Come forse già saprete, DoiT International è il motore ingegneristico dietro reOptimize (oggi parte di DoiT Cloud Intelligence™), il SaaS di Cost Discovery e Optimization per Google Cloud Platform.
Con reOptimize potete ottenere insight immediati sul billing di Google Cloud Platform, gestire i budget, configurare l'allocazione dei costi ed esplorare diverse strategie di ottimizzazione.
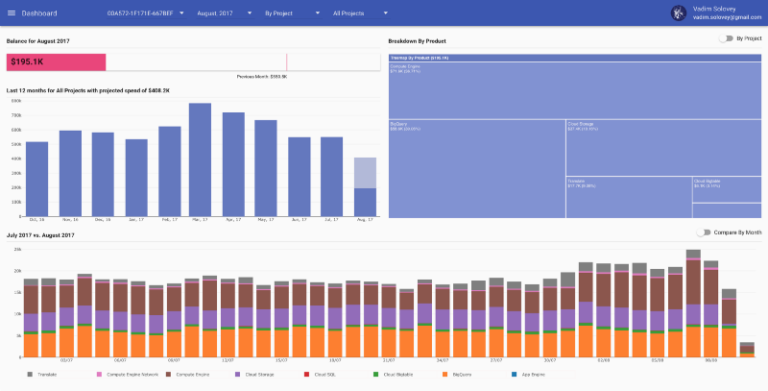
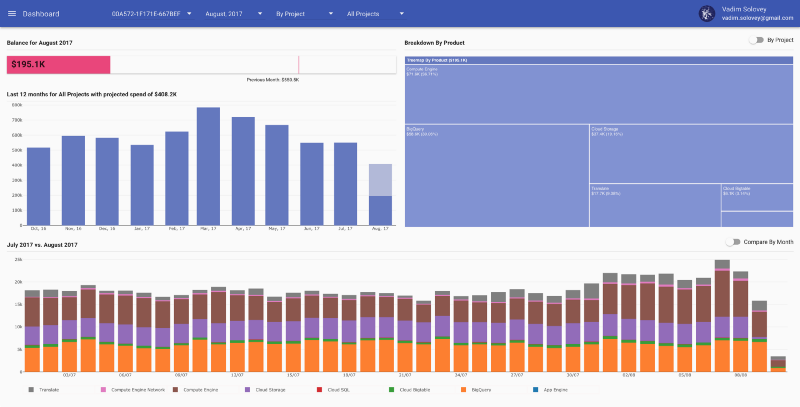
Dashboard di reOptimize
Una delle funzionalità presenti fin dal primo giorno è la stima dell'importo della bolletta mensile a fine mese. Ecco come si presenta nella dashboard di reOptimize:
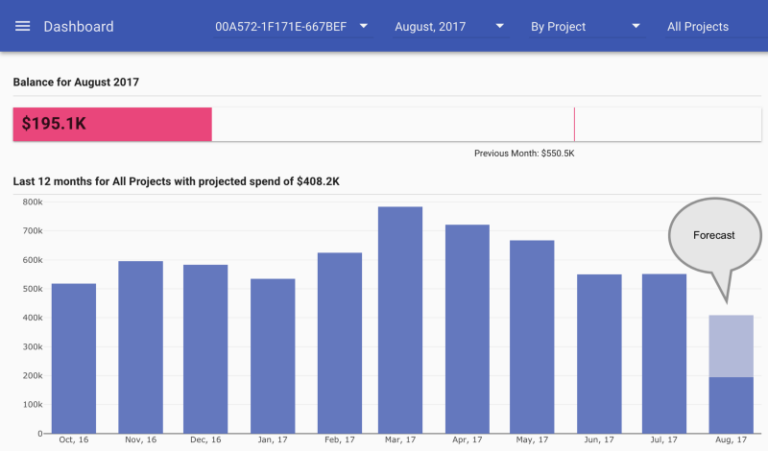
Previsione di billing per Google Cloud Platform
All'inizio il nostro modello di stima si basava su una regressione lineare molto semplice: prendeva la spesa attuale e il giorno del mese ed estrapolava il valore presupponendo una crescita lineare della spesa. Avevamo introdotto qualche correttivo, come tenere conto dei Sustained Discounts di Google Compute Engine e di altri fattori, ma il modello restava ingenuo e semplicistico.
