
Kaggle Days è (quasi) ufficialmente l'evento più interessante per incontrare, imparare e confrontarsi con i migliori data scientist del mondo. Ed ecco come l'abbiamo vinto.
A gennaio 2019 Parigi ha ospitato la seconda edizione di Kaggle Days. Oltre 200 data scientist da tutto il mondo si sono riuniti per imparare, scambiare conoscenze e infine sfidarsi in una competizione Kaggle in aula della durata di 11 ore, svoltasi nel corso della conferenza. Questo articolo racconta la nostra soluzione, che ci è valsa il terzo posto.
Prevedere le vendite dei prodotti di lusso di LMVH
Ai partecipanti sono stati forniti i dati dei primi sette giorni dei prodotti Louis Vuitton dopo il lancio su www.louisvuitton.com. L'obiettivo era prevedere le vendite per ciascuno dei tre mesi successivi al lancio. Tra i dati aggiuntivi figuravano descrizioni dei prodotti, statistiche di vendita, social media, navigazione del sito e immagini.
 Schermata da louisvuitton.com
Schermata da louisvuitton.com
Strategia
Come in molte delle competizioni Kaggle a cui abbiamo partecipato in passato, abbiamo seguito una tattica semplice:
- Feature semplici, modelli complessi — costruire feature semplici e lasciare che siano i modelli ML a "capire" le interazioni complesse fra di esse.
- Puntare sulla diversità — addestrare molti modelli e mettere in ensemble quelli con le migliori prestazioni in classifica e con la minor sovrapposizione di errori.
- Gioco di squadra — ogni membro del team ha un ruolo ben preciso: il Feature-Extractor, il Modeler e l'Integrator.
 I membri del team: Gad Benram, Seffi Cohen e Nurit C Inger
I membri del team: Gad Benram, Seffi Cohen e Nurit C Inger
Baseline
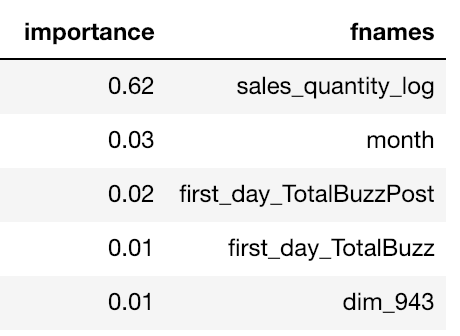
Prima ancora di mettere mano ai dati, ci siamo messi sulle spalle dei giganti partendo dallo script di baseline messo a disposizione dal team di Kaggle Days, che includeva già numerose feature. Abbiamo lanciato un semplice modello Random Forest con non più di 100 alberi sull'intero training set, giusto per verificare il peso di ciascuna feature. Il risultato è stato sorprendente: il logaritmo delle vendite dei primi 7 giorni ha ottenuto un punteggio di importanza 20 volte superiore rispetto a tutte le altre feature. Questa informazione ci ha permesso di tenere sotto controllo, almeno in parte, la varianza dei modelli generati.
Come abbiamo impostato il problema di business
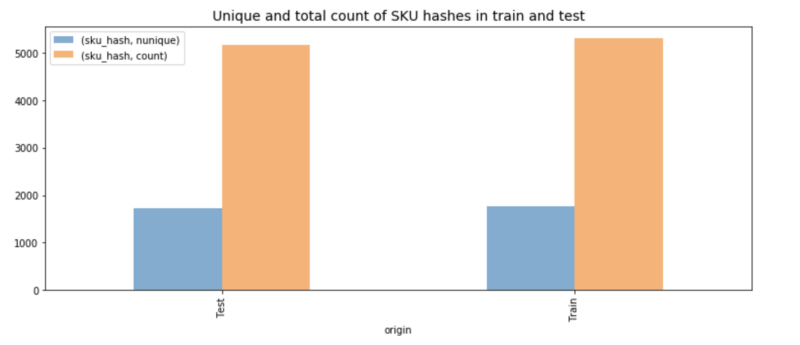
Scavando nei dati, ci siamo accorti che lo split era stato fatto bene. Il training set contava circa 1700 prodotti unici, mentre il test set ne includeva quasi altrettanti, ma diversi. Questo ci ha portato a riformulare il problema così: dato un prodotto specifico, ad esempio un bracciale da donna, venduto x volte nella prima settimana dopo il lancio e in quantità m1, m2, m3 nei mesi successivi, quante unità si venderanno di un articolo simile?
