
El largo camino para que rate() haga lo que promete
Hace poco di una serie de dos charlas sobre el sistema de monitoreo Prometheus. En el último capítulo de la segunda charla toqué un tema bastante enredado: cómo los cambios en tus métricas pueden terminar barridos bajo la alfombra. Este blog es la continuación de esa serie y profundiza en lo que podría parecer una controversia.

Interior de la cueva de Kumistavi, también conocida como la cueva de Prometheus
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Inicializa tus contadores (de errores)
Cuando sea posible, inicializa tus contadores en 0, así la métrica empieza a reportarse de inmediato con —de nuevo— 0 como valor. Aquí va el porqué:
 Con los contadores, lo único que importa son los cambios
Con los contadores, lo único que importa son los cambios
Arriba tenemos una métrica que no se inicializó en cero. Cuando el primer error consigue reportar "1" de ahí en adelante, Prometheus (de aquí en más le diremos "P8s" por brevedad) lo guardará tan tranquilo. Pero desde su punto de vista, no hubo ningún cambio en la métrica. Por lo tanto, si tienes una alerta vigilando los cambios en ese contador, seguramente se le va a pasar el primer error y a quien tenga el pager le va a tocar una carita muy triste.
Esto puede sorprender a quien recién llega a P8s, pero se entiende fácil. Y, de hecho, es el único problema señalado en este post que dejaría en manos del desarrollador de la app.
Pasemos a las sutilezas avanzadas.
rate() no muestra ningún cambio
Más de una vez tuve un contador que crecía lentamente, posiblemente un contador de errores, donde al ejecutar rate() me devolvía puros ceros, a pesar de tener el rango configurado como manda el manual. Bueno, capaz mi contador no está creciendo de verdad, pensé como ejercicio de autoconsuelo, pero no era el caso:
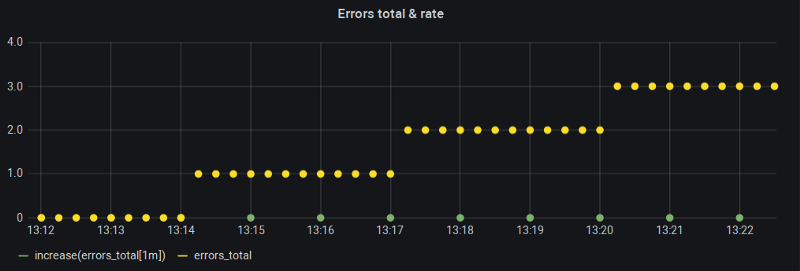 El contador crece, pero su rate() no
El contador crece, pero su rate() no
Mi "Min step" en Grafana (y por ende $__interval) estaba fijado en un minuto y, con un intervalo de scrape de 15s, esa es justamente la ventana recomendada para la función rate(). Entonces, ¿qué está fallando aquí?
Para entenderlo hay que volver al pizarrón:
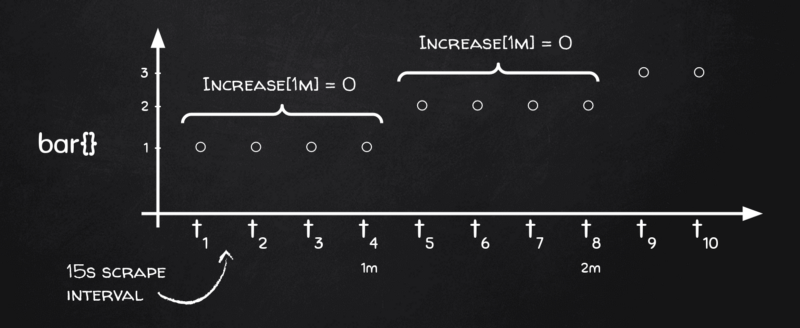
Mira, dependiendo de cómo se alineen los astros, si nuestros buckets de rango de 1 minuto caen justo en los límites donde la métrica cambia, no hay ningún cambio dentro de ese bucket, y por eso rate(), junto con su hermana increase(), devuelve ceros.
¿Por qué se reproduce tan seguido y de forma tan consistente? Por dos factores:
- Si tienes algo en tu código que reporta cambios cerca de un minuto exacto (piensa en cronjobs), es probable que ese cambio quede asociado al límite del minuto exacto al hacer scrape.