Purtroppo i servizi cloud sono cumulativi e, in generale, la spesa cloud non si comporta affatto in modo lineare. Ci sono fenomeni di stagionalità: mesi più lunghi o più corti, periodi di vacanza, campagne marketing e molto altro ancora. La stima fornita da questo modello risultava spesso decisamente lontana dalla realtà. Abbiamo calcolato un root-mean-square deviation (RMSE) di circa 900.
Poiché molti dei nostri clienti si affidano a reOptimize per prevedere la spesa su Google Cloud Platform, abbiamo iniziato a sviluppare un modello basato su Machine Learning per migliorare l'accuratezza delle stime.
La scelta è caduta naturalmente su TensorFlow, una libreria software open source per la Machine Intelligence, e in particolare su Google CloudML, il servizio gestito di Google per TensorFlow, in modo da non dover pensare a scaling, deployment, monitoraggio e altri oneri operativi poco entusiasmanti ;-)
Il progetto si articola in tre parti principali:
- Preparare i dati storici per addestrare il modello
- Addestrare un modello predittivo
- Effettuare il deployment del modello in modo che possa essere utilizzato da reOptimize
Tutte queste operazioni devono essere eseguite automaticamente in modo iterativo, man mano che ogni giorno arrivano nuovi dati di billing.
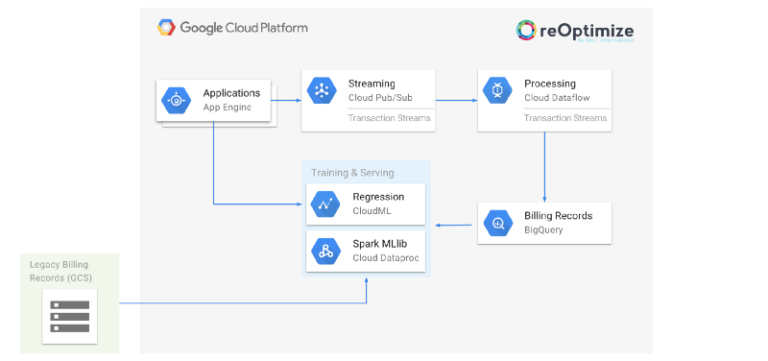
Architettura di previsione basata su Machine Learning di reOptimize
Preparazione dei dati di training
La Google Cloud Billing API consente di esportare i record di billing verso diverse destinazioni, tra cui Google BigQuery. Usiamo proprio una tabella BigQuery come fonte dati per addestrare il modello predittivo.
La tabella contiene le seguenti colonne:
project.id - L'ID del progetto GCPproduct - Il nome del servizio GCP (ad es. BigQuery, Compute Engine, ecc.)start_time - Data e ora di questa riga di billingcost - Il costo in dollari USAcredits.name - Un campo ripetuto con i nomi dei crediti pertinenticredits.amount - Un campo ripetuto con l'importo dei crediti pertinentiPer ottimizzare il processo di training vogliamo trasformare i dati grezzi in un formato più adatto a TensorFlow, intervenendo sia sul formato sia sulla semantica dei dati.
TensorFlow supporta diversi formati, ma quello standard è il TFRecords. Esistono molte utility integrate per leggere e scrivere dati in questo formato.
Anche la semantica dei dati va convertita in valori più adatti a una DNN. La DNN, o Deep Neural Network, è un modello matematico utilizzato nel machine learning, ispirato al funzionamento del cervello umano.
Una DNN non lavora bene con input che non siano numeri, e preferibilmente numeri dotati di un significato concreto. Per esempio, i nomi dei prodotti e dei progetti non hanno di per sé alcun significato, e lo stesso vale per i valori di anno e mese. Il valore numerico del giorno, invece, ha un significato, così come il costo. Inoltre, dare in pasto al modello le righe di costo grezze non sarebbe produttivo, perché serve un valore target per ciascun campione.
