
Ein langer Weg, bis rate() endlich hält, was es verspricht
Vor Kurzem habe ich eine zweiteilige Vortragsreihe zum Monitoring-System Prometheus gehalten. Im letzten Kapitel des zweiten Vortrags habe ich ein eher kniffliges Thema gestreift: wie Änderungen an Metriken klammheimlich unter den Teppich gekehrt werden können. Dieser Blogbeitrag knüpft an die Vortragsreihe an und vertieft, was auf den ersten Blick wie ein Widerspruch wirkt.

Im Inneren der Kumistavi-Höhle, auch bekannt als Prometheus-Höhle
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Initialisieren Sie Ihre (Fehler-)Counter
Initialisieren Sie Ihre Counter nach Möglichkeit mit 0, damit die Metrik sofort gemeldet wird – wieder mit 0 als Wert. Hier der Grund:
 Bei Countern interessieren uns ausschließlich Änderungen
Bei Countern interessieren uns ausschließlich Änderungen
Oben sehen wir eine Metrik, die nicht auf null initialisiert wurde. Wenn nun der erste Fehler dafür sorgt, dass ab sofort "1" gemeldet wird, speichert Prometheus (nennen wir es der Kürze halber ab jetzt einfach "P8s") das brav ab. Aus seiner Sicht hat sich an der Metrik aber nichts geändert. Wenn Sie also einen Alert auf Änderungen dieses Counters laufen haben, wird er den ersten Fehler garantiert verpassen – und derjenige mit dem Pager schaut bald ziemlich betreten drein.
Für P8s-Neulinge mag das überraschend sein, ist aber schnell verstanden. Und es ist tatsächlich das einzige in diesem Beitrag angesprochene Problem, das ich der App-Entwicklung überlassen würde.
Kommen wir zu den fortgeschrittenen Feinheiten.
rate() zeigt keinerlei Änderungen an
Ich hatte oft einen langsam steigenden Counter – etwa einen Fehlerzähler – bei dem rate() nur Nullen zurücklieferte, obwohl mein Range lehrbuchmäßig gesetzt war. Vielleicht steigt mein Counter ja gar nicht wirklich, redete ich mir zur Selbstberuhigung ein – aber das war nicht der Fall:
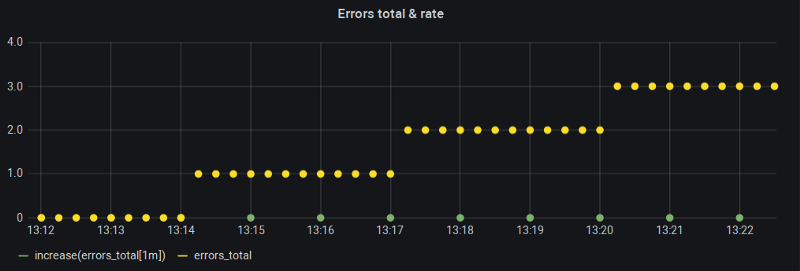 Counter steigt, aber sein rate() nicht
Counter steigt, aber sein rate() nicht
Mein Grafana "Min step" (und damit $__interval) war auf eine Minute fixiert, und bei 15 s Scrape-Intervall ist das genau das empfohlene Look-back-Fenster für die rate()-Funktion. Was läuft hier also schief?
