Você talvez já saiba: a DoiT International é a engenharia por trás do reOptimize (hoje parte do DoiT Cloud Intelligence™) — SaaS de descoberta e otimização de custos para o Google Cloud Platform.
Com o reOptimize, você tem insights na hora sobre o faturamento do seu Google Cloud Platform, gerencia orçamentos, configura rateios de custo e explora diferentes estratégias de otimização.
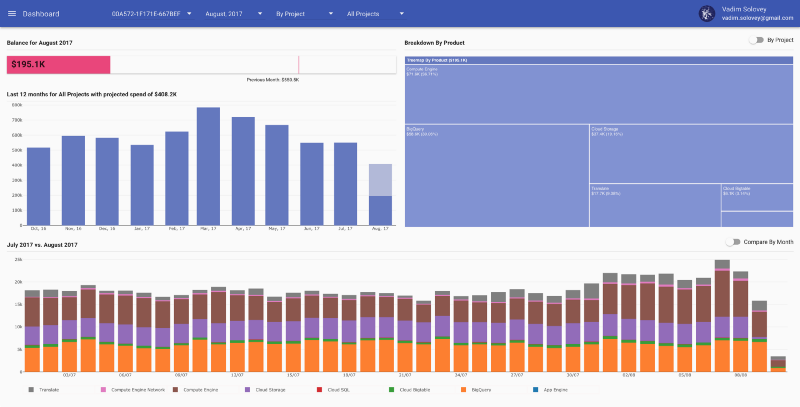
Dashboard do reOptimize
Um dos recursos que temos desde o primeiro dia é a estimativa de como sua conta mensal vai fechar. Veja como ela aparece no dashboard do reOptimize:
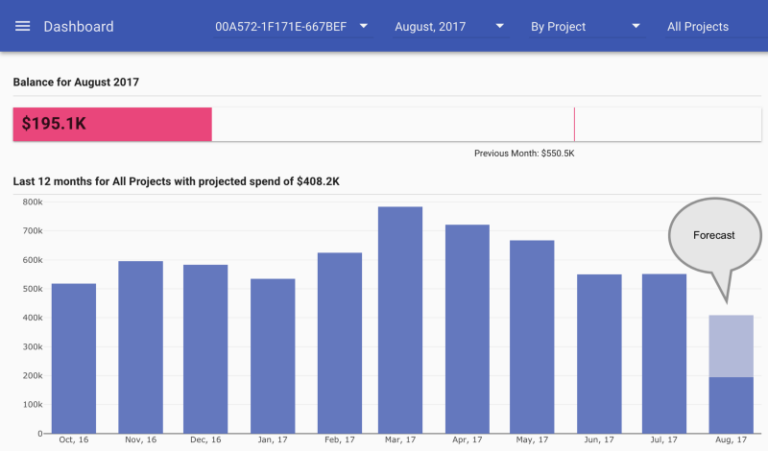
Previsão de faturamento do Google Cloud Platform
No começo, nosso modelo de estimativa usava uma regressão linear bem trivial — pegava o gasto atual e o dia do mês e extrapolava o valor partindo do princípio de que o gasto cresceria linearmente. Fizemos alguns ajustes, como considerar os Sustained Discounts do Google Compute Engine e outras coisas, mas ainda assim o modelo era bem ingênuo e simplista.
O problema é que serviços de nuvem são cumulativos e, em geral, o gasto com nuvem está longe de se comportar de forma linear. Há padrões de sazonalidade, como meses mais longos ou mais curtos, feriados, campanhas de marketing e muito mais! A estimativa desse modelo costumava ficar bem distante do real. Calculamos um desvio quadrático médio (RMSE) de ~900.
Como muitos clientes contam com o reOptimize para prever seus gastos no Google Cloud Platform, começamos a desenvolver um modelo baseado em Machine Learning para aumentar a precisão das nossas estimativas.
Naturalmente, optamos pelo TensorFlow — biblioteca open-source de Machine Intelligence — e, em especial, pelo Google CloudML, o serviço gerenciado do Google para TensorFlow. Assim, não precisaríamos lidar com escalonamento, deploy, monitoramento e outros encargos operacionais nem tão fascinantes ;-)
O projeto tem três grandes partes:
- Preparar os dados históricos para treinar o modelo
- Treinar um modelo de previsão
- Fazer o deploy do modelo para o reOptimize usar
Tudo isso precisa rodar de forma automática e iterativa, à medida que novos dados de faturamento chegam diariamente.