Trasformiamo quindi i dati provenienti da BigQuery in qualcosa di più adatto al nostro modello DNN.
Il modo migliore di definire i campioni, secondo noi, è creare un'aggregazione giornaliera per prodotto e progetto, con la somma dei costi dall'inizio del mese fino a quel giorno. Va inoltre aggiunto il costo totale per quel prodotto e progetto in quel mese, da usare come valore target su cui addestrare il modello. Infine, i nomi di prodotti e progetti devono essere prima mappati in numeri interi.
Nel nostro caso, ogni campione comprende progetto, prodotto, giorno, costo parziale (dall'inizio del mese) e costo totale. Affinché la DNN sia in grado di interpretare i dati, vogliamo arricchire il campione con informazioni aggiuntive che potrebbero risultare utili ma che la DNN farebbe fatica a calcolare da sola.
Il numero di giorni del mese in corso è una costante arbitraria che può influire sul costo totale. Possiamo "calcolarla" per la DNN, risparmiando tempo e complessità. Possiamo anche calcolare il rapporto di costo giornaliero dividendo il costo parziale per il giorno corrente.
Un altro valore utile sarebbe il rapporto medio e il costo totale medio per prodotto e progetto: sono dati che probabilmente userebbe un essere umano nel tentativo di prevedere la bolletta mensile. Possiamo facilmente far costruire a BigQuery una tabella di mapping che fornisca questi valori medi per progetto e prodotto, e l'abbiamo usata per creare una lookup table statica con cui arricchire i campioni.
Sono stati calcolati anche altri rapporti per fornire ulteriori informazioni alla DNN, come il costo totale lineare stimato (cioè rapporto * giorni del mese).
Ora che abbiamo i dati, alimentiamo i campioni uno per uno, insieme al valore di label associato. Addestreremo il modello a prevedere il costo totale a partire dai valori di input del campione. In questo modo potremo poi utilizzare il modello fornendogli la spesa attuale e la data per progetto e prodotto, ottenendo la previsione del costo totale a fine mese.
A dati pronti, volevamo anche un metodo per valutare il nuovo modello rispetto a quello attuale. Abbiamo usato i dati trasformati per calcolare la regressione lineare semplice eseguita oggi dal nostro codice. Per ogni campione abbiamo sottratto il totale atteso dalla previsione, elevato al quadrato il valore e poi calcolato la media su tutti i campioni. La radice quadrata di questo valore è la RMSE. Abbiamo ottenuto una RMSE di circa 900.
Osservando i dati a questo punto, era evidente che non avevano un comportamento lineare. Costruire una DNN in grado di prevedere dati di questo tipo sarebbe stato molto difficile, ma possiamo semplificarci la vita fornendo alla rete alcuni valori già calcolati che sappiamo essere rilevanti. Per farlo, oltre a trasformare i dati vogliamo arricchirli.
Una cosa che sembra utile è fornire un valore con il rapporto tra il costo attuale dall'inizio del mese e i giorni trascorsi dall'inizio del mese. Questo valore può essere mediato anche su ciascun mese e perfino a livello globale, fornendo informazioni più rilevanti sul comportamento di spesa.
E naturalmente può essere utile alla DNN conoscere lo storico del costo totale del mese precedente: aggiungiamo quindi il costo totale medio per ciascun mese e una media globale del costo totale.
Questa è la funzione di preprocessing che abbiamo realizzato:
A questo punto vogliamo impacchettare il tutto in formato TFRecord, pronto per il training. Per fortuna esiste già un pacchetto che ci aiuta a farlo. Il pacchetto Python tensorflow-transform usa una combinazione di TensorFlow e Apache Beam per elaborare grandi quantità di dati, trasformarli e scriverli in file TFRecord.
Un altro vantaggio di tensorflow-transform è che crea un grafo TensorFlow per elaborare i dati e lo esegue tramite una pipeline Beam: ciò significa che lo stesso grafo può essere riutilizzato in seguito per la previsione, eseguendo automaticamente tutte queste trasformazioni sui dati senza doverli pre-elaborare prima di darli in pasto al modello.
