ご存じの方も多いと思いますが、DoiT InternationalはreOptimize(現在はDoiT Cloud Intelligence™の一部)の開発を担っています。reOptimizeはGoogle Cloud Platform向けのコスト可視化・最適化SaaSです。
reOptimizeを使えば、Google Cloud Platformの請求状況をリアルタイムに把握しつつ、予算管理やコスト配分の設定、各種コスト最適化施策の検討まで一気通貫で行えます。
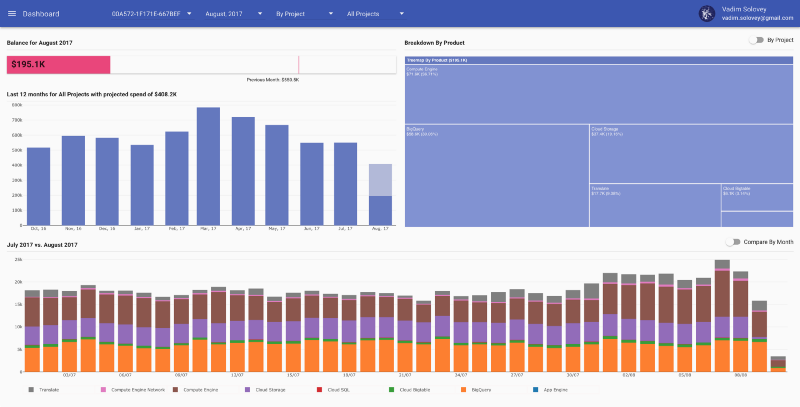
reOptimizeのダッシュボード
初期から備えている機能のひとつが、月末時点の請求額予測です。reOptimizeのダッシュボードでは次のように表示されます。
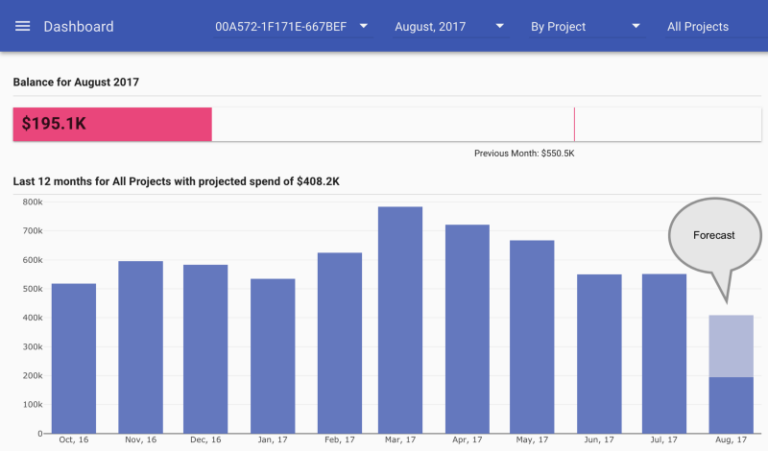
Google Cloud Platformの請求予測
当初の予測モデルはごく単純な線形回帰でした。現時点の利用額と日付をもとに、支出が線形に伸びると仮定して月末値を外挿するという仕組みです。Google Compute EngineのSustained Discountsを織り込むなど多少の工夫は加えていましたが、それでも極めて素朴で粗い手法でした。
あいにく、クラウドサービスの利用は累積的で、クラウド支出が線形に推移することはまずありません。月の長短、休暇シーズン、マーケティング施策など、季節性をもたらす要因は数え切れないほどあります。このモデルの予測値は実態と大きくずれることが多く、二乗平均平方根誤差(RMSE)を計算するとおよそ900という結果でした。
多くのお客様がGoogle Cloud Platformの支出予測にreOptimizeを活用していらっしゃるため、私たちは精度向上を目指して機械学習ベースのモデル開発に取り組みました。
採用したのは、機械知能向けのオープンソースライブラリであるTensorFlowです。なかでも、TensorFlowのマネージドサービスであるGoogle CloudMLを使えば、スケーリング、デプロイ、監視といったあまり面白みのない運用作業に手を取られずに済みます ;-)
本プロジェクトは大きく次の3つのパートで構成されます。
- モデル学習用の過去データを準備する
- 予測モデルを学習させる
- モデルをデプロイし、reOptimizeから利用できるようにする
これらは日々新しい請求データが届くたびに、自動かつ反復的に実行する必要があります。
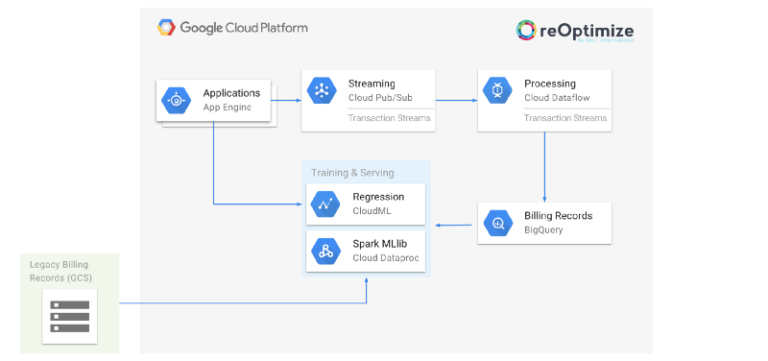
reOptimizeの機械学習ベースの予測アーキテクチャ
学習データの準備
Google Cloud Billing APIは請求レコードをさまざまな出力先にエクスポートでき、その一つがGoogle BigQueryです。私たちは予測モデルの学習データソースとして、このBigQueryのテーブルを利用しています。
テーブルは次のカラムで構成されています。
project.id - GCPプロジェクトIDproduct - GCPサービス名(BigQuery、Compute Engineなど)start_time - この請求行の日時cost - 米ドル建てのコストcredits.name - 該当するクレジットの名称(繰り返しフィールド)credits.amount - 該当するクレジットの金額(繰り返しフィールド)学習プロセスを最適化するため、生データはTensorFlowに適した形式へ変換します。これはデータ形式そのものと、データの意味の両面に及びます。
TensorFlowは複数のフォーマットに対応していますが、標準はTFRecord形式と呼ばれるものです。この形式の読み書き用には豊富な組み込みユーティリティが用意されています。
データの中身についても、DNNに適した値へ変換する必要があります。DNN(Deep Neural Network、ディープニューラルネットワーク)とは、機械学習で用いられる数理モデルの一種で、人間の脳の仕組みを参考に構築されたものです。
