
Kaggle Days es (casi) oficialmente el evento más interesante para conocer, aprender y competir con los data scientists más talentosos del mundo. Y así fue como lo ganamos.
En enero de 2019, París fue sede del segundo Kaggle Days de la historia. Más de 200 data scientists de todo el mundo se reunieron para aprender, intercambiar conocimiento y, finalmente, medirse entre sí en una competencia de Kaggle presencial de 11 horas durante la conferencia. En este artículo te contamos nuestra solución, con la que nos llevamos el tercer lugar.
Predecir las ventas de los productos de lujo de LMVH
A los participantes se les entregaron datos de los primeros siete días de productos de Louis Vuitton tras su lanzamiento en www.louisvuitton.com. El objetivo era pronosticar las ventas de cada uno de los tres meses posteriores al lanzamiento. Los datos adicionales incluían descripciones de productos, estadísticas de ventas, redes sociales, navegación en el sitio web e imágenes.
 Captura de pantalla de louisvuitton.com
Captura de pantalla de louisvuitton.com
Estrategia
Como en muchas de nuestras competencias anteriores en Kaggle, seguimos tácticas sencillas:
- Features simples, modelos complejos: armar features sencillas y dejar que los modelos de ML "entiendan" las interacciones complejas entre ellas.
- Apostar por la diversidad: entrenar muchos modelos y armar un ensemble con los que mejor se desempeñen en el leaderboard y tengan el menor solapamiento en sus errores.
- Trabajo en equipo: cada integrante tiene una responsabilidad bien definida: el Feature-Extractor, el Modeler y el Integrator.
 Integrantes del equipo: Gad Benram, Seffi Cohen y Nurit C Inger
Integrantes del equipo: Gad Benram, Seffi Cohen y Nurit C Inger
Baseline
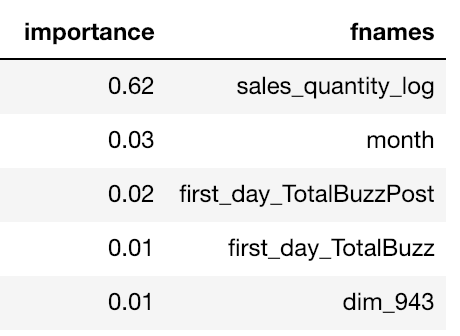
Antes incluso de mirar los datos, nos apoyamos en hombros de gigantes y usamos el script baseline del equipo de Kaggle Days, que ya incluía numerosas features. Corrimos un modelo simple de Random Forest con no más de 100 árboles sobre todos los datos de entrenamiento, solo para ver la importancia de cada feature. El resultado fue una sorpresa total: el log de las ventas de los primeros 7 días obtuvo un puntaje de importancia 20 veces mayor que el de las demás features. Esa información nos permitió controlar, hasta cierto punto, la varianza de los modelos generados.
Cómo formulamos la pregunta de negocio
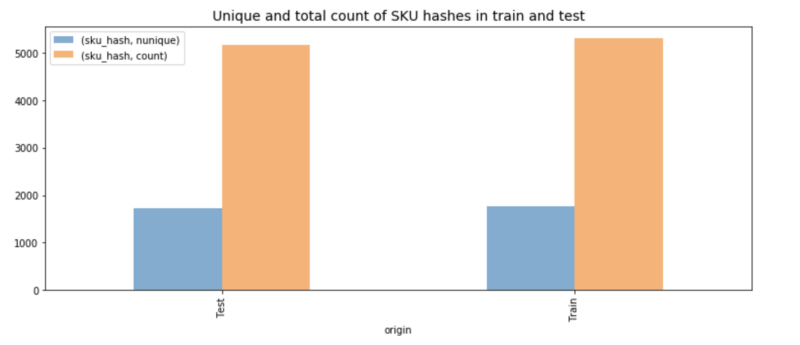
Al meternos de lleno en los datos, vimos que alguien había hecho un buen trabajo dividiéndolos. El set de entrenamiento tenía ~1700 productos únicos, mientras que el de prueba incluía casi la misma cantidad, pero de productos distintos. Eso nos llevó a plantear el problema así: si un producto específico, digamos una pulsera de mujer, se vendió x veces en la primera semana tras su lanzamiento y m1, m2, m3 en los meses siguientes, ¿cuánto se venderá de un artículo similar?
Ignoramos las tendencias: como los datos eran relativos a la primera semana de lanzamiento y no incluían el mes del calendario, dejamos de lado las tendencias estacionales y le prestamos menos atención a las redes sociales. En el fondo, todo se reducía a la cuestión de la similitud entre productos. Vale la pena mencionar que Mikel Bober-Irizar logró estimar la caída relativa de las ventas durante el período de prueba y así mejoró el puntaje con una técnica que llamamos MLE: Maximum Leaderboard Estimation.
Cómo modelar la similitud entre productos
- Categorías: los productos fueron clasificados por expertos humanos en distintos tipos, como artículos de cuero y bolsos de uso diario. Estas features resultaron extremadamente valiosas para entender la similitud entre las ventas de productos diferentes. No solo reflejan cómo una persona percibiría estos artículos de forma pasiva, sino que además influyen activamente en las ventas, porque determinan la posición del artículo en el sitio web y la forma en que se le presenta al cliente.
- Texto: caracterizamos la feature a partir de su texto, aplicando TF-IDF y PCA sobre las features.
- Vectores de imágenes: las features de imágenes se extrajeron con la Vision API de Google. Esta API usa redes neuronales entrenadas sobre datasets muy genéricos, como ImageNet, que no sirven en absoluto para distinguir entre dos bolsos casuales de lujo. Por eso, descartamos estas features.
- Click-through rate: los datos de tráfico del sitio web incluían vistas de página y clics en los artículos. A partir de ahí, calculamos el clickthrough rate promedio y lo usamos como feature.
Modelos
Como los datos incluían features categóricas valiosas, era importante usar una librería que pudiera aprovecharlas de forma eficiente. XGBoost no tiene un mecanismo nativo para features categóricas, a diferencia de LightGBM y Catboost. Catboost tardaba demasiado en procesar, así que terminamos corriendo LightGBM con GBDT y Random Forest como métodos de boosting. Las redes neuronales no lograron converger por la cantidad relativamente pequeña de datos.
Entonces, ¿por qué decimos que es overfitting?
Si estuviéramos asesorando a LMVH sobre cómo aumentar las ventas, habríamos aplicado un enfoque algo distinto. Por ejemplo, LMHV podría hacer A/B testing sobre las features más importantes, como la categorización o las descripciones textuales de los productos, para ver si modificarlas afecta las ventas. Sin embargo, cuando lo que buscas es ganar una competencia de Kaggle, el único objetivo es ajustar tus predicciones lo mejor posible al set de prueba.
Máquinas y entornos
Todo el código corrió en una Deep Learning VM de Google Cloud preemptible, con una instancia n1-highmem-8 (8 vCPUs, 52 GB de RAM, 0.1 USD/hora). La máquina estaba en la zona us-central, así que tenía alta disponibilidad durante las horas de la competencia, ya que nosotros estábamos en Europa.
Experiencia
Si bien Kaggle es una plataforma increíble para compartir conocimiento y ponerte a prueba en competencias muy variadas y difíciles, Kaggle Days le suma una capa importante a esta comunidad: la interacción presencial. La pasamos genial conociendo a otros data scientists de todo el mundo y descubriendo que todos compartimos un mismo sueño: hacerle overfitting al set de prueba.
El equipo trabajando durante la competencia
Código del notebook acá en Github | Perfil de Kaggle: Gad Benram