Um das zu verstehen, gehen wir zurück an die Tafel:
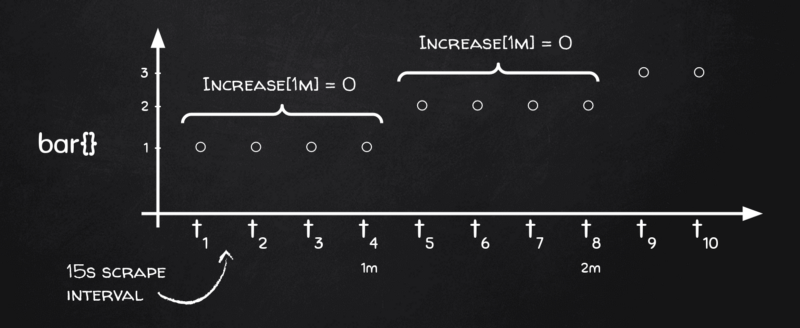
Sie sehen: Je nachdem, wie die Sterne stehen – wenn unsere 1-Minuten-Range-Buckets genau auf den Grenzen der Metrikänderungen landen, gibt es innerhalb des Buckets gar keine Änderung der Metrik. Genau deshalb liefern rate() und seine Schwester increase() Nullen zurück.
Warum tritt das so häufig und so zuverlässig auf? Zwei Faktoren:
- Wenn in Ihrem Code etwas Änderungen rund um eine volle Minute meldet (denken Sie an Cronjobs), landet die Änderung beim Scraping mit hoher Wahrscheinlichkeit auf der Vollminutengrenze.
- Seit zwei Jahren sorgt Grafana (und das zu Recht) dafür, dass der Beginn des Chart-Bereichs ein Vielfaches des step ist. Beträgt Ihr Step in Grafana also eine Minute, fallen die Bucket-Grenzen immer auf eine Vollminutengrenze, z. B. [ [18:06:00, 18:07:00], [18:07:00, 18:08:00], …].
In Kombination ergibt das einen perfekten Sturm (oder eher eine perfekte Flaute?), bei dem die Raten für Counter, die ihren Wert auf einer Vollminutengrenze ändern, durchgehend null werden.
Aber glauben Sie mir nicht einfach so – ändern wir den Step von 1 Minute auf 15 Sekunden und schauen, was passiert (im Grunde berechnen wir rate() bei jedem Scrape über die letzten 4 Samples).
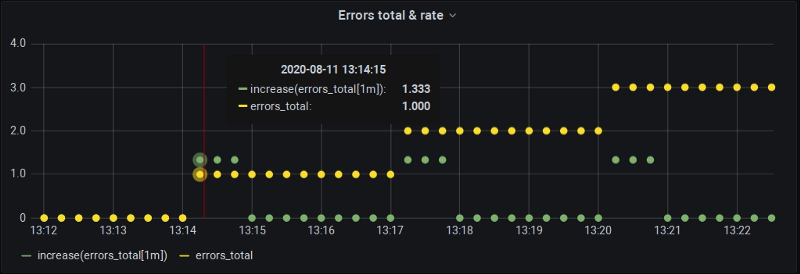 increase(errors_total[1m]) alle 15 s
increase(errors_total[1m]) alle 15 s
Aha! Zwei interessante Beobachtungen:
- Die Tafelzeichnung bestätigt sich – unsere Metrik ändert sich um 13:14:15, aber
increase()ist um 13:15:00 null, weil wir wieder das "perfekte" Bucket-Alignment haben, bei dem alle Änderungen genau auf den Grenzen liegen. - Um 13:14:15 meldet
increase()zwar eine Änderung, aber … sie fällt größer aus als die tatsächliche! Nämlich 1,33 statt 1,0.