DNNは数値以外の入力、それも意味のある実数値以外の入力には弱いという特徴があります。たとえば製品名やプロジェクト名は単独では何の意味も持たず、年や月の値も同様です。一方で、日付の数値やコストにはそれ自体に意味があります。また、生のコスト行をそのまま投入するのも得策ではありません。サンプルごとに目標値を与える必要があるためです。
そこで、BigQueryのデータをDNNモデルに適した形へと変換していきます。
サンプルの定義として最適と考えたのは、製品とプロジェクトごとに日次で集計し、月初からその日までのコスト合計を求める方法です。さらに、その月における当該製品・プロジェクトの総コストを付与し、これを学習時の目標値として使います。最後に、製品名とプロジェクト名は事前に整数へマッピングしておく必要があります。
本ケースでは、各サンプルにプロジェクト、製品、日、月初からのコスト累計、そして総コストを含めます。さらに、DNNがデータをきちんと理解できるよう、有用ではあるもののDNNが自力で算出するのは難しい補助情報を付け加えます。
たとえばその月の日数は、総コストに影響しうる定数です。これを事前に「計算」して与えておけば、DNNにとっての時間と複雑さを節約できます。同様に、累計コストを経過日数で割れば1日あたりのコスト比率も求められます。
もう一つ有用なのが、製品・プロジェクトごとの平均比率と平均総コストです。これらは人間が月額請求を見積もるときにも使う値でしょう。BigQueryでプロジェクト・製品ごとの平均値を返すマッピングテーブルを簡単に作成できるため、私たちはこれを静的なルックアップテーブルとして用い、サンプルに付加情報として組み込みました。
このほかにも、推定線形総コスト(比率 * 月の日数)など、DNNが活用できる比率をいくつか算出しています。
データが揃ったら、サンプルとそのラベル値(目標値)を1件ずつモデルに投入します。サンプルの入力値から総コストを予測できるようにモデルを学習させるわけです。これにより、後ほどプロジェクト・製品ごとの現時点の支出と日付をモデルに渡せば、月末の総コストを予測できるようになります。
データが整ったところで、現行モデルとの比較評価のしくみも用意しました。変換済みデータを使って現行コードと同じ単純な線形回帰を計算し、各サンプルについて予測値から実際の合計を引いて二乗、その値を全サンプルで平均し、平方根を取ったものがRMSEです。結果はおよそ900でした。
この段階のデータを眺めると、線形には到底推移していないことが一目瞭然でした。こうしたデータをそのまま予測するDNNを構築するのは至難の業ですが、関連性が事前にわかっている計算済みの値をネットワークに与えることで、よりシンプルなDNNでも十分機能させられます。そのためには、データを変換するだけでなく、補強する必要がありました。
有効そうなのは、月初からの累計コストと月初からの経過日数の比率を入力として与えることです。この値は月単位や全体での平均も取れるため、支出傾向に関するより役立つ情報を得られます。
もちろん、前月までの総コスト履歴をDNNに知らせるのも有効と考えられるため、月ごとの平均総コストと、全体での平均総コストも追加しました。
こちらが私たちが構築した前処理関数です。
続いて、これらをまとめて学習可能なTFRecord形式にパッケージ化します。幸い、これを支援するパッケージがすでに存在します。Pythonのtensorflow-transformパッケージは、TensorFlowとApache Beamを組み合わせて大量のデータを処理・変換し、TFRecordファイルへ書き出してくれます。
tensorflow-transformのもう一つの利点は、データ処理用のTensorFlowグラフを生成し、それをBeamパイプライン上で実行する点にあります。生成したグラフは予測時にもそのまま使えるため、予測の前にデータを別途変換する必要がなく、変換処理が自動的に行われます。
前処理スクリプトの中核では、次のApache Beamパイプラインを実行します。
get_data_from_bq関数は、上で示したSQLクエリでBigQueryからデータを読み取ります。
続いてAnalyzeAndTransformDatasetで処理を実行します。AnalyzeAndTransformDatasetには、変換グラフを定義するための前処理関数が必要です。変換後のデータはTFRecord形式で、学習用とテスト用の2つのファイルセットに書き出されます。