Al cuore dello script di preprocessing eseguiamo la pipeline Apache Beam:
La funzione get_data_from_bq legge i dati da BigQuery utilizzando la query SQL mostrata sopra.
Successivamente utilizza AnalyzeAndTransformDataset per eseguire l'elaborazione vera e propria. AnalyzeAndTransformDataset richiede una funzione di pre-processing per definire il grafo di trasformazione. I dati trasformati vengono scritti in formato TFRecord in due set di file, uno per il training e uno per il testing.
Oltre ai dati, la pipeline salva anche i metadati del modello, inclusi quelli di input grezzi, quelli dei dati trasformati e il grafo della funzione di trasformazione. Questi vengono poi utilizzati per addestrare il modello.
Training del modello
A dati pronti, il passo successivo è addestrare un modello con i dati appena preparati.
Abbiamo deciso di utilizzare una semplice DNN, addestrandola tramite la classe DNNRegressor di TensorFlow. I metadati creati da tensorflow-transform nella fase di pre-processing vengono ora usati per costruire le input function di training, testing e serving.
Infine, utilizziamo contrib.learn.Experiment di TensorFlow per coordinare training e valutazione.
Per farlo definiamo una funzione che genera l'esperimento:
E poi la usiamo per eseguirlo:
Il risultato di questo processo è una cartella con il modello salvato, che potremo poi distribuire su Google CloudML per effettuare le previsioni vere e proprie.
Deployment del modello
Per consentire a reOptimize di sfruttare le previsioni, dobbiamo ovviamente predisporre un'infrastruttura che gestisca le richieste API provenienti dall'applicazione e restituisca l'output del modello.
Google CloudML fa esattamente questo grazie a TensorFlow Serving. TensorFlow Serving utilizza un modello addestrato salvato su disco locale o in un bucket GCS per eseguire il modello e ottenerne l'output. Espone un'API RESTful utilizzabile da qualsiasi client web o mobile. Google CloudML va oltre, fornendo un'infrastruttura di serving serverless e completamente gestita per il vostro modello, così non dovete configurare macchine, gestirne l'autoscaling e così via.
Una volta addestrato e salvato il modello, lo distribuiamo tramite la riga di comando gcloud.
$ gcloud ml-engine models create reoptimize --regions=us-east1$ gsutil -m cp -r job/model/export/Servo/... <MY_GCS_BUCKET_NAME>/model/<MODEL_VERSION_NAME>$ gcloud ml-engine versions create <MODEL_VERSION_NAME> --model reoptimize --runtime-version 1.2 --origin <MY_GCS_BUCKET_NAME>/model/<MODEL_VERSION_NAME>$ gcloud ml-engine versions set-default <MODEL_VERSION_NAME> --model reoptimizeVerrà creato un URL utilizzabile per effettuare previsioni con il nostro modello. L'URL punta a un servizio API backend completamente gestito creato da Google CloudML.
Può gestire chiamate REST e può anche essere usato tramite lo strumento da riga di comando gcloud, in questo modo:
gcloud ml-engine predict --format=json --model reoptimize --json-instances=data/predict.jsonIl file data/predict.json contiene informazioni come queste:
E i risultati sarebbero più o meno questi:
In sintesi
Grazie all'adozione del machine learning per prevedere la spesa su Google Cloud Platform, le nostre previsioni sono ora molto più accurate. Tengono conto (indirettamente) di un'enorme quantità di segnali, come stagionalità, variazioni nei modelli di pricing, campagne marketing e molto altro.
La nostra RMSE è scesa da circa 900 a soli ~100: le previsioni sono quindi molto più affidabili e i nostri clienti possono contare su di esse.
Grazie a Google CloudML, Dataflow e BigQuery, siamo riusciti a implementare l'infrastruttura di machine learning di reOptimize in appena un paio di settimane, dedicando più tempo all'engineering invece che alle operations o alla manutenzione.