Como quizá ya sepas, DoiT International es la fuerza de ingeniería detrás de reOptimize (ahora parte de DoiT Cloud Intelligence™): el SaaS de descubrimiento y optimización de costos para Google Cloud Platform.
Con reOptimize obtienes insights al instante sobre tu facturación de Google Cloud Platform, gestionas presupuestos, configuras la asignación de costos y exploras distintas estrategias de optimización.
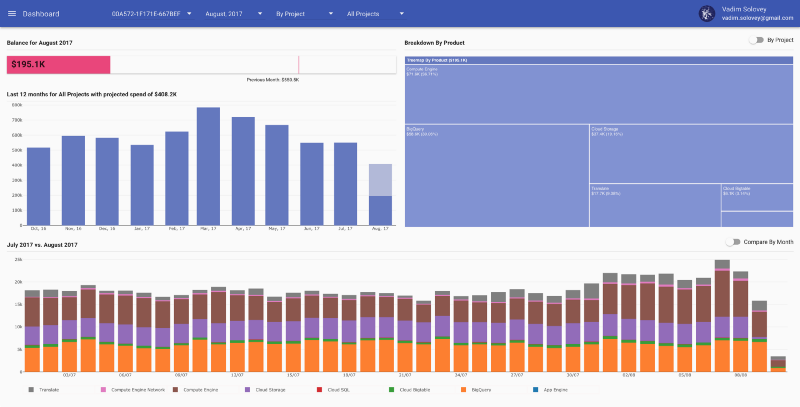
Dashboard de reOptimize
Una de las funciones que tenemos desde el día uno es la estimación de cómo se verá tu factura mensual al cierre del mes. Así se ve en el dashboard de reOptimize:
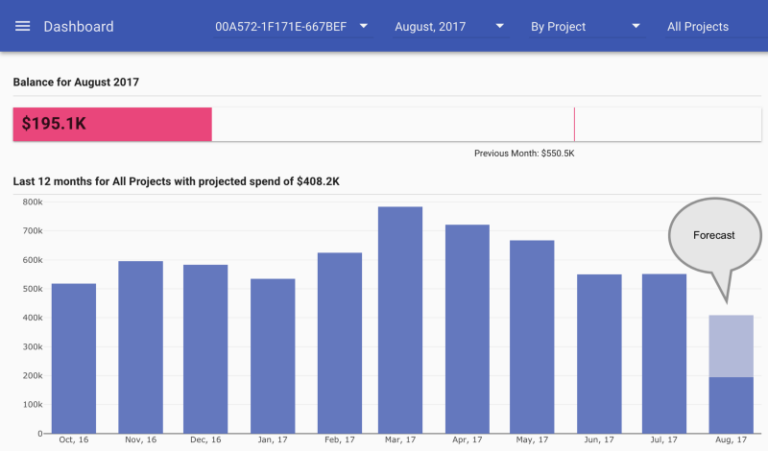
Pronóstico de facturación de Google Cloud Platform
Al inicio, nuestro modelo de estimación se basaba en una regresión lineal muy básica: tomaba el gasto actual y el día del mes, y extrapolaba el valor asumiendo un crecimiento lineal del gasto. Hicimos algunos ajustes, como tomar en cuenta los Sustained Discounts de Google Compute Engine, entre otras cosas, pero seguía siendo bastante ingenuo y simplista.
Lamentablemente, los servicios en la nube son acumulativos y, en general, el gasto en la nube no se comporta de manera lineal. Hay patrones de estacionalidad: meses más largos o cortos, temporadas de festividades, campañas de marketing y mucho más. La estimación de este modelo solía quedar bastante lejos de la realidad. Calculamos que tenía una desviación cuadrática media (RMSE) de ~900.
Como muchos de nuestros clientes confían en reOptimize para pronosticar su gasto en Google Cloud Platform, empezamos a trabajar en un modelo basado en Machine Learning para mejorar la precisión de las estimaciones.
Naturalmente, decidimos usar TensorFlow —una librería open-source de Machine Intelligence— y, en concreto, Google CloudML, el servicio gestionado de Google para TensorFlow, así nos olvidamos del escalado, el despliegue, el monitoreo y otras cargas operativas no tan fascinantes ;-)
El proyecto tiene tres partes principales:
- Preparar los datos históricos para entrenar el modelo
- Entrenar un modelo de predicción
- Desplegar el modelo para que reOptimize lo utilice
Todo esto debe ejecutarse de forma automática e iterativa, ya que cada día llegan nuevos datos de facturación.