Warum? Zurück an die Tafel:
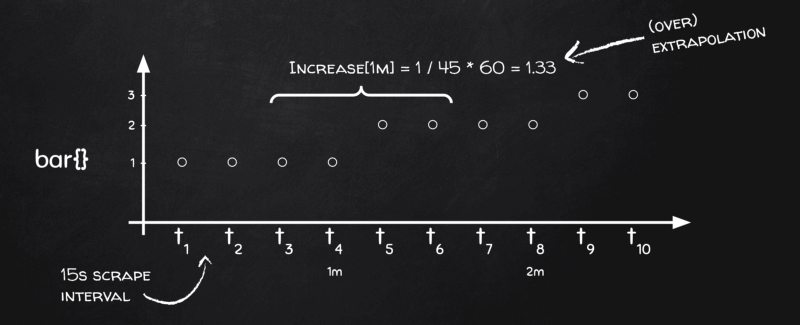 Prometheus-Extrapolation in Aktion
Prometheus-Extrapolation in Aktion
Wir haben vier Datenpunkte in jedem Bucket, brauchen aber ein Delta über die Zeit – und zeitlich gesehen decken unsere vier Datenpunkte nur 45 Sekunden statt 60 ab! 15 s für [t₃, t₄], weitere 15 s für [t₄, t₅] und die letzten 15 s für [t₅, t₆]. Der nächste Bucket ist [t₇, t₈], [t₈, t₉] und [t₉, t₁₀], aber kein Bucket enthält das Intervall [t₆, t₇]! Der Grund: Prometheus wendet denselben Bucketing-Algorithmus sowohl auf Berechnungen erster Ordnung (z. B. Mittelwerte auf Gauges) als auch auf Berechnungen zweiter Ordnung (z. B. Raten auf Countern) an.
Im Grunde geht Prometheus also davon aus, dass der tatsächliche Bereich in jedem Bucket einen Scrape weniger umfasst, in unserem Fall also 45 Sekunden statt 60. Wenn es eine Änderung um 1 in einem Bucket sieht, ist das eigentlich "um 1 in 45 Sekunden" und nicht "um 1 in 60 Sekunden". Also extrapoliert es das Ergebnis als 1 / 45 * 60 = 1,33 – und so kommt es, dass increase()-Werte größer ausfallen als die tatsächliche Änderung.
Wer an dieser Stelle immer noch nicht überzeugt ist, dass Prometheus zwar gut zum Monitoring, aber nicht für exakte Daten wie Abrechnungen taugt, mit dem würde ich ungern Bankgeschäfte machen :)
Wenn wir Prometheus jetzt nur dazu bringen könnten, diesen einen zusätzlichen Scrape mit einzubeziehen, der zwischen den S̶t̶ü̶h̶l̶e̶n̶ Buckets fällt …
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Der lange Weg zum Frieden
Wie beheben wir das – falls überhaupt?
Zunächst können wir Range und Step selbst steuern:
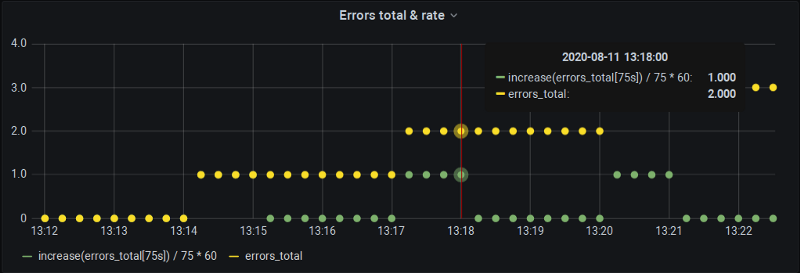 Die Lücke schließen
Die Lücke schließen
Um den Increase über 60 Sekunden zu erhalten, lassen wir P8s einen über 75 Sekunden berechnen (mit jenem zusätzlichen Sample, das normalerweise zwischen die Buckets fällt). Natürlich extrapoliert Prometheus das auf 75 Sekunden, aber wir de-extrapolieren manuell zurück auf 60 – und schon sind unsere Charts präzise und liefern uns Daten auch an Vollminutengrenzen.
Der Nachteil: Wir können den automatischen Step und die $__interval-Mechanismen von Grafana nicht nutzen. Aber zumindest sind wir bei Alert-Definitionen in Grafana abgesichert, wo Intervalle ohnehin manuell gesetzt werden.
Wie geht es weiter?
