Comme certains d'entre vous le savent déjà, DoiT International est la force d'ingénierie derrière reOptimize (désormais intégré à DoiT Cloud Intelligence™) — le SaaS d'analyse et d'optimisation des coûts pour Google Cloud Platform.
Avec reOptimize, obtenez une visibilité immédiate sur votre facturation Google Cloud Platform, pilotez vos budgets, configurez vos allocations de coûts et explorez différentes stratégies d'optimisation.
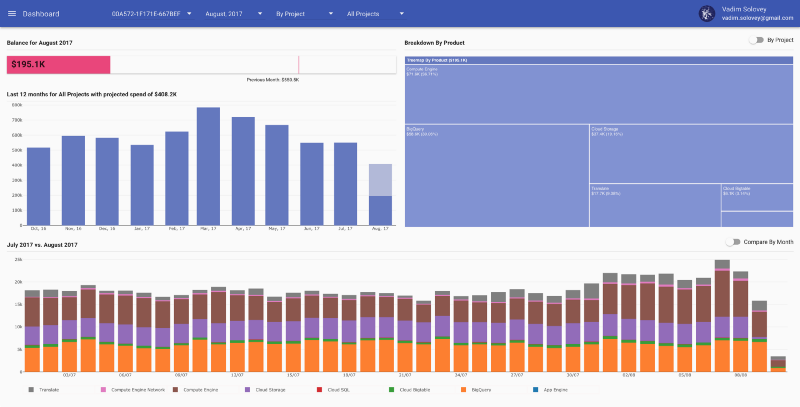
Dashboard reOptimize
L'une des fonctionnalités présentes dès le premier jour est l'estimation du montant final de votre facture mensuelle. Voici à quoi cela ressemble dans le dashboard reOptimize :
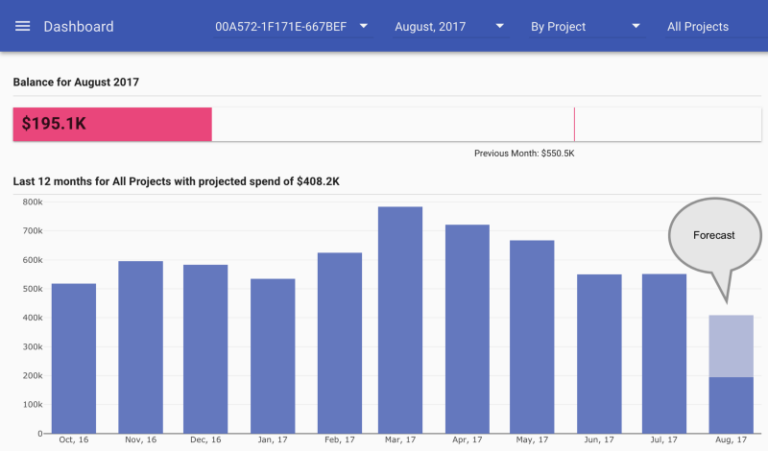
Prévision de facturation Google Cloud Platform
À l'origine, notre modèle d'estimation reposait sur une régression linéaire très basique : il prenait la dépense actuelle et le jour du mois, puis extrapolait la valeur en supposant une croissance linéaire. Nous avions apporté quelques ajustements, comme la prise en compte des Sustained Discounts de Google Compute Engine et de quelques autres détails, mais le modèle restait naïf et simpliste.
Malheureusement, les services cloud sont cumulatifs et, de manière générale, les dépenses cloud n'évoluent pas du tout de façon linéaire. Il existe des effets de saisonnalité : mois plus longs ou plus courts, périodes de vacances, campagnes marketing, et bien d'autres encore. L'estimation produite par ce modèle s'avérait souvent assez éloignée de la réalité. Nous avions calculé un écart quadratique moyen (RMSE) d'environ 900.
Bon nombre de nos clients s'appuyant sur reOptimize pour anticiper leurs dépenses Google Cloud Platform, nous avons entrepris de développer un modèle basé sur le Machine Learning afin d'améliorer la précision de nos estimations.
Naturellement, nous avons opté pour TensorFlow — une bibliothèque logicielle open source dédiée à l'intelligence artificielle — et plus précisément pour Google CloudML, le service managé de Google pour TensorFlow, afin de nous épargner la mise à l'échelle, le déploiement, la supervision et autres charges opérationnelles peu passionnantes ;-)
Notre projet s'articule autour de trois grandes étapes :
- Préparer les données historiques pour entraîner notre modèle
- Entraîner un modèle de prédiction
- Déployer le modèle pour qu'il soit utilisé par reOptimize
L'ensemble doit être exécuté automatiquement et de façon itérative, à mesure que de nouvelles données de facturation arrivent chaque jour.