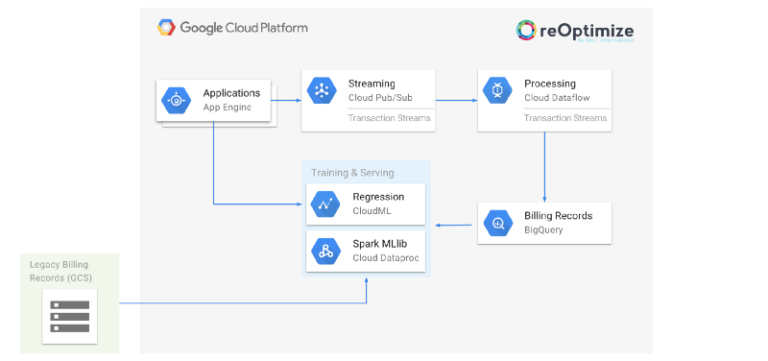
Arquitetura de previsão baseada em Machine Learning do reOptimize
Preparando os dados de treinamento
A Google Cloud Billing API consegue exportar registros de faturamento para diversos destinos, e um deles é o Google BigQuery. Usamos uma tabela do BigQuery como fonte de dados para treinar nosso modelo de previsão.
A tabela tem as seguintes colunas:
project.id - O ID do projeto GCPproduct - O nome do serviço GCP (ex.: BigQuery, Compute Engine, etc.)start_time - A data e hora desta linha de faturamentocost - O custo em dólares americanoscredits.name - Um campo repetido com nomes dos créditos relevantescredits.amount - Um campo repetido com o valor dos créditos relevantesPara otimizar o treinamento, queremos transformar os dados brutos em um formato mais adequado ao TensorFlow. Isso vale tanto para o formato quanto para a semântica dos dados.
O TensorFlow suporta vários formatos, mas o padrão se chama TFRecords. Existem muitos utilitários nativos para ler e escrever dados nesse formato.
A semântica dos dados em si precisa ser convertida em valores mais adequados a uma DNN. A DNN, ou Deep Neural Network, é um tipo de modelo matemático usado em machine learning, inspirado no funcionamento do cérebro humano.
Uma DNN não funciona bem com entradas que não sejam números — e, de preferência, números com significado real. Nomes de produtos e de projetos, por exemplo, não significam nada por si só, assim como valores de ano e mês. Já o valor numérico do dia tem esse significado, assim como o custo. Além disso, alimentar as linhas de custo brutas não seria produtivo, pois precisamos fornecer um valor-alvo por amostra.
Estamos transformando os dados do BigQuery em algo mais adequado ao nosso modelo DNN.
A melhor forma que encontramos de definir as amostras foi criar uma agregação diária por produto e projeto, com a soma dos custos do início do mês até aquele dia. Também precisamos somar o custo total daquele produto e projeto no mês e usar esse número como valor-alvo para o treinamento. Por fim, os nomes de produto e projeto precisam ser primeiro mapeados para inteiros.
No nosso caso, cada amostra inclui projeto, produto, dia, custo parcial (desde o início do mês) e custo total. Para que a DNN consiga entender os dados, queremos enriquecer a amostra com informações adicionais que possam ser úteis, mas que sejam difíceis de a DNN calcular sozinha.
O número de dias do mês atual é uma constante arbitrária que pode afetar o custo total. Podemos "calcular" isso para a DNN, economizando tempo e complexidade. Também dá para calcular a razão de custo por dia, dividindo o custo parcial pelo dia atual.
Outro valor útil é a razão média e o custo total médio para o produto e projeto — números que provavelmente um humano usaria ao tentar prever a conta do mês. É fácil pedir ao BigQuery uma tabela de mapeamento com esses valores médios por projeto e produto, e usamos essa tabela para criar uma lookup table estática que enriquece as amostras.
Calculamos algumas outras razões para fornecer mais informação à DNN, como o custo total linear estimado (ou seja, razão * dias do mês).
Com os dados em mãos, alimentamos as amostras uma a uma, junto com o valor de label da amostra. Vamos treinar o modelo para prever o custo total a partir dos valores de entrada da amostra. Assim, depois conseguimos usar o modelo para alimentar o gasto e a data atuais por projeto e produto e prever o custo total no fim do mês.
Com os dados prontos, queríamos uma forma de comparar o novo modelo com o que temos hoje. Usamos os dados transformados para calcular a regressão linear simples feita pelo nosso código atual. Cada amostra foi calculada; em seguida, subtraímos o total esperado da previsão, elevamos o valor ao quadrado e calculamos a média desse valor para todas as amostras. A raiz quadrada desse valor é o RMSE. Chegamos a um RMSE de ~900.
Olhando os dados nesse estágio, ficou óbvio que eles não tinham nenhum comportamento linear. Criar uma DNN que conseguisse prever esse tipo de dado seria muito difícil — mas dá para construir uma DNN mais simples alimentando a rede com alguns valores calculados que já sabemos serem relevantes. Para isso, queremos enriquecer e também transformar os dados.
