
Kaggle Days ist (quasi) offiziell das spannendste Event, um die weltbesten Data Scientists zu treffen, von ihnen zu lernen und gegen sie anzutreten. Und so haben wir gewonnen.
Im Januar 2019 fanden in Paris die erst zweiten Kaggle Days überhaupt statt. Mehr als 200 Data Scientists aus aller Welt kamen zusammen, um zu lernen, Wissen auszutauschen und sich am Ende in einem 11-stündigen Kaggle-Wettbewerb direkt vor Ort zu messen. Dieser Blogbeitrag beschreibt unsere Lösung, mit der wir den 3. Platz belegt haben.
Verkaufsprognosen für die Luxusprodukte von LVMH
Die Teilnehmenden bekamen Daten der ersten sieben Tage von Louis-Vuitton-Produkten nach deren Launch auf www.louisvuitton.com. Aufgabe war es, die Verkäufe für jeden der drei Folgemonate zu prognostizieren. Zu den weiteren Daten zählten Produktbeschreibungen, Verkaufsstatistiken, Social Media, Website-Navigation sowie Bilddaten.
 Screenshot von louisvuitton.com
Screenshot von louisvuitton.com
Strategie
Wie schon bei vielen unserer früheren Kaggle-Wettbewerbe sind wir nach einer einfachen Taktik vorgegangen:
- Simple Features, komplexe Modelle — schlichte Features bauen und die ML-Modelle die komplexen Wechselwirkungen zwischen ihnen "verstehen" lassen.
- Auf Vielfalt setzen — viele Modelle trainieren und die Leaderboard-stärksten Modelle mit der geringsten Fehlerüberlappung zu einem Ensemble kombinieren.
- Teamwork — jedes Teammitglied hat eine klar umrissene Rolle: Feature-Extractor, Modeler und Integrator.
 Teammitglieder: Gad Benram, Seffi Cohen und Nurit C Inger
Teammitglieder: Gad Benram, Seffi Cohen und Nurit C Inger
Baseline
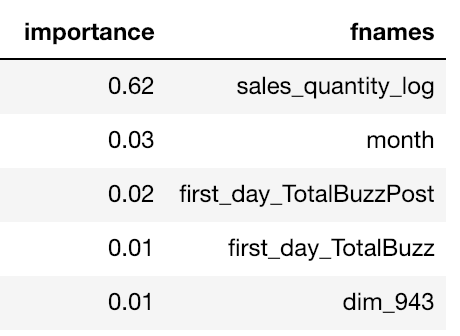
Bevor wir die Daten überhaupt anschauten, haben wir uns auf die Schultern von Riesen gestellt und das Baseline-Skript des Kaggle-Days-Teams genutzt, das bereits zahlreiche Features enthielt. Wir trainierten ein einfaches Random-Forest-Modell mit höchstens 100 Bäumen auf den gesamten Trainingsdaten — einfach um die Bedeutung der einzelnen Features zu sehen. Das Ergebnis überraschte uns ziemlich: Der Logarithmus der Verkäufe der ersten 7 Tage erhielt einen 20-mal höheren Importance-Score als alle anderen Features. Diese Erkenntnis half uns, die Varianz der erzeugten Modelle bis zu einem gewissen Grad in den Griff zu bekommen.
Die Geschäftsfrage formulieren
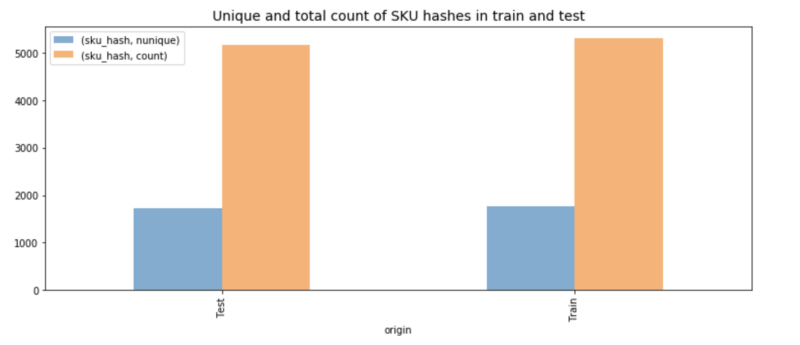
Beim genaueren Blick in die Daten zeigte sich, dass jemand bei der Aufteilung gute Arbeit geleistet hatte. Die Trainingsdaten umfassten ~1700 unterschiedliche Produkte, der Testdatensatz nahezu ebenso viele andere Produkte. Das brachte uns dazu, das Problem so zu fassen: Angenommen, ein bestimmtes Produkt — etwa ein Damenarmband — wurde in der ersten Woche nach Launch x-mal verkauft und in den Folgemonaten m1, m2 und m3 — wie viel verkauft sich dann von einem ähnlichen Artikel?