- Desde hace dos años, Grafana se asegura (y con razón) de alinear el inicio del rango del gráfico para que sea múltiplo del step, así que si tu step en Grafana es de un minuto, los límites de los buckets siempre caerán en un minuto exacto, por ejemplo [ [18:06:00, 18:07:00], [18:07:00, 18:08:00], …].
Combinados, ambos factores generan una tormenta perfecta (¿o más bien una calma perfecta?) en la que las tasas terminan siendo todas cero para los contadores que cambian su valor justo en un límite de minuto exacto.
Pero no me creas a mí: cambiemos el step de 1 minuto a 15 segundos y veamos qué pasa (básicamente calculando rate() en cada scrape sobre las últimas 4 muestras).
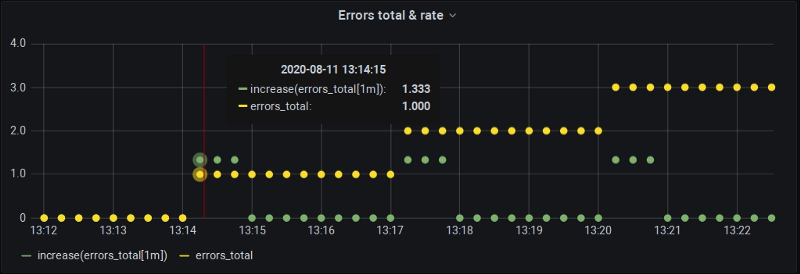 increase(errors_total[1m]) cada 15s
increase(errors_total[1m]) cada 15s
¡Ajá! Hay dos cosas interesantes que podemos observar aquí:
- El dibujo del pizarrón se confirma: nuestra métrica cambia a las 13:14:15, pero
increase()a las 13:15:00 da cero porque, otra vez, tenemos una alineación "perfecta" de los buckets, donde los cambios caen justo en los límites. - A las 13:14:15
increase()sí reporta un cambio, pero… ¡es mayor que el real! Concretamente, 1.33 en lugar de 1.0.
¿Por qué? De vuelta al pizarrón:
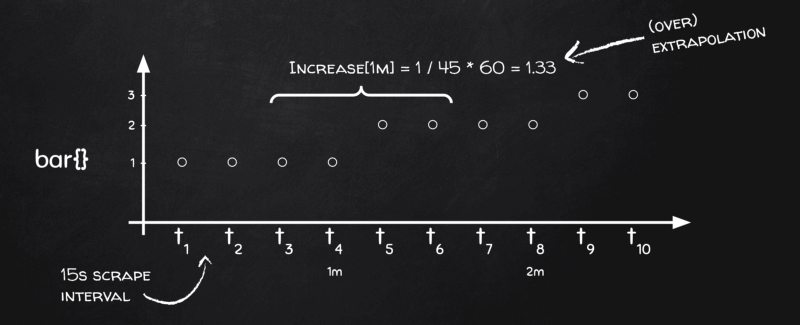 La extrapolación de Prometheus en acción
La extrapolación de Prometheus en acción
Mira, tenemos cuatro puntos de datos en cada bucket, pero necesitamos el delta en el tiempo, recuerda, y en términos de tiempo nuestros cuatro puntos cubren solo 45 segundos en lugar de 60: 15s para [t₃, t₄], otros 15s para [t₄, t₅] y los últimos 15s para [t₅, t₆]. El siguiente bucket será [t₇, t₈], [t₈, t₉] y [t₉, t₁₀], ¡pero ningún bucket contendrá el intervalo [t₆, t₇]! Y esto pasa porque Prometheus aplica el mismo algoritmo de bucketing tanto para cálculos de primer orden (por ejemplo, promedios sobre gauges) como para cálculos de segundo orden (por ejemplo, tasas sobre contadores).
Así que, básicamente, Prometheus entiende que el rango real en cada bucket es un scrape menos, es decir, 45 segundos en vez de 60 en nuestro caso. Por eso, cuando ve que la métrica cambió 1 dentro de un bucket, en realidad lee "1 en 45 segundos" y no "1 en 60 segundos", así que extrapola el resultado como 1 / 45 * 60 = 1.33, y así terminamos con valores de increase() mayores al cambio real.
A estas alturas, si todavía no te convences de que Prometheus es bueno para monitoreo pero no apto para datos exactos como facturación, mejor no hago negocios contigo :)
Si tan solo pudiéramos decirle a Prometheus que incluya ese scrape extra que se queda entre las s̶i̶l̶l̶a̶s̶ buckets…
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
El largo camino hacia la paz
¿Cómo lo arreglamos, si es que se puede?
