
O Kaggle Days é (quase) oficialmente o evento mais interessante para conhecer, aprender e competir com os cientistas de dados mais talentosos do mundo. E foi assim que vencemos.
Em janeiro de 2019, Paris sediou a 2ª edição do Kaggle Days. Mais de 200 cientistas de dados do mundo todo se reuniram para aprender, trocar conhecimento e, claro, competir entre si numa competição Kaggle presencial de 11 horas durante a conferência. Este post descreve a nossa solução para a competição, que nos garantiu o 3º lugar.
Prevendo as vendas dos produtos de luxo da LMVH
Os participantes receberam dados dos sete primeiros dias de produtos da Louis Vuitton após o lançamento no www.louisvuitton.com. O objetivo era prever as vendas em cada um dos três meses seguintes ao lançamento. Os dados adicionais incluíam descrições dos produtos, estatísticas de vendas, redes sociais, navegação no site e dados de imagem.
 Captura de tela do louisvuitton.com
Captura de tela do louisvuitton.com
Estratégia
Como em várias competições anteriores no Kaggle, seguimos táticas simples:
- Features simples, modelos complexos — criar features simples e deixar que os modelos de ML "entendam" as interações complexas entre elas.
- Aposte na diversidade — treinar muitos modelos e fazer ensemble dos que tiveram melhor desempenho no leaderboard e a menor sobreposição de erros.
- Trabalho em equipe — cada integrante com uma responsabilidade bem definida: o Feature-Extractor, o Modeler e o Integrator.
 Integrantes do time: Gad Benram, Seffi Cohen e Nurit C Inger
Integrantes do time: Gad Benram, Seffi Cohen e Nurit C Inger
Baseline
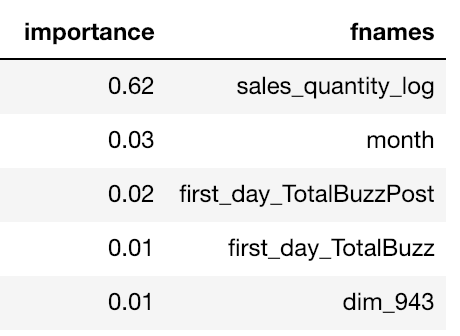
Antes mesmo de olhar para os dados, nos apoiamos em ombros de gigantes e usamos o script baseline do time do Kaggle Days, que já trazia diversas features. Rodamos um modelo simples de Random Forest com no máximo 100 árvores em todo o conjunto de treino, só para conferir a importância de cada feature. O resultado foi uma surpresa e tanto: o log das vendas dos primeiros 7 dias teve uma pontuação de importância 20 vezes maior do que todas as outras features. Essa informação nos permitiu controlar até certo ponto a variância dos modelos gerados.
Formulando a pergunta de negócio
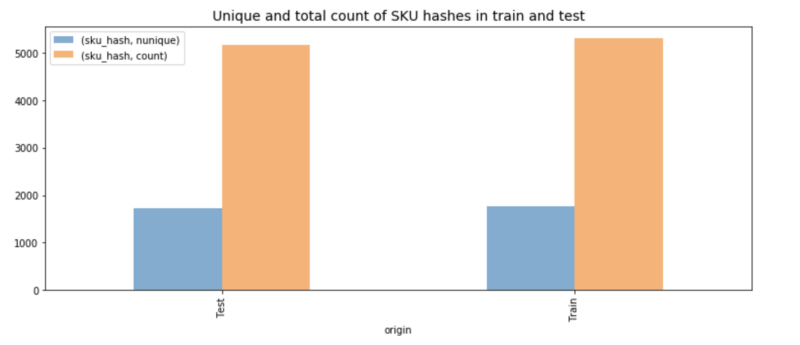
Ao mergulhar nos dados, percebemos que alguém tinha caprichado na divisão. O conjunto de treino tinha cerca de 1.700 produtos únicos, e o de teste praticamente a mesma quantidade, só que de produtos diferentes. Isso nos levou a encarar o problema assim: supondo que um produto específico, digamos uma pulseira feminina, vendeu x vezes na primeira semana após o lançamento e m1, m2, m3 nos meses seguintes, quanto será vendido de um item semelhante?
Ignorando tendências — como os dados eram relativos à primeira semana de lançamento e não traziam o mês do calendário gregoriano, deixamos de lado as tendências sazonais e demos pouca atenção às de redes sociais. No fim, tudo se resumiu à similaridade entre produtos. Vale destacar que Mikel Bober-Irizar conseguiu estimar a redução relativa de vendas durante o período de teste, melhorando a pontuação por meio de uma técnica que chamamos de MLE — Maximum Leaderboard Estimation.
Como modelar a similaridade entre produtos
- Categorias — os produtos foram categorizados por especialistas humanos em tipos como artigos de couro e bolsas para o dia a dia. Essas features foram extremamente valiosas para entender a similaridade entre as vendas de produtos diferentes. Além de refletirem como um humano percebe esses itens de forma passiva, elas também influenciam ativamente as vendas, já que determinam a posição do item no site e a forma como ele é apresentado aos clientes.
- Texto — caracterizar a feature pelo seu texto, aplicando TF-IDF e PCA sobre as features.
- Vetores de imagem — as features de imagem foram extraídas com a Vision API do Google. Essa API usa redes neurais treinadas em datasets bem genéricos, como o ImageNet — nada útil para distinguir duas bolsas casuais de luxo. Por isso, descartamos essas features.
- Click-through rate — os dados de tráfego do site incluíam visualizações de página e cliques nos itens. A partir disso, extraímos a taxa média de cliques (clickthrough rate) e a usamos como feature.
Modelos
Como os dados traziam features categóricas valiosas, era importante usar uma biblioteca capaz de aproveitá-las de forma eficiente. O XGBoost não tem um mecanismo nativo para features categóricas, diferente do LightGBM e do Catboost. O Catboost demorou demais para processar, então acabamos rodando o LightGBM com GBDT e Random Forest como métodos de boosting. As redes neurais não convergiram por causa da quantidade relativamente pequena de dados.
Então, por que dizemos que é overfitting?
Se estivéssemos prestando consultoria à LMVH sobre como aumentar as vendas, teríamos adotado uma abordagem um pouco diferente. Por exemplo, a LMHV poderia fazer testes A/B nas features mais importantes, como a categorização ou as descrições textuais dos produtos, para avaliar se incrementá-las afetaria as vendas. Mas, quando o objetivo é vencer uma competição no Kaggle, a única meta é ajustar nossas previsões da melhor forma possível ao conjunto de teste.
Máquinas e ambientes
Todo o código rodou em uma Google Cloud Deep Learning VM preemptiva, com instância n1-highmem-8 (8 vCPUs, 52GB de RAM, US$ 0,10/h). A máquina ficava na região us-central, o que garantiu alta disponibilidade durante o horário da competição, já que estávamos na Europa.
Experiência
O Kaggle já é uma plataforma incrível para compartilhar conhecimento e se desafiar em competições diversas e difíceis, mas o Kaggle Days adiciona uma camada importante a essa comunidade: a interação presencial. Foi sensacional conhecer outros cientistas de dados do mundo todo e descobrir que todos compartilhamos um sonho em comum: fazer overfit nos dados de teste.
O time trabalhando durante a competição
Código do notebook aqui no Github | Perfil no Kaggle: Gad Benram