
Kaggle Days est (presque) officiellement l'événement incontournable pour rencontrer, apprendre et affronter les meilleurs data scientists du monde. Et voici comment nous l'avons remporté.
Paris a accueilli en janvier 2019 la 2e édition de Kaggle Days. Plus de 200 data scientists venus du monde entier se sont réunis pour apprendre, partager leurs connaissances et finalement s'affronter lors d'une compétition Kaggle de 11 heures en présentiel, organisée durant la conférence. Cet article décrit notre solution, qui nous a valu la 3e place.
Prédire les ventes des produits de luxe LVMH
Les participants disposaient des données des sept premiers jours suivant le lancement de produits Louis Vuitton sur www.louisvuitton.com. L'objectif : prévoir les ventes pour chacun des trois mois suivant le lancement. Les données complémentaires comprenaient les descriptions de produits, les statistiques de vente, les réseaux sociaux, la navigation sur le site et des données d'image.
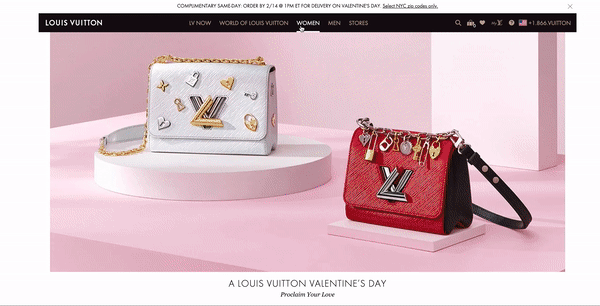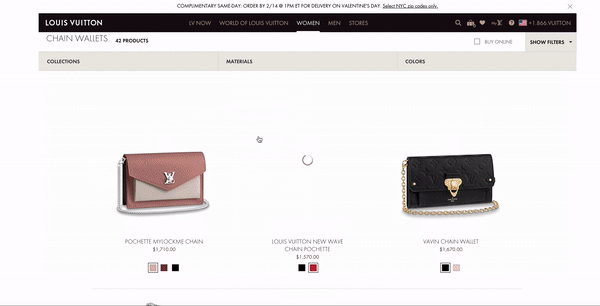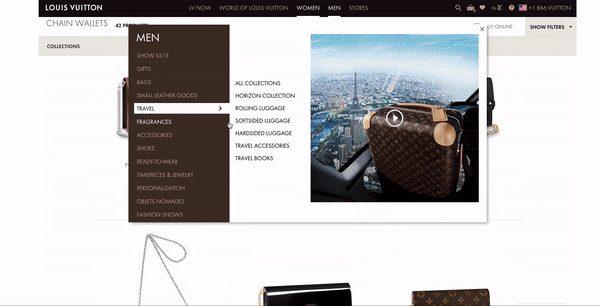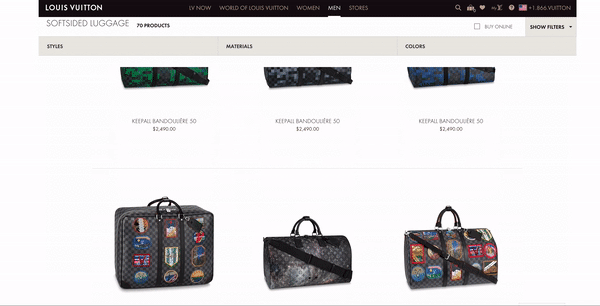 Capture d'écran de louisvuitton.com
Capture d'écran de louisvuitton.com
Stratégie
Comme lors de bon nombre de nos précédentes compétitions Kaggle, nous avons appliqué une tactique simple :
- Features simples, modèles complexes — construire des features simples et laisser les modèles ML saisir les interactions complexes entre elles.
- Miser sur la diversité — entraîner de nombreux modèles, puis assembler ceux qui performent le mieux au leaderboard tout en présentant le moins de chevauchement dans leurs erreurs.
- Travail d'équipe — chaque membre a une responsabilité bien définie : le Feature-Extractor, le Modeler et l'Integrator.
 Membres de l'équipe : Gad Benram, Seffi Cohen et Nurit C Inger
Membres de l'équipe : Gad Benram, Seffi Cohen et Nurit C Inger
Baseline
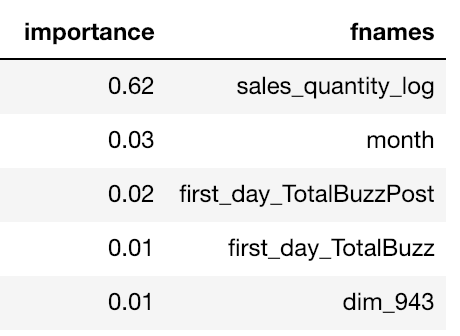
Avant même de regarder les données, nous nous sommes hissés sur les épaules de géants en utilisant le script baseline fourni par l'équipe Kaggle Days, qui incluait de nombreuses features. Nous avons exécuté un simple modèle Random Forest de 100 arbres maximum sur l'ensemble des données d'entraînement, juste pour évaluer l'importance de chaque feature. Le résultat a été une véritable surprise : le log des ventes des 7 premiers jours obtenait un score d'importance 20 fois supérieur à celui de toutes les autres features. Cette information nous a permis de maîtriser, dans une certaine mesure, la variance des modèles générés.
