deviennent tous nuls pour les compteurs qui changent de valeur sur une frontière de minute pleine.
Mais ne me croyez pas sur parole — passons le step de 1 minute à 15 secondes et voyons ce qui se passe (en gros, on calcule rate() à chaque scrape sur les 4 derniers échantillons).
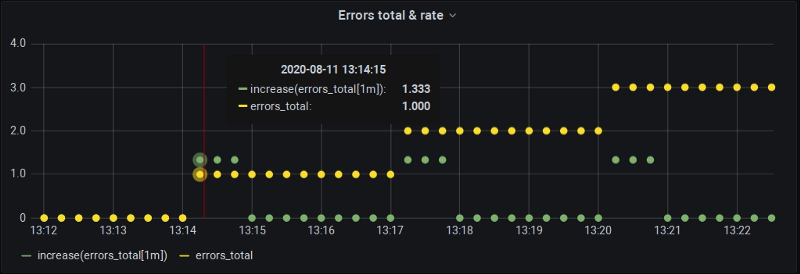 increase(errors_total[1m]) toutes les 15 s
increase(errors_total[1m]) toutes les 15 s
Aha ! Deux choses intéressantes à observer ici :
- Le dessin au tableau noir se vérifie : notre métrique change à 13:14:15, mais
increase()à 13:15:00 vaut zéro car, encore une fois, on a un alignement parfait des buckets, où les changements tombent tous sur les frontières. - À 13:14:15,
increase()remonte bien un changement, mais… il est plus grand que la variation réelle ! 1,33 au lieu de 1,0.
Pourquoi ? Retour au tableau noir :
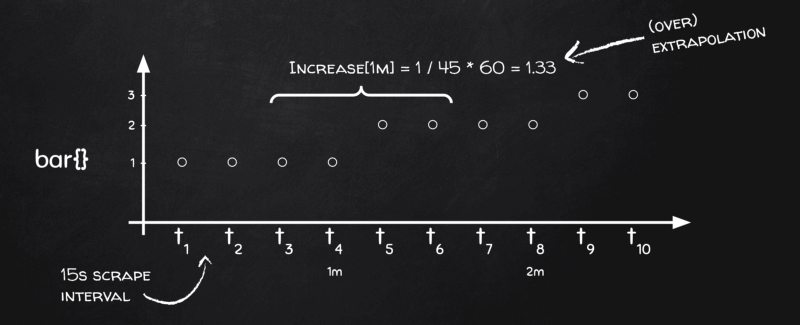 L'extrapolation de Prometheus en action
L'extrapolation de Prometheus en action
Voyez-vous, on a quatre points de données par bucket, mais il nous faut un delta dans le temps, rappelez-vous, et côté temps, nos quatre points ne couvrent que 45 secondes au lieu de 60 ! — 15 s pour [t₃, t₄], 15 s de plus pour [t₄, t₅] et les 15 s finales pour [t₅, t₆]. Le bucket suivant sera [t₇, t₈], [t₈, t₉] et [t₉, t₁₀], mais aucun bucket ne contiendra l'intervalle [t₆, t₇] ! Et c'est parce que Prometheus applique le même algorithme de bucketing aussi bien aux calculs du premier ordre (par ex. les moyennes sur des gauges) qu'à ceux du second ordre (par ex. les rates sur des compteurs).
En somme, Prometheus considère que la plage réelle dans chaque bucket fait un scrape de moins, soit 45 secondes au lieu de 60 dans notre cas. Du coup, quand il voit la métrique varier de 1 dans un bucket, c'est en réalité 1 sur 45 secondes et non 1 sur 60 secondes ; il extrapole donc le résultat à 1 / 45 * 60 = 1,33, et c'est ainsi qu'on se retrouve avec des valeurs increase() supérieures au changement réel.
À ce stade, si vous n'êtes toujours pas convaincu que Prometheus est bon pour le monitoring mais inadapté à des données exactes comme la facturation, je préfère ne pas faire de banque avec vous :)
Si seulement on pouvait dire à Prometheus d'inclure ce scrape supplémentaire qui tombe entre les c̶h̶a̶i̶s̶e̶s̶ buckets…
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Le long chemin vers la paix
Comment corriger cela, si tant est que ce soit possible ?