Trend a parte: poiché i dati erano relativi alla prima settimana di lancio e non comprendevano il mese del calendario gregoriano, abbiamo trascurato la stagionalità e dato meno peso ai trend sui social media. In sostanza, tutto si riduceva a una questione di similarità tra prodotti. Vale la pena ricordare che Mikel Bober-Irizar è riuscito a stimare la riduzione relativa delle vendite durante il periodo di test, migliorando così il punteggio con una tecnica che chiamiamo MLE — Maximum Leaderboard Estimation.
Come modellare la similarità tra prodotti
- Categorie — i prodotti erano stati classificati da esperti in diverse tipologie, come pelletteria e borse da giorno. Queste feature si sono rivelate preziosissime per cogliere la similarità tra le vendite di prodotti diversi. Non solo riflettono il modo in cui un essere umano percepisce passivamente questi articoli, ma ne influenzano attivamente le vendite, perché determinano la posizione dell'articolo sul sito e il modo in cui viene presentato ai clienti.
- Testo — caratterizzazione delle feature a partire dal testo, applicando TF-IDF e PCA.
- Vettori delle immagini — le feature delle immagini sono state estratte tramite la Vision API di Google. Questa API si appoggia a reti neurali addestrate su dataset molto generici come ImageNet, del tutto inadatti a distinguere tra due borse a mano casual di lusso. Per questo motivo abbiamo deciso di ignorarle.
- Click-through rate — i dati di traffico del sito comprendevano visualizzazioni di pagina e clic sugli articoli. Da questi abbiamo ricavato il click-through rate medio, usandolo come feature.
Modelli
Visto che i dati contenevano feature categoriche di valore, era fondamentale usare una libreria in grado di sfruttarle in modo efficiente. XGBoost non dispone di un meccanismo nativo per le feature categoriche, a differenza di LightGBM e Catboost. Catboost richiedeva tempi di elaborazione troppo lunghi, così alla fine ci siamo affidati a LightGBM con GBDT e Random Forest come metodi di boosting. Le reti neurali, invece, non sono riuscite a convergere per via della quantità di dati relativamente ridotta.
Quindi, perché diciamo che si tratta di overfitting?
Se avessimo dovuto consigliare LMVH su come aumentare le vendite, avremmo seguito un approccio piuttosto diverso. Ad esempio, LMHV avrebbe potuto fare A/B test sulle feature più importanti, come la categorizzazione o le descrizioni testuali dei prodotti, per verificare se arricchirle avrebbe avuto un impatto sulle vendite. Tuttavia, quando l'obiettivo è vincere una competizione Kaggle, l'unica cosa che conta è far aderire il più possibile le previsioni al test set.
Macchine e ambienti
Tutto il codice è stato eseguito su una Google Cloud Deep Learning VM preemptible con un'istanza n1-highmem-8 (8 vCPU, 52 GB di RAM, 0,1 USD/ora). La macchina si trovava nell'area us-central, il che ci ha garantito un'elevata disponibilità durante le ore della competizione, visto che eravamo in Europa.
L'esperienza
Kaggle è già di per sé una piattaforma straordinaria per condividere conoscenze e mettersi alla prova in competizioni molto diverse e impegnative, ma Kaggle Days aggiunge a questa community un tassello importante: l'interazione di persona. È stato fantastico incontrare colleghi data scientist da tutto il mondo e scoprire che ci accomuna tutti un sogno: fare overfitting sul test set.
Il team al lavoro durante la competizione
Codice del notebook qui su Github | Profilo Kaggle: Gad Benram