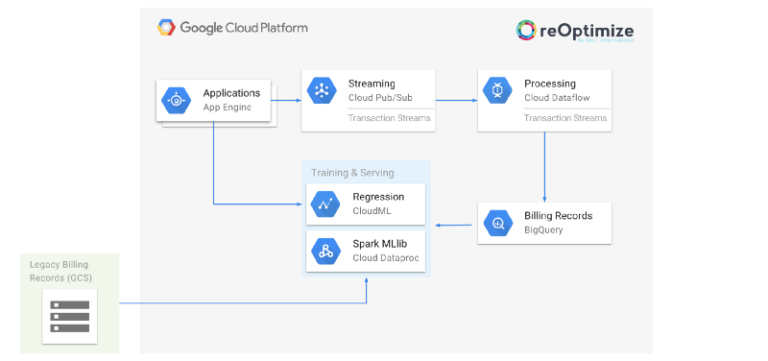
Arquitectura de predicción de reOptimize basada en Machine Learning
Preparación de los datos de entrenamiento
La API de Google Cloud Billing permite exportar registros de facturación a distintos destinos, y uno de ellos es Google BigQuery. Usamos una tabla de BigQuery como fuente de datos para entrenar el modelo de predicción.
La información de la tabla tiene las siguientes columnas:
project.id - El ID del proyecto de GCPproduct - El nombre del servicio de GCP (ej. BigQuery, Compute Engine, etc.)start_time - La fecha y hora de esta fila de facturacióncost - El costo en dólares estadounidensescredits.name - Un campo repetido con los nombres de los créditos relevantescredits.amount - Un campo repetido con el monto de los créditos relevantesPara optimizar el entrenamiento, conviene transformar los datos crudos a un formato más apto para TensorFlow. Esto incluye tanto el formato como la semántica de los datos.
TensorFlow soporta varios formatos, pero el estándar es TFRecords. Existen muchas utilidades integradas para leer y escribir datos en este formato.
La semántica de los datos también debe transformarse en valores que se ajusten mejor a una DNN. Una DNN, o Deep Neural Network, es un tipo de modelo matemático que se usa en machine learning y se construye a partir del funcionamiento del cerebro humano.
Una DNN no funciona bien con entradas que no sean números, y de preferencia números con un significado real. Por ejemplo, los nombres de productos y proyectos no significan nada por sí solos, lo mismo que los valores de año y mes. En cambio, el valor numérico del día sí tiene significado, igual que el costo. Tampoco resultaría productivo alimentar las filas de costo en crudo, ya que necesitamos un valor objetivo por muestra.
Por eso transformamos los datos de BigQuery en algo más adecuado para nuestro modelo DNN.
La mejor forma que encontramos de definir las muestras es crear una agregación diaria por producto y proyecto, junto con la suma de los costos desde el inicio del mes hasta ese día. También hay que sumar el costo total del producto y proyecto en ese mes y usarlo como valor objetivo para el entrenamiento. Por último, los nombres de producto y proyecto deben mapearse primero a enteros.
En nuestro caso, cada muestra incluye el proyecto, el producto, el día, el costo parcial (desde el inicio del mes) y el costo total. Para que la DNN pueda entender los datos, queremos enriquecer la muestra con información adicional que pueda ser útil pero difícil de calcular para la DNN por su cuenta.
El número de días del mes actual es una constante arbitraria que puede afectar el costo total. Podemos "calcular" esto para la DNN y así ahorrar tiempo y complejidad. También podemos calcular la razón de costo por día dividiendo el costo parcial entre el día actual.
Otro valor útil sería la razón media y el costo total medio por producto y proyecto: son los valores que probablemente usaría una persona al intentar pronosticar la factura mensual. Es fácil pedirle a BigQuery que arme una tabla de mapeo con estos valores medios por proyecto y producto, y usamos esa tabla para crear una tabla de búsqueda estática con la cual enriquecer las muestras.
También calculamos otras razones para darle más información a la DNN, como el costo total lineal estimado (es decir, razón * días del mes).
Con los datos listos, alimentamos las muestras una por una junto con el valor de etiqueta de cada una. Entrenamos el modelo para que prediga el costo total a partir de los valores de entrada de la muestra. Así, después podemos pasarle al modelo el gasto y la fecha actuales por proyecto y producto, y predecir el costo total al cierre del mes.
Ya con los datos preparados, queríamos una forma de evaluar el modelo frente a lo que tenemos hoy. Usamos los datos transformados para calcular la regresión lineal simple que ejecuta nuestro código actual. Calculamos cada muestra, restamos el total esperado a la predicción, elevamos el valor al cuadrado y luego sacamos un promedio para todas las muestras. La raíz cuadrada de ese valor es el RMSE. Obtuvimos un RMSE de ~900.
Al ver los datos en esta etapa, era evidente que no se comportaban de forma lineal. Crear una DNN capaz de predecir esos datos sería muy difícil, pero sí podemos ayudar a construir una DNN más sencilla alimentando la red con valores calculados que ya sabemos que son relevantes. Para eso, además de transformar los datos, queremos enriquecerlos.
