
Kaggle Daysは、世界トップクラスのデータサイエンティストと出会い、学び、競い合える注目のイベントです。私たちが優勝を勝ち取るまでの軌跡をお伝えします。
2019年1月、パリで第2回Kaggle Daysが開催されました。世界各国から200名を超えるデータサイエンティストが集まり、学びや知見を共有するとともに、カンファレンス会期中には11時間にわたるKaggleコンペティションで腕を競い合いました。本記事では、3位入賞を果たした私たちのソリューションを紹介します。
LVMHのラグジュアリー製品の売上を予測する
参加者には、www.louisvuitton.comで発売されたLouis Vuitton製品の発売後7日間のデータが提供されました。課題は、発売後3か月間の各月の売上を予測することです。データには、製品説明、売上統計、ソーシャルメディア、サイト内ナビゲーション、画像データなども含まれていました。
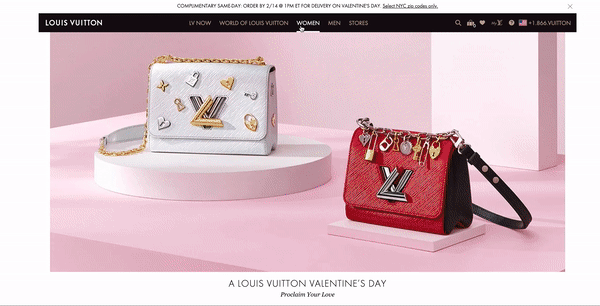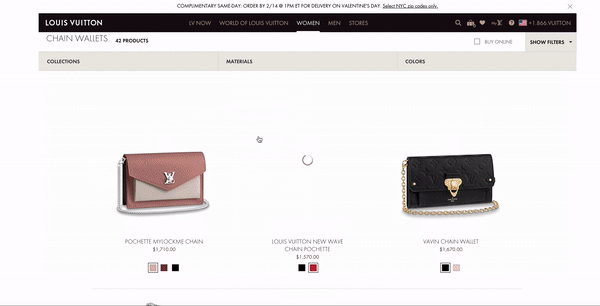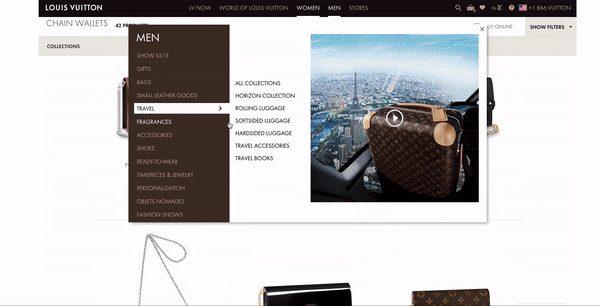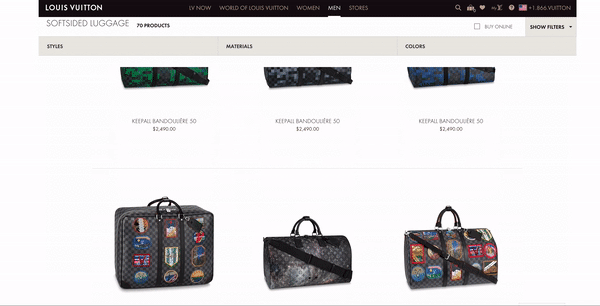 louisvuitton.comのスクリーンショット
louisvuitton.comのスクリーンショット
戦略
過去の多くのKaggleコンペティション同様、私たちはシンプルな方針で臨みました。
- 特徴量はシンプルに、モデルは複雑に — 特徴量は単純に作り、複雑な相互作用はMLモデルに「理解」させる。
- 多様性を活かす — 多くのモデルを学習させ、リーダーボードで好成績を残しつつ誤差の重なりが最も少ないモデル同士をアンサンブルする。
- チームワーク — 各メンバーが明確な役割を担う。Feature-Extractor、Modeler、Integrator。
 チームメンバー: Gad Benram、Seffi Cohen、Nurit C Inger
チームメンバー: Gad Benram、Seffi Cohen、Nurit C Inger
ベースライン
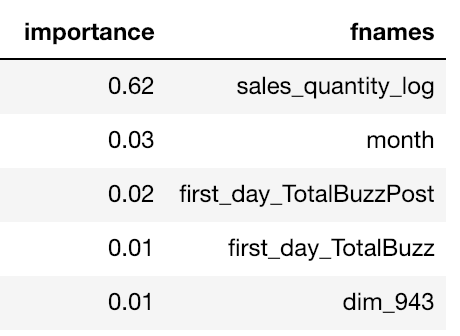
データを開く前から、私たちは先人の知恵を借り、多数の特徴量が組み込まれたKaggle Daysチーム提供のベースラインスクリプトを活用しました。各特徴量の重要度を把握するため、訓練データ全体に対して_ツリー数100本以下_のシンプルなRandom Forestモデルを走らせたところ、結果は予想外でした。発売後7日間の売上のlogが、他のすべての特徴量に比べて20倍も高い重要度スコアを示したのです。この発見によって、生成するモデルの分散をある程度コントロールできるようになりました。
ビジネス課題の定式化
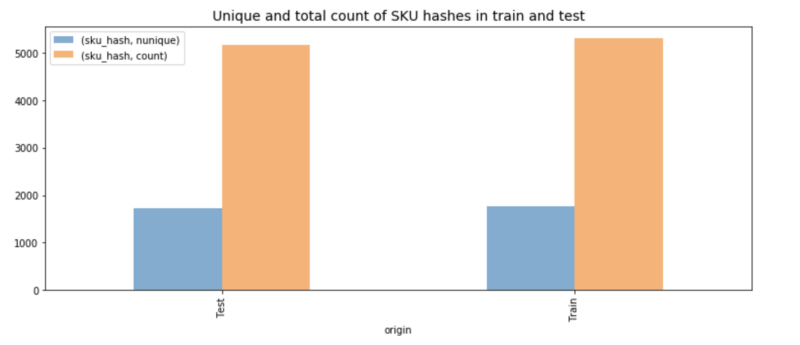
データを掘り下げてみると、データ分割が見事に行われていることが分かりました。訓練データには約1,700のユニークな製品があり、テストデータにもほぼ同数の別の製品が含まれていたのです。そこで私たちは、課題を次のように捉え直しました。たとえばある女性向けブレスレットが発売後最初の1週間にx個売れ、続く各月にそれぞれm1、m2、m3個売れたとき、類似の新商品はどのくらい売れるのか?