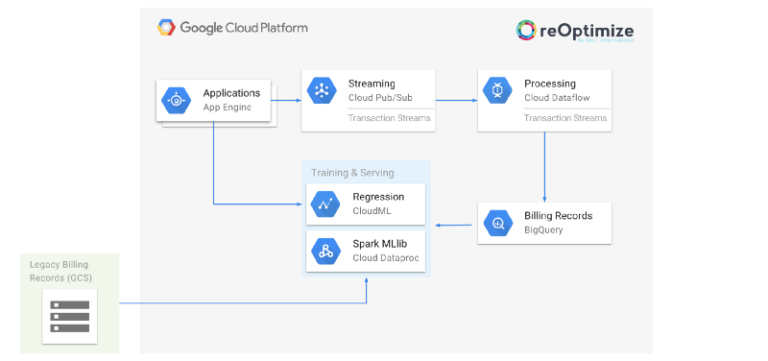
Architecture de prédiction reOptimize basée sur le Machine Learning
Préparation des données d'entraînement
L'API Google Cloud Billing permet d'exporter les enregistrements de facturation vers diverses destinations, dont Google BigQuery. Nous nous appuyons sur une table BigQuery comme source de données pour entraîner notre modèle de prédiction.
La table contient les colonnes suivantes :
project.id - L'ID du projet GCPproduct - Le nom du service GCP (ex. BigQuery, Compute Engine, etc.)start_time - La date et l'heure de cette ligne de facturationcost - Le coût en dollars américainscredits.name - Un champ répété contenant les noms des crédits applicablescredits.amount - Un champ répété contenant le montant des crédits applicablesPour optimiser l'entraînement, nous voulons transformer les données brutes dans un format mieux adapté à TensorFlow. Cela concerne aussi bien le format que la sémantique des données.
TensorFlow prend en charge plusieurs formats, mais le format standard s'appelle TFRecords. De nombreux utilitaires intégrés permettent d'y lire et d'y écrire des données.
La sémantique des données doit elle aussi être convertie en valeurs adaptées à un DNN. Le DNN, ou Deep Neural Network, est un type de modèle mathématique utilisé en machine learning, conçu sur le principe du fonctionnement du cerveau humain.
Un DNN ne fonctionne pas bien avec des entrées non numériques, et idéalement avec des nombres porteurs d'un sens réel. Par exemple, les noms de produits et de projets n'ont pas vraiment de signification en eux-mêmes, pas plus que les valeurs d'année ou de mois. En revanche, la valeur numérique du jour en a un, tout comme le coût. Par ailleurs, alimenter le modèle avec les lignes de coût brutes ne serait pas productif, car nous devons fournir une valeur cible par échantillon.
Nous transformons donc les données issues de BigQuery en une forme mieux adaptée à notre modèle DNN.
La meilleure façon de définir nos échantillons consiste à créer une agrégation quotidienne par produit et par projet, avec la somme des coûts depuis le début du mois jusqu'à ce jour. Il faut également ajouter le coût total pour ce produit et ce projet sur le mois en cours, et l'utiliser comme valeur cible pour l'entraînement. Enfin, les noms de produits et de projets doivent être préalablement convertis en entiers.
Dans notre cas, chaque échantillon comprend le projet, le produit, le jour, le coût partiel (depuis le début du mois) et le coût total. Pour aider le DNN à comprendre les données, nous voulons enrichir l'échantillon avec des informations supplémentaires potentiellement utiles, mais difficiles à calculer pour le DNN par lui-même.
Le nombre de jours dans le mois en cours est une constante arbitraire qui peut influer sur le coût total. Nous pouvons calculer cette valeur pour le DNN, ce qui fait gagner du temps et réduit la complexité. Nous pouvons aussi calculer le ratio coût par jour en divisant le coût partiel par le jour en cours.
Une autre valeur utile est le ratio moyen et le coût total moyen par produit et par projet — ce sont précisément les valeurs qu'utiliserait un humain pour prévoir la facture mensuelle. BigQuery peut facilement nous construire une table de correspondance fournissant ces valeurs moyennes par projet et par produit ; nous l'avons utilisée pour créer une table de référence statique servant à enrichir les échantillons.
D'autres ratios ont également été calculés afin de fournir au DNN davantage d'informations exploitables, comme le coût total linéaire estimé (c.-à-d. ratio * jours du mois).
Une fois les données prêtes, nous alimentons les échantillons un par un, accompagnés de leur valeur cible. Le modèle est entraîné à prédire le coût total à partir des valeurs d'entrée de l'échantillon. Plus tard, nous pourrons ainsi lui fournir la dépense actuelle et la date par projet et par produit, et obtenir le coût total prévu en fin de mois.
Nous voulions aussi pouvoir évaluer notre modèle face à l'existant. Nous avons utilisé les données transformées pour calculer la régression linéaire simple effectuée aujourd'hui par notre code. Pour chaque échantillon, nous avons soustrait le total attendu de la prédiction, élevé la valeur au carré, puis calculé la moyenne sur l'ensemble des échantillons. La racine carrée de cette valeur est le RMSE. Nous avons obtenu un RMSE d'environ 900.
À ce stade, il était évident que les données ne suivaient aucun comportement linéaire. Construire un DNN capable de prédire de telles données serait très difficile — mais nous pouvons faciliter la tâche d'un DNN plus simple en l'alimentant avec des valeurs calculées dont nous savons déjà qu'elles sont pertinentes. Pour cela, nous voulons à la fois enrichir et transformer les données.