データに加えて、このパイプラインはモデルのメタデータ(生入力のメタデータ、変換後データのメタデータ、変換関数のグラフ)も保存します。これらはのちにモデルの学習で使われます。
モデルの学習
データが揃ったら、次のステップは準備したデータを使ってモデルを学習させることです。
私たちはシンプルなDNNを採用し、TensorFlowのDNNRegressorクラスで学習させることにしました。前処理ステップでtensorflow-transformが生成したメタデータは、ここで学習・テスト・サービング用の入力関数を作るために使います。
最後に、TensorFlowのcontrib.learn.Experimentを用いて学習と評価をまとめて制御します。
そのために、experimentを生成する関数を定義します。
そして、その関数を使ってexperimentを実行します。
このプロセスの成果物として、学習済みモデルを格納したフォルダが得られます。これを後ほどGoogle CloudMLにデプロイし、実際の予測に利用します。
モデルのデプロイ
reOptimizeで予測結果を使うには、当然ながらアプリケーションからのAPIリクエストを受け、モデルの出力を返すインフラが必要です。
これを担うのが、TensorFlow Servingを利用するGoogle CloudMLです。TensorFlow Servingは、ローカルディスクやGCSバケットに保存された学習済みモデルを読み込み、推論結果を返します。Webやモバイルアプリから呼び出せるRESTful APIを公開する仕組みです。Google CloudMLはこれをさらに発展させ、サーバーレスでフルマネージドなサービングインフラを提供します。マシンの用意やオートスケール設定などを自前で行う必要はありません。
モデルの学習と保存が済んだら、gcloudコマンドラインでデプロイします。
$ gcloud ml-engine models create reoptimize --regions=us-east1$ gsutil -m cp -r job/model/export/Servo/... <MY_GCS_BUCKET_NAME>/model/<MODEL_VERSION_NAME>$ gcloud ml-engine versions create <MODEL_VERSION_NAME> --model reoptimize --runtime-version 1.2 --origin <MY_GCS_BUCKET_NAME>/model/<MODEL_VERSION_NAME>$ gcloud ml-engine versions set-default <MODEL_VERSION_NAME> --model reoptimizeこれで、デプロイしたモデルで予測を行うためのURLが生成されます。このURLは、Google CloudMLが用意するフルマネージドのバックエンドAPIサービスを指しています。
RESTコールを処理できるほか、次のようにgcloudコマンドラインツールからも呼び出せます。
gcloud ml-engine predict --format=json --model reoptimize --json-instances=data/predict.jsondata/predict.jsonファイルには、たとえば次のような内容を記述します。
結果は次のような形で返ってきます。
まとめ
機械学習でGoogle Cloud Platformの請求を予測するようにしたことで、フォーキャストの精度は格段に向上しました。季節性、価格モデルの変更、マーケティング施策など、無数のシグナルを(間接的に)織り込めるようになっています。
RMSEはおよそ900からわずか100程度まで下がり、予測の信頼性は大きく高まりました。お客様にも安心して頼っていただけるレベルです。
Google CloudML、Dataflow、BigQueryを活用したことで、reOptimizeの機械学習基盤はわずか数週間で実装できました。運用や保守ではなく、エンジニアリングそのものにより多くの時間を割けたことが大きな成果です。