Para empezar, podemos controlar nosotros mismos el rango y el step:
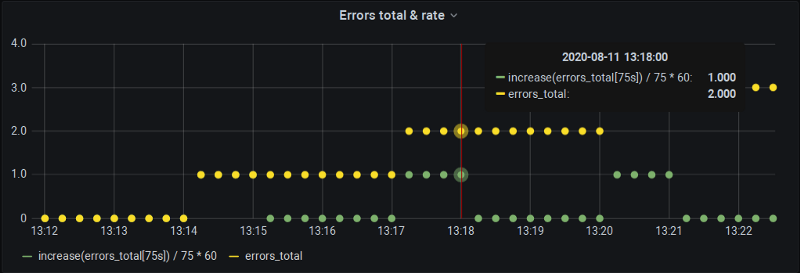 Llenando el hueco
Llenando el hueco
Para obtener el incremento sobre 60 segundos, le pedimos a P8s que calcule uno para 75 segundos (con esa muestra extra que normalmente queda entre los buckets). Por supuesto, Prometheus lo extrapolará a 75 segundos, pero nosotros lo des-extrapolamos manualmente de regreso a 60, y así nuestros gráficos quedan precisos y nos entregan los datos también en los límites de minuto exacto.
La desventaja, claro, es que no podemos usar el step automático de Grafana ni los mecanismos de $__interval. Pero al menos quedamos cubiertos para las definiciones de alertas en Grafana, donde de todos modos los intervalos se ingresan manualmente.
¿Y ahora qué?
Nada demasiado oficial todavía, lamentablemente. Hay trabajo en curso en Grafana para introducir $__rate_interval. Usar esta variable en lugar del simple $__interval sí incluirá ese scrape extra detrás del step para asegurarnos de obtener datos en, por ejemplo, los puntos de minuto exacto, como en nuestra demostración. Sin embargo, dejará la interpolación intacta:
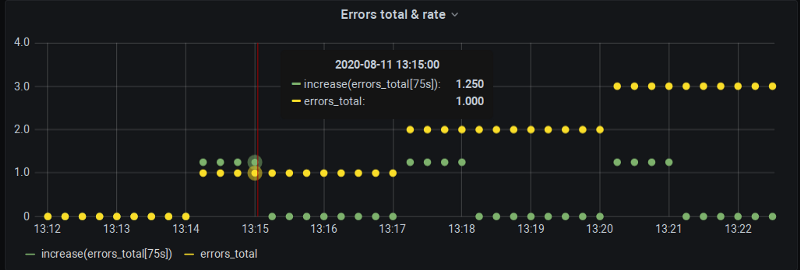 $__rate_interval simulado: el valor del minuto exacto está ahí, pero sigue habiendo error de extrapolación, aunque más pequeño.
$__rate_interval simulado: el valor del minuto exacto está ahí, pero sigue habiendo error de extrapolación, aunque más pequeño.
Últimamente hay algo de movimiento en este tema, así que ojalá esté disponible en la próxima versión de Grafana para que los valores cero de rate() dejen de aparecer.
Si queremos arreglar la "corrección" por extrapolación, hay dos opciones que conozco.
xrate
Es un fork de Prometheus que agrega las funciones **x**`rate()`, xincrease(), etc., que tanto añaden el scrape extra (similar a lo que hará $__rate_interval) como aplican la des-extrapolación, tal como hicimos en el ejemplo del capítulo anterior:
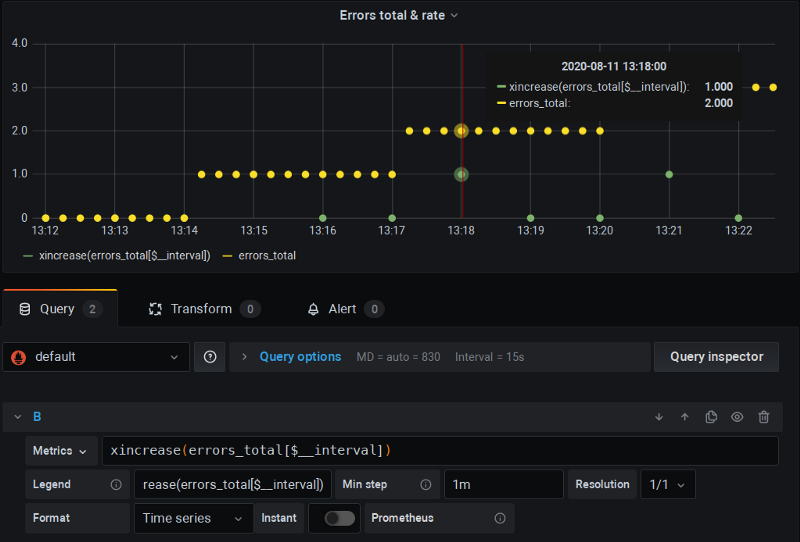 El fork xrate de P8s en acción: fíjate en la "x" en los nombres de las funciones
El fork xrate de P8s en acción: fíjate en la "x" en los nombres de las funciones
Aquí puedes ver que estoy ejecutando esta versión forkeada de P8s usando el $__interval estándar y el clamping de "Min step"; y todo simplemente funciona: no hay puros ceros y los cálculos son correctos.