トレンドは無視 — データは発売後最初の1週間を基準としており、グレゴリオ暦の月情報も含まれていなかったため、季節要因は無視し、ソーシャルメディアのトレンドにもあまり重きを置きませんでした。結局のところ、課題は「製品同士の類似性をいかに捉えるか」に集約されたのです。なお、Mikel Bober-Irizarはテスト期間中の売上の相対的な減少率の推定に成功し、私たちがMLE(Maximum Leaderboard Estimation)と呼ぶ手法でスコアを引き上げました。
製品類似性のモデリング
- カテゴリ — 製品は専門家の手で、レザーグッズやデイリーバッグなどさまざまなタイプに分類されていました。これらの特徴量は製品間の売上の類似性を捉える上で非常に有効でした。人間がそれぞれのアイテムをどう受け止めるかを受動的に表しているだけでなく、サイト上での掲載位置や顧客への見せ方を決める要素として、売上に能動的にも影響するからです。
- テキスト — テキスト特徴量にTF-IDFとPCAを適用し、特徴を表現しました。
- 画像ベクトル — 画像特徴量はGoogleのVision APIで抽出しました。ただし、このAPIはImageNetのような汎用データセットで学習されたニューラルネットワークを使っており、高級カジュアルハンドバッグ同士を見分けるには不向きです。そのため、これらの特徴量は採用しませんでした。
- クリック率 — サイトのトラフィックデータにはページビューとアイテムクリック数が含まれており、そこから平均クリック率を算出して特徴量に用いました。
モデル
データに有用なカテゴリ特徴量が多く含まれていたため、それらを効率的に扱えるライブラリの選定が重要でした。XGBoostにはカテゴリ特徴量の組み込みサポートがありませんが、LightGBMとCatBoostは対応しています。CatBoostは処理に時間がかかりすぎたため、最終的にはLightGBMをGBDTとRandom Forestのブースティング手法で実行しました。ニューラルネットワークはデータ量が比較的少なかったため収束しませんでした。
では、なぜ「これは過学習」と言えるのか?
もし私たちがLVMHに売上向上のコンサルティングを行う立場であれば、少し違うアプローチを取っていたでしょう。たとえばLVMHは、カテゴリ分類や製品説明文といった最重要の特徴量についてA/Bテストを実施し、それらを強化することで売上が変動するかどうかを検証できたはずです。とはいえ、Kaggleコンペティションで勝つことが目的である以上、私たちの唯一のゴールは予測をテストセットにできるだけ適合させることでした。
マシンと環境
コードはすべて、n1-highmem-8(vCPU 8コア、RAM 52GB、0.1ドル/時)インスタンスのプリエンプティブなGoogle Cloud Deep Learning VM上で実行しました。マシンをus-centralリージョンに配置していたため、ヨーロッパで参加していた私たちにとってコンペ時間中の可用性は非常に高い状態でした。
体験
Kaggleは知識を共有し、多種多様で難易度の高いコンペティションで自分を試せる素晴らしいプラットフォームですが、Kaggle Daysはこのコミュニティに大切な要素を加えてくれます。それが対面での交流です。世界中から集まった仲間のデータサイエンティストと出会い、誰もが共通の夢を抱いていることを知る、最高の時間を過ごしました。その夢とは、テストデータをオーバーフィットすることです。
コンペティション中に作業するチーム
ノートブックのコードはGithubのこちら | Kaggleプロフィール: Gad Benram