Une piste utile consiste à fournir le ratio entre le coût actuel depuis le début du mois et le nombre de jours écoulés depuis cette date. Cette valeur peut également être moyennée par mois, voire globalement, pour fournir des informations plus pertinentes sur les comportements de dépense.
Et bien sûr, il peut être utile au DNN de connaître l'historique du coût total du mois précédent ; nous ajoutons donc le coût total moyen par mois ainsi qu'une moyenne globale du coût total.
Voici la fonction de prétraitement que nous avons construite :
Nous voulons ensuite tout regrouper au format TFRecord, prêt pour l'entraînement. Heureusement, un package existe déjà pour nous y aider. Le package Python tensorflow-transform combine TensorFlow et Apache Beam pour traiter de gros volumes de données, les transformer et les écrire dans des fichiers TFRecord.
Autre avantage de tensorflow-transform : il crée un graphe TensorFlow qui traite les données et les exécute dans un pipeline Beam — ce qui signifie que vous pouvez réutiliser ce graphe ultérieurement pour la prédiction. Toutes ces transformations sont effectuées automatiquement, ce qui vous évite d'avoir à transformer les données avant de les soumettre au modèle.
Au cœur du script de prétraitement, nous exécutons le pipeline Apache Beam :
La fonction get_data_from_bq lit les données BigQuery via la requête SQL présentée plus haut.
Elle utilise ensuite AnalyzeAndTransformDataset pour effectuer le traitement. AnalyzeAndTransformDataset nécessite une fonction de prétraitement pour définir le graphe de transformation. Les données transformées sont écrites au format TFRecord dans deux jeux de fichiers, l'un pour l'entraînement et l'autre pour les tests.
En complément des données, le pipeline enregistre également les métadonnées du modèle : métadonnées d'entrée brutes, métadonnées des données transformées et graphe de la fonction de transformation. Ces éléments serviront ensuite à entraîner le modèle.
Entraînement du modèle
Une fois les données prêtes, l'étape suivante consiste à entraîner un modèle avec ce que nous venons de préparer.
Nous avons opté pour un DNN simple, entraîné via la classe DNNRegressor de TensorFlow. Les métadonnées créées par tensorflow-transform à l'étape de prétraitement servent désormais à créer les fonctions d'entrée pour l'entraînement, les tests et le serving.
Enfin, nous utilisons contrib.learn.Experiment de TensorFlow pour coordonner l'entraînement et l'évaluation.
Pour cela, nous définissons une fonction qui génère l'expérience :
Puis nous l'utilisons pour la lancer :
Le résultat est un dossier contenant le modèle sauvegardé, que nous pourrons ensuite déployer sur Google CloudML pour réaliser de véritables prédictions.
Déploiement du modèle
Pour que reOptimize puisse exploiter les prédictions, il faut bien sûr mettre en place une infrastructure capable de servir les requêtes API émises par l'application et de renvoyer les résultats du modèle.
C'est précisément ce que fait Google CloudML grâce à TensorFlow Serving. TensorFlow Serving s'appuie sur un modèle entraîné, sauvegardé sur disque local ou dans un bucket GCS, pour exécuter le modèle et en récupérer les résultats. Il expose une API RESTful utilisable depuis n'importe quel client web ou mobile. Google CloudML va plus loin en fournissant une infrastructure de serving serverless et entièrement managée pour votre modèle, ce qui vous évite de configurer des machines, de les autoscaler, etc.
Une fois notre modèle entraîné et sauvegardé, nous le déployons via la ligne de commande gcloud.
$ gcloud ml-engine models create reoptimize --regions=us-east1$ gsutil -m cp -r job/model/export/Servo/... <MY_GCS_BUCKET_NAME>/model/<MODEL_VERSION_NAME>$ gcloud ml-engine versions create <MODEL_VERSION_NAME> --model reoptimize --runtime-version 1.2 --origin <MY_GCS_BUCKET_NAME>/model/<MODEL_VERSION_NAME>$ gcloud ml-engine versions set-default <MODEL_VERSION_NAME> --model reoptimizeCela génère une URL utilisable pour effectuer des prédictions avec notre modèle. Cette URL pointe vers un service d'API backend entièrement managé par Google CloudML.
Elle peut traiter des appels REST et être également utilisée depuis l'outil en ligne de commande gcloud, comme ceci :
gcloud ml-engine predict --format=json --model reoptimize --json-instances=data/predict.jsonLe fichier data/predict.json contient des informations comme celles-ci :
Et les résultats ressemblent à ceci :
Synthèse
En appliquant le machine learning à la prédiction des factures Google Cloud Platform, nos prévisions sont désormais bien plus précises. Elles intègrent (indirectement) une multitude de signaux : saisonnalité, évolutions des modèles tarifaires, campagnes marketing, etc.
Notre RMSE est passé d'environ 900 à seulement 100 ; nos prédictions gagnent ainsi en crédibilité et nos clients peuvent s'y fier.
Grâce à Google CloudML, Dataflow et BigQuery, nous avons pu déployer l'infrastructure de machine learning de reOptimize en quelques semaines à peine, en consacrant davantage de temps à l'ingénierie qu'aux opérations ou à la maintenance.