Leider noch nichts wirklich Offizielles. In Grafana gibt es laufende Arbeiten, um $__rate_interval einzuführen. Verwendet man diese Variable statt des einfachen $__interval, wird tatsächlich der zusätzliche Scrape hinter dem step berücksichtigt, sodass wir – wie in unserer Demonstration – Daten z. B. an Vollminutenpunkten erhalten. Die Interpolation bleibt jedoch unangetastet:
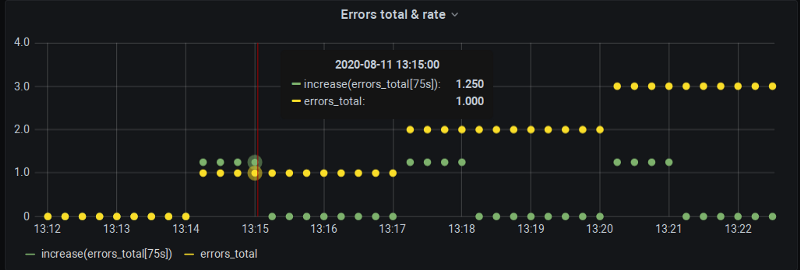 $__rate_interval simuliert – der Vollminutenwert ist da, aber es bleibt ein Extrapolationsfehler, wenn auch ein kleinerer.
$__rate_interval simuliert – der Vollminutenwert ist da, aber es bleibt ein Extrapolationsfehler, wenn auch ein kleinerer.
In letzter Zeit kommt Bewegung in das Thema – hoffentlich landet es im nächsten Grafana-Release, damit Null-Werte bei rate() der Vergangenheit angehören.
Wenn wir die "Korrektur" durch Extrapolation beheben wollen, gibt es zwei mir bekannte Optionen.
xrate
Das ist ein Fork von Prometheus, der **x**`rate()`, xincrease() usw. ergänzt – Funktionen, die einen zusätzlichen Scrape einbeziehen (ähnlich wie $__rate_interval es tun wird) und zugleich die De-Extrapolation anwenden, wie wir es im Beispiel im letzten Kapitel gemacht haben:
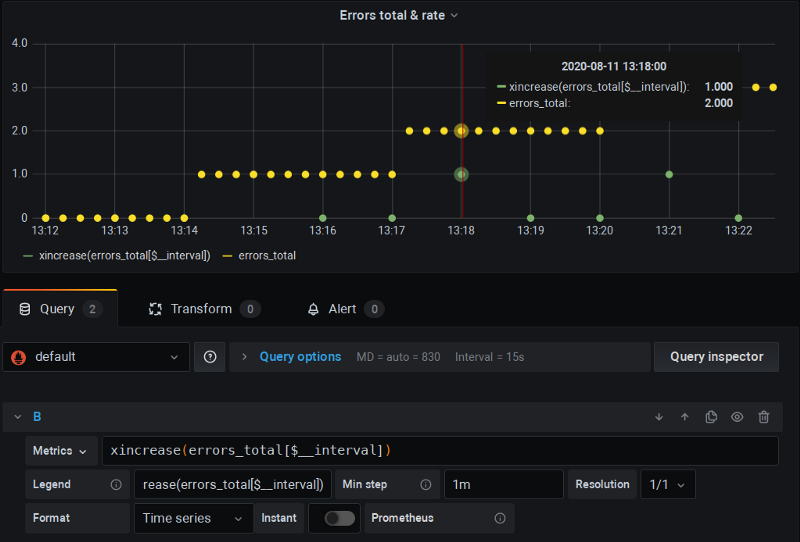 xrate-P8s-Fork in Aktion – beachten Sie das "x" in den Funktionsnamen
xrate-P8s-Fork in Aktion – beachten Sie das "x" in den Funktionsnamen
Hier sehen Sie, wie ich diese geforkte P8s-Version mit Standard-$__interval und "Min step"-Klemmung betreibe – und alles funktioniert: keine Nullen mehr und korrekte Berechnungen.
Es ist zwar ein Fork, folgt aber den offiziellen Prometheus-Releases sehr eng, und
Alin Sinpalean (der Maintainer) hält ihn seit ein paar Jahren am Leben. Im Produktivbetrieb habe ich ihn noch nicht eingesetzt, werde ihm aber in meinem nächsten Projekt definitiv eine Chance geben.