Aunque es un fork, sigue de cerca los releases oficiales de Prometheus y
Alin Sinpalean (el maintainer) lo ha mantenido a flote durante los últimos años. No lo usé en producción, pero seguro le voy a dar una oportunidad en mi próximo proyecto.
VictoriaMetrics
Es un proyecto de almacenamiento remoto* para Prometheus que a su vez implementa una versión "arreglada" de las funciones de rate que considera el scrape extra y elimina la interpolación.
\* Es decir, configuras una o varias instancias de Prometheus para que envíen datos a VictoriaMetrics y luego ejecutas tu PromQL contra este último.
De nuevo, uso Grafana como siempre y las cosas simplemente funcionan:
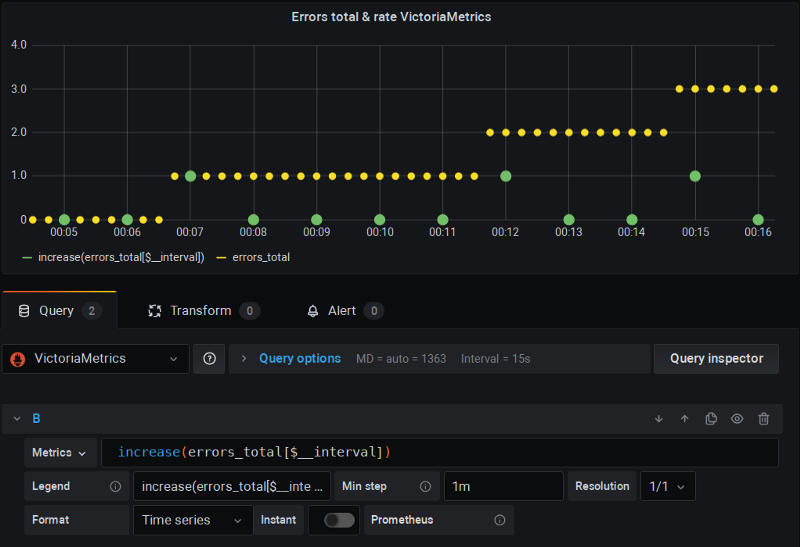 VictoriaMetrics en acción
VictoriaMetrics en acción
Epílogo
Espero que este post te ayude a darle sentido a tus gráficos de Grafana y a hacer las paces con cómo funcionan las cosas por aquí. Personalmente, le daría una oportunidad seria tanto al fork de xrate como a VictoriaMetrics la próxima vez que despliegue un sistema de monitoreo.
Si te interesan los detalles de por qué existe este problema, aquí van discusiones bastante extensas sobre el tema:
- Un excelente blog que explica este tipo de problemas y su evolución: enlace
- Mi post original "¿Qué…?" en el grupo de usuarios de P8s: enlace
- La extrapolación de rate()/increase() considerada perjudicial: enlace
- Propuesta para mejorar rate/increase: enlace
Para cerrar, déjame agregar que este tema divide a la gente en dos bandos: "los desarrolladores del core de P8s contra el resto". Y aunque los desarrolladores de P8s pueden tener sus propios motivos para sostener que tienen razón en este punto, el problema sí ocurre en la vida real y bastante seguido. Al ignorar este hecho, lo único que logran, citando aquí a Alin Sinpalean, es "hacer que todos, salvo Prometheus, sean dolorosamente conscientes de la diferencia entre un counter y un gauge: "debes usar $__interval con gauges y $__fancy_interval con counters, suerte"".
Yo sí tomo partido aquí... Que hablen los forks. Paz para tus datos.