Formuler la question métier
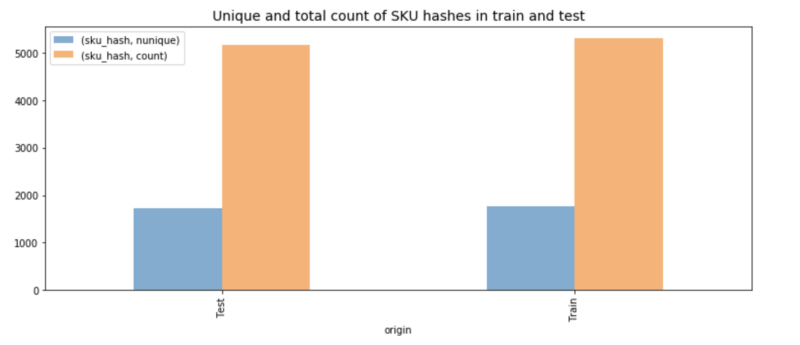
En explorant les données, nous avons constaté que leur découpage avait été particulièrement bien pensé. Le jeu d'entraînement comptait environ 1 700 produits uniques, tandis que le jeu de test contenait à peu près le même nombre de produits, mais différents. Cela nous a amenés à formuler le problème ainsi : si un produit donné — disons un bracelet pour femme — a été vendu x fois la première semaine après son lancement, puis m1, m2, m3 fois lors des mois suivants, combien d'unités vendra-t-on pour un article similaire ?
Mettre les tendances de côté — les données étant relatives à la première semaine de lancement et n'incluant pas le mois grégorien, nous avons négligé les tendances saisonnières et prêté moins d'attention aux tendances des réseaux sociaux. Au final, tout se ramenait à la question de la similarité produit. Il convient de noter que Mikel Bober-Irizar est parvenu à estimer la baisse relative des ventes durant la période de test, améliorant ainsi son score via une technique que nous appelons MLE — Maximum Leaderboard Estimation.
Comment modéliser la similarité produit
- Catégories — les produits avaient été classés par des experts humains dans différents types, comme la maroquinerie ou les sacs du quotidien. Ces features se sont révélées extrêmement précieuses pour comprendre la similarité entre les ventes de produits différents. Elles reflètent non seulement la façon dont un humain perçoit ces articles de manière passive, mais elles influencent aussi activement les ventes, puisqu'elles déterminent la position de l'article sur le site et la manière dont il est présenté aux clients.
- Texte — caractérisation de la feature à partir de son texte, en appliquant TF-IDF et PCA sur les features.
- Vecteurs d'image — les features d'image ont été extraites via la Vision API de Google. Cette API s'appuie sur des réseaux de neurones entraînés sur des datasets très génériques comme ImageNet — totalement inadaptés pour distinguer deux sacs à main de luxe au style décontracté. Nous avons donc écarté ces features.
- Click-through rate — les données de trafic du site incluaient les vues de pages et les clics sur les articles. Nous en avons extrait le taux de clic moyen, utilisé comme feature.
Modèles
Les données comportant des features catégorielles précieuses, il était essentiel d'utiliser une bibliothèque capable d'exploiter efficacement ce type de features. XGBoost ne dispose pas d'un mécanisme natif pour les features catégorielles, contrairement à LightGBM et Catboost. Catboost prenait trop de temps à traiter ; nous avons donc finalement opté pour LightGBM avec GBDT et Random Forest comme méthodes de boosting. Les réseaux de neurones, eux, n'ont pas réussi à converger en raison de la quantité de données relativement faible.
Alors, pourquoi parle-t-on d'overfitting ?
Si nous avions conseillé LVMH sur la manière d'augmenter ses ventes, nous aurions adopté une approche sensiblement différente. Par exemple, LVMH pourrait réaliser des tests A/B sur les features les plus importantes — comme la catégorisation ou les descriptions textuelles des produits — afin de vérifier si leur enrichissement aurait un impact sur les ventes. Néanmoins, lorsqu'on vise à remporter une compétition Kaggle, notre seul objectif est d'ajuster au mieux nos prédictions au jeu de test.
Machines et environnements
Tout le code tournait sur une Google Cloud Deep Learning VM préemptible, avec une instance n1-highmem-8 (8 vCPU, 52 Go de RAM, 0,1 USD/h). La machine était hébergée dans la région us-central, ce qui lui garantissait une haute disponibilité aux heures de la compétition, puisque nous étions en Europe.
L'expérience
Kaggle est une plateforme formidable pour partager ses connaissances et se mesurer à des compétitions variées et exigeantes ; Kaggle Days y ajoute une dimension essentielle : l'échange en personne. Nous avons passé un moment formidable à rencontrer d'autres data scientists du monde entier et à constater que nous partageons tous un même rêve : overfitter le jeu de test.
L'équipe au travail pendant la compétition
Code du notebook ici sur Github | Profil Kaggle : Gad Benram