VictoriaMetrics
Das ist ein Remote-Storage-Projekt* für Prometheus, das wiederum eine "fixed" Version der Rate-Funktionen implementiert, die sowohl den zusätzlichen Scrape berücksichtigt als auch ohne Interpolation auskommt.
\* D. h. Sie konfigurieren potenziell mehrere Prometheus-Instanzen so, dass sie Daten an VictoriaMetrics senden, und führen Ihr PromQL anschließend gegen Letzteres aus.
Auch hier verwende ich Grafana wie gewohnt, und alles funktioniert auf Anhieb:
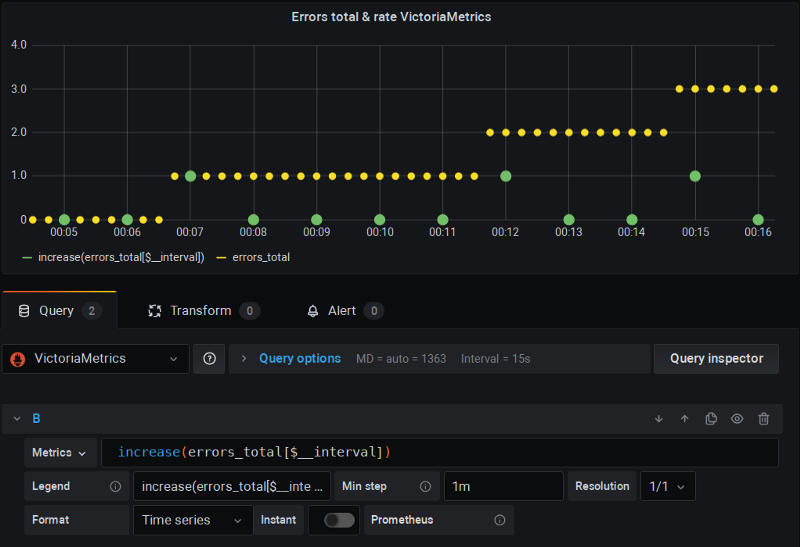 VictoriaMetrics in Aktion
VictoriaMetrics in Aktion
Epilog
Ich hoffe, dieser Beitrag hilft Ihnen, Ihre Grafana-Charts besser zu verstehen und Frieden damit zu schließen, wie die Dinge hier funktionieren. Ich persönlich würde sowohl dem xrate-Fork als auch VictoriaMetrics beim nächsten Aufbau eines Monitoring-Systems eine ernsthafte Chance geben.
Falls Sie sich für die Hintergründe interessieren, warum dieses Problem überhaupt existiert, hier ein paar recht ausführliche Diskussionen zum Thema:
- Ein hervorragender Blog, der diese Art von Problemen und ihre Entwicklung erläutert: Link
- Mein ursprünglicher "Was zum …?"-Post in der P8s-Users-Gruppe: Link
- rate()/increase()-Extrapolation considered harmful: Link
- Vorschlag zur Verbesserung von rate/increase: Link
Zum Abschluss sei gesagt, dass dieses Thema die Leute in zwei Lager spaltet: "P8s-Core-Entwickler vs. der Rest". Und auch wenn die P8s-Entwickler ihre eigenen Gründe haben mögen zu sagen, dass sie hier richtigliegen – das Problem tritt im echten Leben nun einmal auf, und zwar ziemlich häufig. Indem sie diese Tatsache ignorieren, sorgen sie nur dafür – um Alin Sinpalean zu zitieren –, dass "allen außer Prometheus selbst der Unterschied zwischen einem Counter und einem Gauge schmerzhaft bewusst wird: ‚Sie müssen $__interval mit Gauges und $__fancy_interval mit Countern verwenden, viel Glück"‘".
Ich beziehe hier Position … Lassen wir die Forks sprechen. Friede sei mit Ihren Daten.