Algo que parece útil es alimentarla con la razón entre el costo actual desde el inicio del mes y los días transcurridos desde el inicio del mes. Este valor también puede promediarse por mes e incluso de forma global, para entregar más información sobre el comportamiento del gasto.
Y, por supuesto, a la DNN le puede ayudar conocer el historial del costo total del mes anterior, así que agregamos el costo total promedio por mes y un promedio global del costo total.
Esta es la función de preprocesamiento que construimos:
Después queremos empaquetarlo todo en formato TFRecord, listo para entrenar. Por suerte, ya existe un paquete que ayuda con eso. El paquete de Python tensorflow-transform combina TensorFlow y Apache Beam para procesar grandes volúmenes de datos, transformarlos y escribirlos en archivos TFRecord.
Otra ventaja de tensorflow-transform es que crea un grafo de TensorFlow para procesar los datos y lo ejecuta a través de un pipeline de Beam, lo que te permite reutilizar ese mismo grafo más adelante para la predicción, haciendo todas las transformaciones por ti, sin necesidad de transformar los datos antes de pasarlos al modelo.
En el corazón del script de preprocesamiento se ejecuta el pipeline de Apache Beam:
La función get_data_from_bq lee los datos de BigQuery con la consulta SQL mostrada arriba.
Luego usa AnalyzeAndTransformDataset para hacer el procesamiento. AnalyzeAndTransformDataset necesita una función de preprocesamiento que defina el grafo de transformación. Los datos transformados se escriben en formato TFRecord en dos conjuntos de archivos: uno para entrenamiento y otro para prueba.
Además de los datos, el pipeline también guarda los metadatos del modelo, incluidos los metadatos de entrada en crudo, los de los datos transformados y el grafo de la función de transformación. Estos se usan después para entrenar el modelo.
Entrenamiento del modelo
Con los datos listos, el siguiente paso es entrenar un modelo con los datos que acabamos de preparar.
Decidimos usar una DNN sencilla y entrenarla con la clase DNNRegressor de TensorFlow. Los metadatos creados por tensorflow-transform en el paso de preprocesamiento se usan ahora para crear las funciones de entrada para entrenamiento, prueba y serving.
Por último, usamos contrib.learn.Experiment de TensorFlow para coordinar el entrenamiento y la evaluación.
Para esto definimos una función que genera el experimento:
Y luego la usamos para ejecutarlo:
El resultado de este proceso es una carpeta con el modelo guardado, que después podemos desplegar en Google CloudML para hacer las predicciones reales.
Despliegue del modelo
Para que reOptimize pueda usar las predicciones, obviamente hay que crear cierta infraestructura que atienda las solicitudes de la API que llegan desde la aplicación y devuelva la salida del modelo.
Google CloudML hace exactamente eso con TensorFlow Serving. TensorFlow Serving toma un modelo entrenado guardado en disco local o en un bucket de GCS para ejecutarlo y obtener la salida. Expone una API RESTful que cualquier cliente web o móvil puede consumir. Google CloudML va un paso más allá al ofrecer una infraestructura de serving serverless y totalmente gestionada para tu modelo, así no tienes que configurar máquinas, autoescalarlas, etc.
Una vez entrenado y guardado el modelo, lo desplegamos con la línea de comandos gcloud.
$ gcloud ml-engine models create reoptimize --regions=us-east1$ gsutil -m cp -r job/model/export/Servo/... <MY_GCS_BUCKET_NAME>/model/<MODEL_VERSION_NAME>$ gcloud ml-engine versions create <MODEL_VERSION_NAME> --model reoptimize --runtime-version 1.2 --origin <MY_GCS_BUCKET_NAME>/model/<MODEL_VERSION_NAME>$ gcloud ml-engine versions set-default <MODEL_VERSION_NAME> --model reoptimizeEsto crea una URL que se puede usar para hacer predicciones con el modelo. La URL apunta a un servicio de API backend totalmente gestionado por Google CloudML.
Puede atender llamadas REST y también usarse desde la herramienta de línea de comandos gcloud, así:
gcloud ml-engine predict --format=json --model reoptimize --json-instances=data/predict.jsonEl archivo data/predict.json contiene información como esta:
Y los resultados serían algo así:
Resumen
Al implementar machine learning para predecir las facturas de Google Cloud Platform, los pronósticos son ahora mucho más precisos. Toman en cuenta (de forma indirecta) una enorme cantidad de señales: estacionalidad, cambios en los modelos de precios, campañas de marketing, etc.
El RMSE bajó de ~900 a apenas ~100, así que las predicciones son mucho más confiables y nuestros clientes pueden apoyarse en ellas.
Con Google CloudML, Dataflow y BigQuery pudimos implementar la infraestructura de machine learning de reOptimize en apenas un par de semanas, dedicando más tiempo a la ingeniería que a operaciones o mantenimiento.