Trends ausgeblendet — da sich die Daten auf die erste Woche nach dem Launch bezogen und den Kalendermonat nicht enthielten, vernachlässigten wir saisonale Effekte und schenkten Social-Media-Trends weniger Beachtung. Im Kern lief alles auf die Frage der Produktähnlichkeit hinaus. Erwähnenswert: Mikel Bober-Irizar gelang es, den relativen Rückgang der Verkäufe im Testzeitraum zu schätzen und damit den Score über ein Verfahren zu verbessern, das wir MLE — Maximum Leaderboard Estimation — nennen.
Wie lässt sich Produktähnlichkeit modellieren?
- Kategorien — die Produkte wurden von Fachleuten in verschiedene Typen wie Lederwaren oder Alltagstaschen eingeteilt. Diese Features waren extrem wertvoll, um die Ähnlichkeit der Verkäufe verschiedener Produkte zu erfassen. Sie spiegeln nicht nur passiv wider, wie ein Mensch diese Artikel wahrnehmen würde, sondern beeinflussen die Verkäufe auch aktiv, weil sie die Position auf der Website und die Art der Präsentation gegenüber Kundinnen und Kunden bestimmen.
- Text — Charakterisierung der Features über ihren Text mittels TF-IDF und PCA.
- Bildvektoren — die Bild-Features wurden mit Googles Vision API extrahiert. Diese API nutzt neuronale Netze, die auf sehr generischen Datensätzen wie ImageNet trainiert wurden — wenig hilfreich, wenn es darum geht, zwischen zwei luxuriösen Freizeit-Handtaschen zu unterscheiden. Diese Features haben wir deshalb außen vor gelassen.
- Click-through-Rate — Die Daten zum Website-Traffic enthielten Seitenaufrufe und Artikel-Klicks. Daraus haben wir die durchschnittliche Click-through-Rate berechnet und als Feature verwendet.
Modelle
Da die Daten wertvolle kategoriale Features enthielten, war es wichtig, eine Bibliothek zu nutzen, die solche Features effizient verarbeiten kann. XGBoost hat — anders als LightGBM und Catboost — keinen eingebauten Mechanismus für kategoriale Features. Catboost brauchte zu lange, also setzten wir am Ende auf LightGBM mit GBDT und Random Forest als Boosting-Verfahren. Neuronale Netze konvergierten wegen der vergleichsweise geringen Datenmenge nicht.
Warum sprechen wir hier von Overfitting?
Hätten wir LVMH bei der Steigerung der Verkäufe beraten, wären wir etwas anders vorgegangen. LVMH könnte zum Beispiel A/B-Tests an den wichtigsten Features wie Kategorisierung oder Produkttexten fahren, um zu prüfen, ob deren Optimierung die Verkäufe tatsächlich beeinflusst. Wenn es aber darum geht, einen Kaggle-Wettbewerb zu gewinnen, ist das einzige Ziel, die Vorhersagen bestmöglich an das Test-Set anzupassen.
Maschinen und Umgebungen
Der gesamte Code lief auf einer preemptiblen Google Cloud Deep Learning VM mit einer n1-highmem-8-Instanz (8 vCPUs, 52 GB RAM, 0,1 USD/Std.). Die Maschine stand in der Region us-central und war daher während der Wettbewerbszeiten gut verfügbar — wir saßen ja in Europa.
Fazit
Kaggle ist eine großartige Plattform, um Wissen zu teilen und sich in vielfältigen, anspruchsvollen Wettbewerben zu beweisen — die Kaggle Days ergänzen diese Community aber um eine entscheidende Dimension: den persönlichen Austausch. Wir hatten eine fantastische Zeit, Data Scientists aus aller Welt kennenzulernen und festzustellen, dass wir alle denselben Traum teilen: Overfitting auf den Testdaten.
Das Team während des Wettbewerbs
Notebook-Code hier auf GitHub | Kaggle-Profil: Gad Benram