Algo que parece útil é alimentar um valor com a razão entre o custo atual desde o início do mês e os dias decorridos desde o início do mês. Esse valor também pode ser tirada a média ao longo de cada mês, e até globalmente, para fornecer informações mais relevantes sobre o comportamento do gasto.
E, claro, pode ajudar a DNN conhecer o histórico de custo total dos meses anteriores — então adicionamos a média do custo total de cada mês e também uma média global do custo total.
Esta é a função de pré-processamento que construímos:
Em seguida, queremos empacotar tudo no formato TFRecord, pronto para o treinamento. Felizmente, já existe um pacote que ajuda nisso. O pacote Python tensorflow-transform combina TensorFlow e Apache Beam para processar grandes volumes de dados, transformá-los e gravá-los em arquivos TFRecord.
Outra vantagem do tensorflow-transform é que ele cria um grafo do TensorFlow para processar os dados e o executa por meio de um pipeline Beam — ou seja, dá para usar esse mesmo grafo depois na previsão, fazendo todas essas transformações nos dados automaticamente, sem precisar transformá-los antes de enviar para a previsão.
No coração do script de pré-processamento, rodamos o pipeline do Apache Beam:
A função get_data_from_bq lê os dados do BigQuery usando a consulta SQL mostrada acima.
Em seguida, ela usa AnalyzeAndTransformDataset para realizar o processamento em si. O AnalyzeAndTransformDataset precisa de uma função de pré-processamento para definir o grafo de transformação. Os dados transformados são gravados no formato TFRecord em dois conjuntos de arquivos: um para treinamento e outro para teste.
Além dos dados, o pipeline também salva os metadados do modelo, incluindo os metadados de entrada brutos, os metadados dos dados transformados e o grafo da função de transformação. Tudo isso é usado depois no treinamento do modelo.
Treinando o modelo
Com os dados prontos, o próximo passo é treinar um modelo com o que acabamos de preparar.
Decidimos usar uma DNN simples e treiná-la com a classe DNNRegressor do TensorFlow. Os metadados criados pelo tensorflow-transform na etapa de pré-processamento agora são usados para criar funções de entrada para treinamento, teste e serving.
Por fim, usamos o contrib.learn.Experiment do TensorFlow para coordenar o treinamento e a avaliação.
Para isso, definimos uma função que gera o experimento:
E em seguida a usamos para rodar o experimento:
O resultado desse processo é uma pasta com o modelo salvo, que mais tarde podemos publicar no Google CloudML para fazer previsões de verdade.
Fazendo o deploy do modelo
Para o reOptimize usar as previsões, é claro que precisamos de uma infraestrutura que atenda às requisições de API vindas da aplicação e devolva a saída do modelo.
O Google CloudML faz exatamente isso com o TensorFlow Serving. O TensorFlow Serving usa um modelo treinado salvo em disco local ou em um bucket GCS para executar o modelo e devolver a saída. Ele expõe uma API RESTful que pode ser usada por qualquer cliente web ou mobile. O Google CloudML vai além, oferecendo uma infraestrutura de serving serverless e totalmente gerenciada para o seu modelo, sem que você precise configurar máquinas, autoscale e por aí vai.
Depois de treinar e salvar o modelo, fazemos o deploy usando a linha de comando gcloud.
$ gcloud ml-engine models create reoptimize --regions=us-east1$ gsutil -m cp -r job/model/export/Servo/... <MY_GCS_BUCKET_NAME>/model/<MODEL_VERSION_NAME>$ gcloud ml-engine versions create <MODEL_VERSION_NAME> --model reoptimize --runtime-version 1.2 --origin <MY_GCS_BUCKET_NAME>/model/<MODEL_VERSION_NAME>$ gcloud ml-engine versions set-default <MODEL_VERSION_NAME> --model reoptimizeIsso cria uma URL que pode ser usada para fazer previsões com o modelo. A URL aponta para um serviço de API de backend totalmente gerenciado, criado pelo Google CloudML.
Ele responde a chamadas REST e também pode ser usado pela ferramenta de linha de comando gcloud, assim:
gcloud ml-engine predict --format=json --model reoptimize --json-instances=data/predict.jsonO arquivo data/predict.json contém informações como esta:
E os resultados ficam parecidos com isto:
Resumo
Com o uso de machine learning para prever as contas do Google Cloud Platform, nossas previsões ficaram muito mais precisas. Elas levam em conta (de forma indireta) uma enorme quantidade de sinais, como sazonalidade, mudanças nos modelos de preço, campanhas de marketing e por aí vai.
Nosso RMSE caiu de ~900 para apenas ~100, então as previsões estão muito mais confiáveis e os clientes podem realmente contar com elas.
Usando Google CloudML, Dataflow e BigQuery, conseguimos implementar a infraestrutura de machine learning no reOptimize em apenas algumas semanas, investindo o tempo em engenharia, e não em operações ou manutenção.