Pour commencer, on peut piloter soi-même la plage et le step :
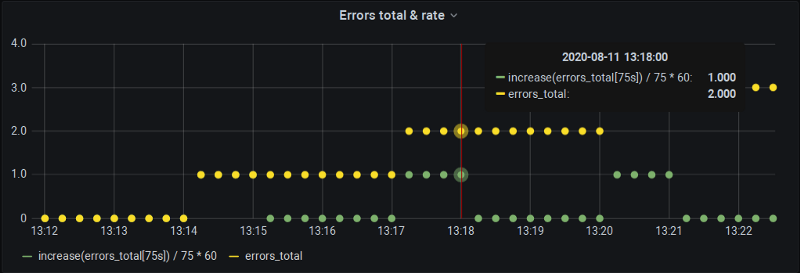 Combler l'écart
Combler l'écart
Pour obtenir l'augmentation sur 60 secondes, on demande à P8s d'en calculer une sur 75 secondes (avec cet échantillon supplémentaire qui tombe habituellement entre les buckets). Bien sûr, Prometheus va l'extrapoler sur 75 secondes, mais on dé-extrapole manuellement vers 60, et nos graphiques sont à la fois précis et fournissent les données aux frontières de minute pleine.
L'inconvénient, évidemment, c'est qu'on ne peut plus utiliser les mécanismes automatiques de step et $__interval de Grafana. Mais au moins, c'est viable pour les définitions d'alertes dans Grafana, où les intervalles sont de toute façon saisis manuellement.
Et après ?
Rien d'officiel pour l'instant, malheureusement. Un chantier est en cours dans Grafana pour introduire $__rate_interval. Utiliser cette variable à la place de $__interval permettra effectivement d'inclure le scrape supplémentaire derrière le step, afin de bien obtenir des données sur, par exemple, les minutes pleines, comme dans notre démonstration. En revanche, l'interpolation reste inchangée :
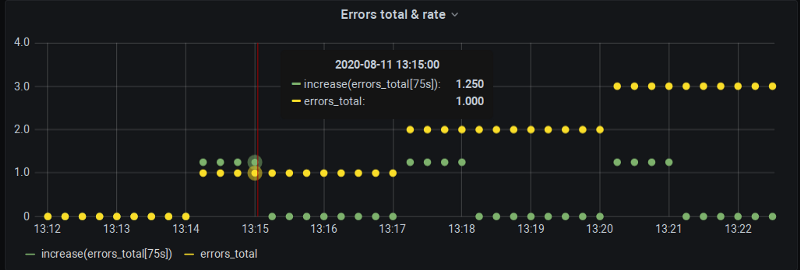 $__rate_interval simulé — la valeur sur la minute pleine est bien là, mais l'erreur d'extrapolation persiste, quoique réduite.
$__rate_interval simulé — la valeur sur la minute pleine est bien là, mais l'erreur d'extrapolation persiste, quoique réduite.
Le sujet a pris de l'élan ces derniers temps, on peut donc espérer que ce sera disponible dans la prochaine version de Grafana pour faire disparaître les valeurs nulles de rate().
Pour corriger la correction par extrapolation, je connais deux options.
xrate
Il s'agit d'un fork de Prometheus qui ajoute les fonctions **x**`rate()`, xincrease(), etc., qui ajoutent un scrape supplémentaire (à la manière de $__rate_interval) tout en appliquant la dé-extrapolation, comme dans l'exemple du chapitre précédent :
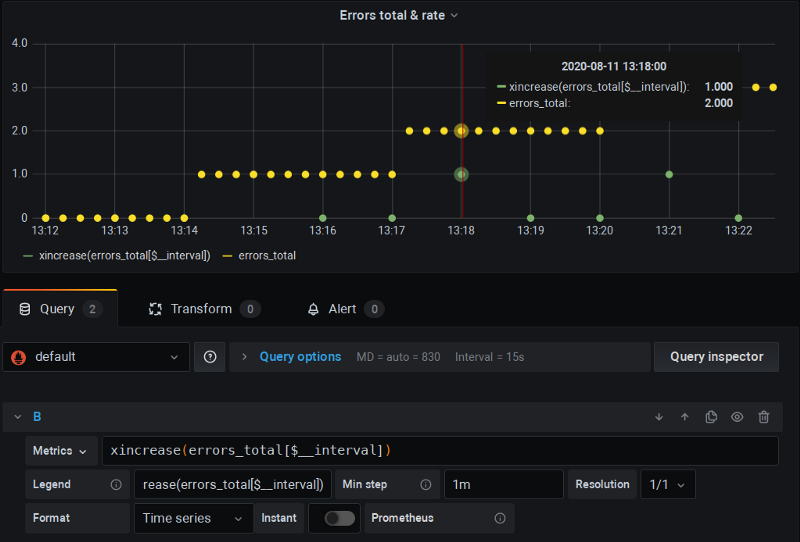 Le fork xrate de P8s en action — remarquez le x dans les noms de fonctions
Le fork xrate de P8s en action — remarquez le x dans les noms de fonctions
Vous voyez ici que je fais tourner cette version forkée de P8s avec $__interval standard et le clamping Min step ; et tout fonctionne — plus de séries entièrement nulles, et les calculs sont corrects.
Bien que ce soit un fork, il suit de près les versions officielles de Prometheus, et
Alin Sinpalean (le mainteneur) le maintient à flot depuis maintenant deux ans. Je ne l'ai pas utilisé en production, mais je compte clairement le tester sur mon prochain projet.
VictoriaMetrics
C'est un projet de stockage distant* pour Prometheus qui, de son côté, implémente une version corrigée des fonctions de rate, qui prend en compte le scrape supplémentaire et n'effectue pas d'interpolation.
\* C'est-à-dire qu'on configure plusieurs instances de Prometheus, potentiellement, pour envoyer leurs données vers VictoriaMetrics, puis on exécute son PromQL contre ce dernier.
Là encore, j'utilise Grafana comme d'habitude, et tout fonctionne sans accroc :
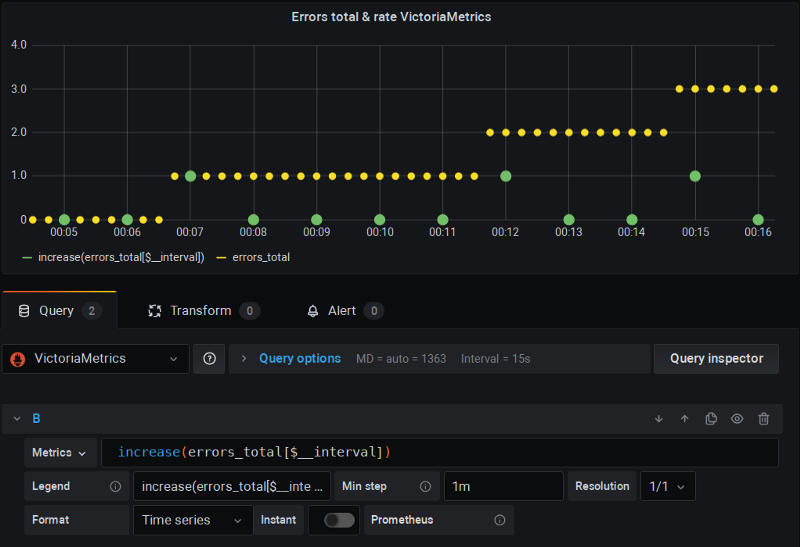 VictoriaMetrics en action
VictoriaMetrics en action
Épilogue
J'espère que ce billet vous aidera à donner du sens à vos graphiques Grafana et à faire la paix avec leur fonctionnement. Personnellement, je donnerais une vraie chance à la fois au fork xrate et à VictoriaMetrics lors de mon prochain déploiement d'un système de monitoring.
Si vous voulez creuser les détails de l'origine de ce problème, voici quelques discussions plutôt longues sur le sujet :
- Un excellent blog qui explique ce type de problèmes et leur évolution : lien
- Mon post original Mais qu'est-ce que… ?! dans le groupe utilisateurs P8s : lien
- L'extrapolation de rate()/increase() considérée comme nuisible : lien
- Proposition d'amélioration de rate/increase : lien
Pour conclure, j'ajouterai que ce sujet divise les esprits en deux camps : les développeurs core de P8s d'un côté, et le reste du monde de l'autre. Et même si les développeurs de P8s peuvent avoir leurs propres raisons de penser qu'ils ont raison sur ce point, le problème se manifeste bel et bien dans la vraie vie, et plutôt souvent. En l'ignorant, ils ne font, pour citer Alin Sinpalean, que rendre tout le monde, sauf Prometheus, douloureusement conscient de la différence entre un counter et une gauge : "il faut utiliser $__interval avec les gauges et $__fancy_interval avec les counters, bonne chance".
Je prends parti ici… Que les forks parlent. Paix sur vos données.